




Thomas Davidson
@thomasdavidson.bsky.social
Sociologist at Rutgers. Studies far-right politics, populism, and hate speech. Computational social science.
https://www.thomasrdavidson.com/
https://www.thomasrdavidson.com/
First 50 downloads are free if you use this link: www.tandfonline.com/eprint/AYC6H...


February 3, 2026 at 3:08 PM
First 50 downloads are free if you use this link: www.tandfonline.com/eprint/AYC6H...
On the topic of AI and social science research, the Research Briefing on my Nature Human Behaviour paper is now online. It's an accessible summary of the research, implications, and some behind-the-scenes commentary.
Thanks @gligoric.bsky.social for providing an expert opinion!
Thanks @gligoric.bsky.social for providing an expert opinion!


January 6, 2026 at 9:06 PM
On the topic of AI and social science research, the Research Briefing on my Nature Human Behaviour paper is now online. It's an accessible summary of the research, implications, and some behind-the-scenes commentary.
Thanks @gligoric.bsky.social for providing an expert opinion!
Thanks @gligoric.bsky.social for providing an expert opinion!
Additionally, some models are overtly biased and are particularly sensitive to visual identity cues (AI-generated profile pictures). This demonstrates how different data modalities lead to varying levels of algorithmic bias.

December 15, 2025 at 3:04 PM
Additionally, some models are overtly biased and are particularly sensitive to visual identity cues (AI-generated profile pictures). This demonstrates how different data modalities lead to varying levels of algorithmic bias.
When considering the identity of the author, some MLLMs make context-sensitive judgments comparable to human subjects. e.g., less likely to flag Black users for using reclaimed slurs, a common false positive. But the results also reveal less normative decisions regarding so-called "reverse racism".

December 15, 2025 at 3:04 PM
When considering the identity of the author, some MLLMs make context-sensitive judgments comparable to human subjects. e.g., less likely to flag Black users for using reclaimed slurs, a common false positive. But the results also reveal less normative decisions regarding so-called "reverse racism".
I find that MLLMs follow a consistent hierarchy of offensive language to humans and show similarities across other attributes. There is heterogeneity across models, particularly the smallest open-weights versions.


December 15, 2025 at 3:04 PM
I find that MLLMs follow a consistent hierarchy of offensive language to humans and show similarities across other attributes. There is heterogeneity across models, particularly the smallest open-weights versions.
New paper in Nature Human Behaviour.
I use a conjoint experiment to test multimodal large language models (MLLMs) for context-sensitive content moderation and compare with human subjects. Methodologically, this demonstrates how social science techniques can enhance AI auditing. 💻🤖💬
I use a conjoint experiment to test multimodal large language models (MLLMs) for context-sensitive content moderation and compare with human subjects. Methodologically, this demonstrates how social science techniques can enhance AI auditing. 💻🤖💬

December 15, 2025 at 3:04 PM
New paper in Nature Human Behaviour.
I use a conjoint experiment to test multimodal large language models (MLLMs) for context-sensitive content moderation and compare with human subjects. Methodologically, this demonstrates how social science techniques can enhance AI auditing. 💻🤖💬
I use a conjoint experiment to test multimodal large language models (MLLMs) for context-sensitive content moderation and compare with human subjects. Methodologically, this demonstrates how social science techniques can enhance AI auditing. 💻🤖💬
Big professional news!

September 22, 2025 at 8:19 PM
Big professional news!
Analysis of the reasoning traces for Gemini 2.5 shows that the model identifies second-order factors when faced with these decisions, helping to address common false positives like flagging reclaimed slurs as hate speech (Warning: offensive language in example)

September 9, 2025 at 4:00 PM
Analysis of the reasoning traces for Gemini 2.5 shows that the model identifies second-order factors when faced with these decisions, helping to address common false positives like flagging reclaimed slurs as hate speech (Warning: offensive language in example)
On a content moderation task, humans take longer and LRMs use more tokens when offensiveness is identical or fixed.
This suggests that LRM behavior is consistent with dual process theories of cognition, as the models expend more reasoning effort when simple heuristics are insufficient
This suggests that LRM behavior is consistent with dual process theories of cognition, as the models expend more reasoning effort when simple heuristics are insufficient

