Declan Campbell
@thisisadax.bsky.social
340 followers
88 following
8 posts
Cognitive neuroscience. Deep learning. PhD Student at Princeton Neuroscience with @cocoscilab.bsky.social and Cohen Lab. Student Researcher at Google DeepMind.
Posts
Media
Videos
Starter Packs
Reposted by Declan Campbell

Zhenglong Zhou
@neurozz.bsky.social
· Jul 16

A gradient of complementary learning systems emerges through meta-learning
Long-term learning and memory in the primate brain rely on a series of hierarchically organized subsystems extending from early sensory neocortical areas to the hippocampus. The components differ in t...
bit.ly
Reposted by Declan Campbell

Taylor Webb
@taylorwwebb.bsky.social
· Mar 10

Emergent Symbolic Mechanisms Support Abstract Reasoning in Large Language Models
Many recent studies have found evidence for emergent reasoning capabilities in large language models, but debate persists concerning the robustness of these capabilities, and the extent to which they ...
arxiv.org
Reposted by Declan Campbell

Andrew Lampinen
@lampinen.bsky.social
· Dec 10

The broader spectrum of in-context learning
The ability of language models to learn a task from a few examples in context has generated substantial interest. Here, we provide a perspective that situates this type of supervised few-shot learning...
arxiv.org

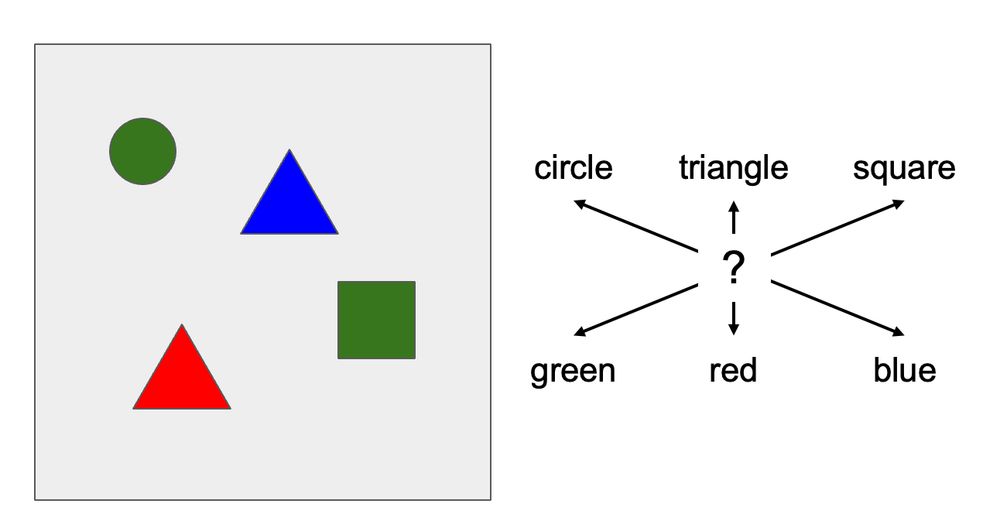
Declan Campbell
@thisisadax.bsky.social
· Nov 15
Declan Campbell
@thisisadax.bsky.social
· Nov 15