



Sumedh Hindupur
@sumedh-hindupur.bsky.social
Grad Student at Harvard SEAS
Interested in ML Interpretability, Computational Neuroscience, Signal Processing
Interested in ML Interpretability, Computational Neuroscience, Signal Processing
New preprint alert!
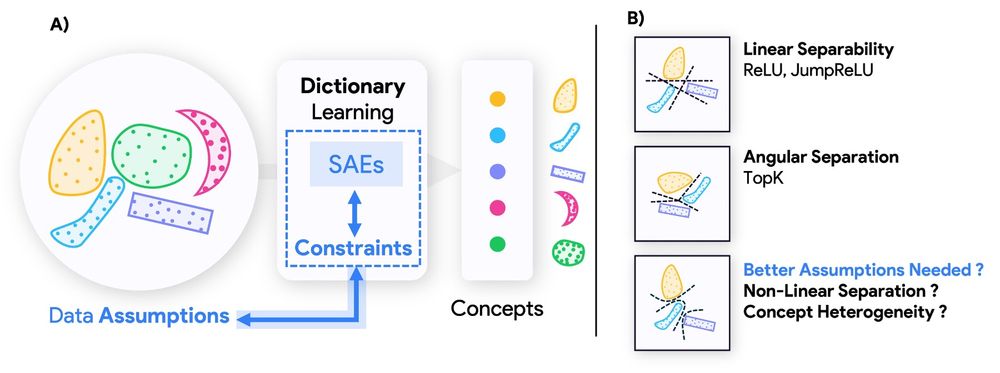
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
March 7, 2025 at 2:48 AM
New preprint alert!
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822
Do Sparse Autoencoders (SAEs) reveal all concepts a model relies on? Or do they impose hidden biases that shape what we can even detect?
We uncover a fundamental duality between SAE architectures and concepts they can recover.
Link: arxiv.org/abs/2503.01822