September 9, 2025 at 4:00 PM
On a content moderation task, humans take longer and LRMs use more tokens when offensiveness is identical or fixed.
This suggests that LRM behavior is consistent with dual process theories of cognition, as the models expend more reasoning effort when simple heuristics are insufficient
This suggests that LRM behavior is consistent with dual process theories of cognition, as the models expend more reasoning effort when simple heuristics are insufficient
The results are consistent across three frontier LRMs: o3, Gemini 2.5 Pro, and Grok 4

September 9, 2025 at 4:00 PM
The results are consistent across three frontier LRMs: o3, Gemini 2.5 Pro, and Grok 4
New pre-print on large reasoning models 🤖🧠
To what extent does LRM behavior resemble human reasoning processes?
I find that LRM reasoning effort predicts human decision time on a pairwise comparison task, and both humans and LRMs require more time/effort on challenging tasks
To what extent does LRM behavior resemble human reasoning processes?
I find that LRM reasoning effort predicts human decision time on a pairwise comparison task, and both humans and LRMs require more time/effort on challenging tasks

September 9, 2025 at 4:00 PM
New pre-print on large reasoning models 🤖🧠
To what extent does LRM behavior resemble human reasoning processes?
I find that LRM reasoning effort predicts human decision time on a pairwise comparison task, and both humans and LRMs require more time/effort on challenging tasks
To what extent does LRM behavior resemble human reasoning processes?
I find that LRM reasoning effort predicts human decision time on a pairwise comparison task, and both humans and LRMs require more time/effort on challenging tasks
If you want to learn more about these articles, check out our editors’ introduction, where we provide an overview and discuss some central themes.
One point we emphasize is how the model ecosystem has matured & open-weight models are viable for many problems journals.sagepub.com/doi/10.1177/...
One point we emphasize is how the model ecosystem has matured & open-weight models are viable for many problems journals.sagepub.com/doi/10.1177/...
August 1, 2025 at 2:54 PM
If you want to learn more about these articles, check out our editors’ introduction, where we provide an overview and discuss some central themes.
One point we emphasize is how the model ecosystem has matured & open-weight models are viable for many problems journals.sagepub.com/doi/10.1177/...
One point we emphasize is how the model ecosystem has matured & open-weight models are viable for many problems journals.sagepub.com/doi/10.1177/...
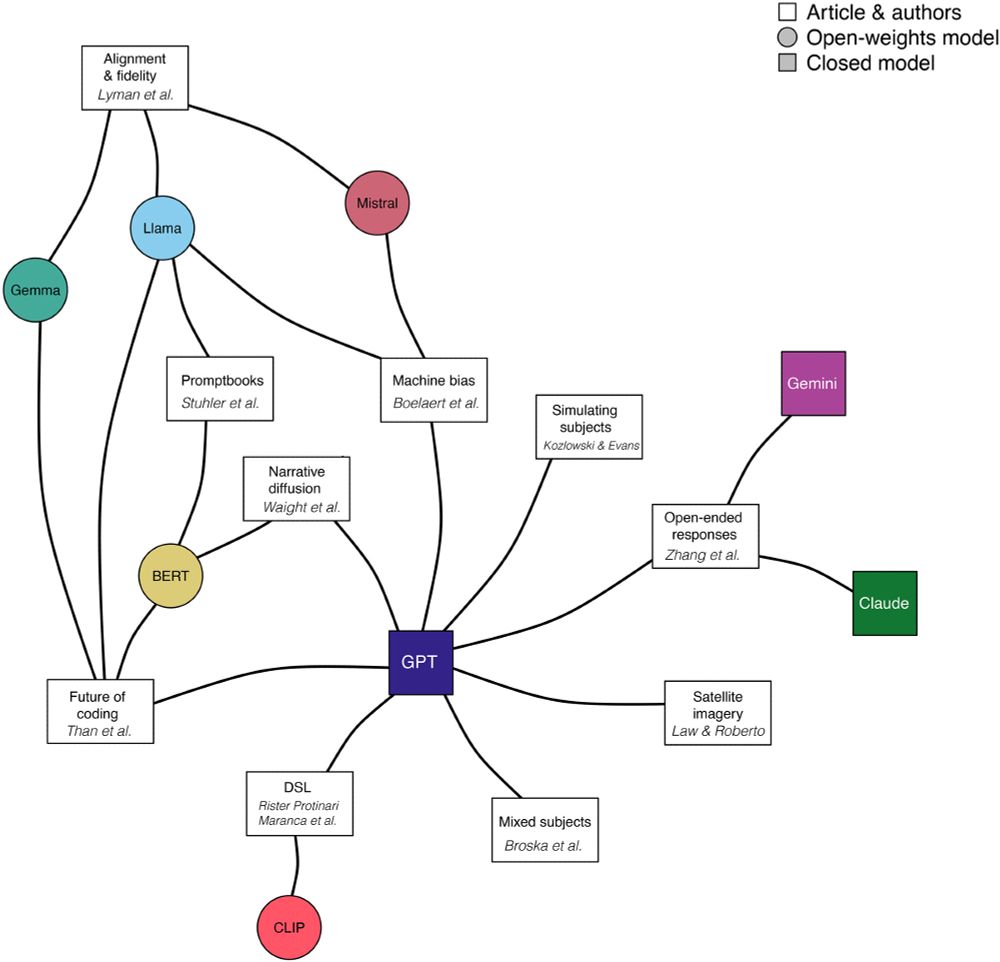
Stuhler, Ton, and Ollion show how LLMs enable more complex information extraction tasks that can be applied to text corpora, with an application to the study of obituaries journals.sagepub.com/doi/abs/10.1...

August 1, 2025 at 2:54 PM
Stuhler, Ton, and Ollion show how LLMs enable more complex information extraction tasks that can be applied to text corpora, with an application to the study of obituaries journals.sagepub.com/doi/abs/10.1...
A study by Than et al. revisits an earlier SMR paper, exploring how LLMs can be used for qualitative coding tasks, providing detailed guidance on how to approach the problem journals.sagepub.com/doi/full/10....
August 1, 2025 at 2:54 PM
A study by Than et al. revisits an earlier SMR paper, exploring how LLMs can be used for qualitative coding tasks, providing detailed guidance on how to approach the problem journals.sagepub.com/doi/full/10....
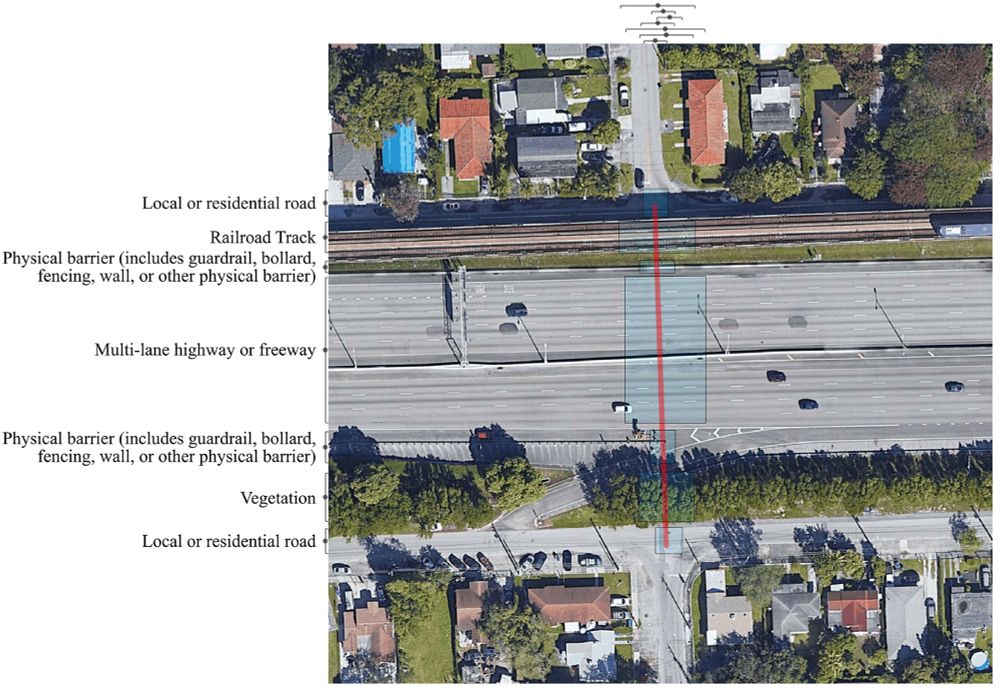
Law and Roberto showcase how vision language models like GPT-4o can extract information from satellite images, applying these techniques to study segregation in the built environment journals.sagepub.com/doi/full/10....
August 1, 2025 at 2:54 PM
Law and Roberto showcase how vision language models like GPT-4o can extract information from satellite images, applying these techniques to study segregation in the built environment journals.sagepub.com/doi/full/10....
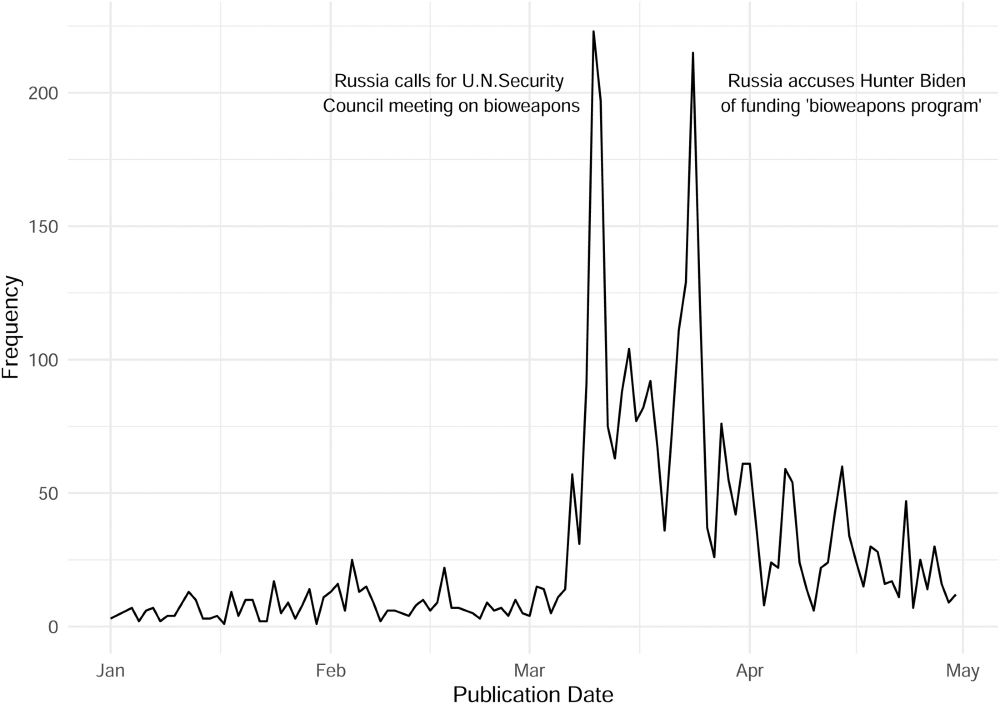
Waight and colleagues develop a pipeline for quantifying narrative similarity, combining the latest frontier LLMs with earlier techniques to study Russian influence campaigns journals.sagepub.com/doi/abs/10.1...
August 1, 2025 at 2:54 PM
Waight and colleagues develop a pipeline for quantifying narrative similarity, combining the latest frontier LLMs with earlier techniques to study Russian influence campaigns journals.sagepub.com/doi/abs/10.1...
Maranca and colleagues show the importance of statistical corrections when using predictions from multimodal LLMs and other computer vison models for downstream tasks, providing several applications journals.sagepub.com/doi/abs/10.1...

August 1, 2025 at 2:54 PM
Maranca and colleagues show the importance of statistical corrections when using predictions from multimodal LLMs and other computer vison models for downstream tasks, providing several applications journals.sagepub.com/doi/abs/10.1...
Kozlowski and Evans synthesize work using generative AI for simulation, giving us an in-depth view into how AI models work and how scholars are addressing six challenging issues journals.sagepub.com/doi/abs/10.1...
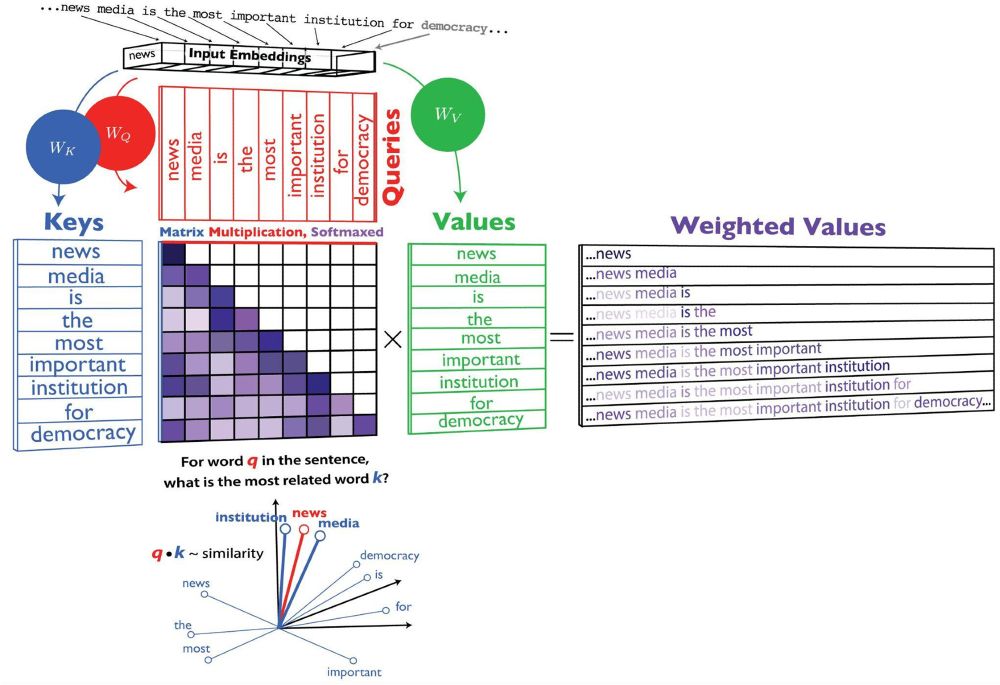
August 1, 2025 at 2:54 PM
Kozlowski and Evans synthesize work using generative AI for simulation, giving us an in-depth view into how AI models work and how scholars are addressing six challenging issues journals.sagepub.com/doi/abs/10.1...
Broska, Howes, and van Loon propose the mixed-subjects approach, providing a methodology for combining estimates from human subjects and silicon samples journals.sagepub.com/doi/abs/10.1...
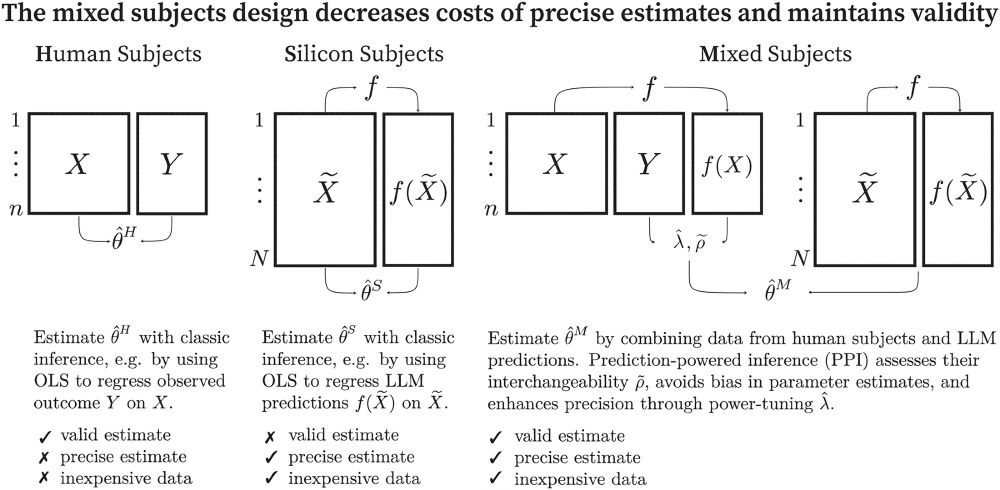
August 1, 2025 at 2:54 PM
Broska, Howes, and van Loon propose the mixed-subjects approach, providing a methodology for combining estimates from human subjects and silicon samples journals.sagepub.com/doi/abs/10.1...
Lyman and colleagues explore the trade-offs between using instruction-tuned models and base versions of LLMs for downstream tasks, emphasizing the need to better understand model training journals.sagepub.com/doi/abs/10.1...
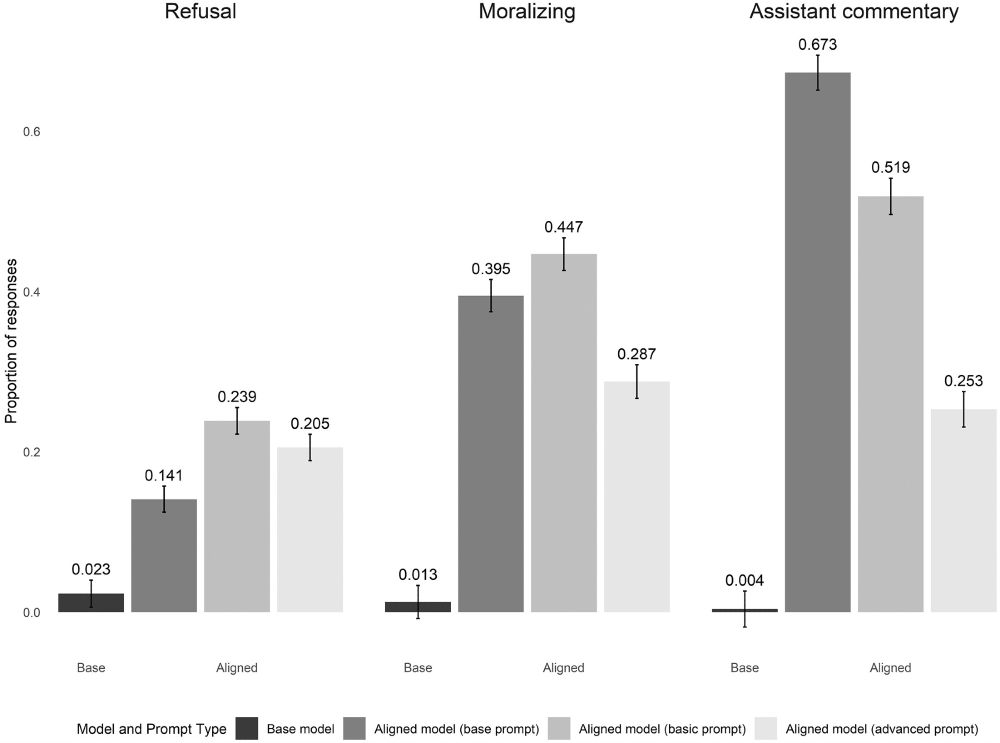
August 1, 2025 at 2:54 PM
Lyman and colleagues explore the trade-offs between using instruction-tuned models and base versions of LLMs for downstream tasks, emphasizing the need to better understand model training journals.sagepub.com/doi/abs/10.1...
Boelaert and colleagues pose a challenge to work that uses LLMs as substitutes for humans in surveys, finding that AI models exhibit idiosyncratic biases they term “machine bias” journals.sagepub.com/doi/abs/10.1...
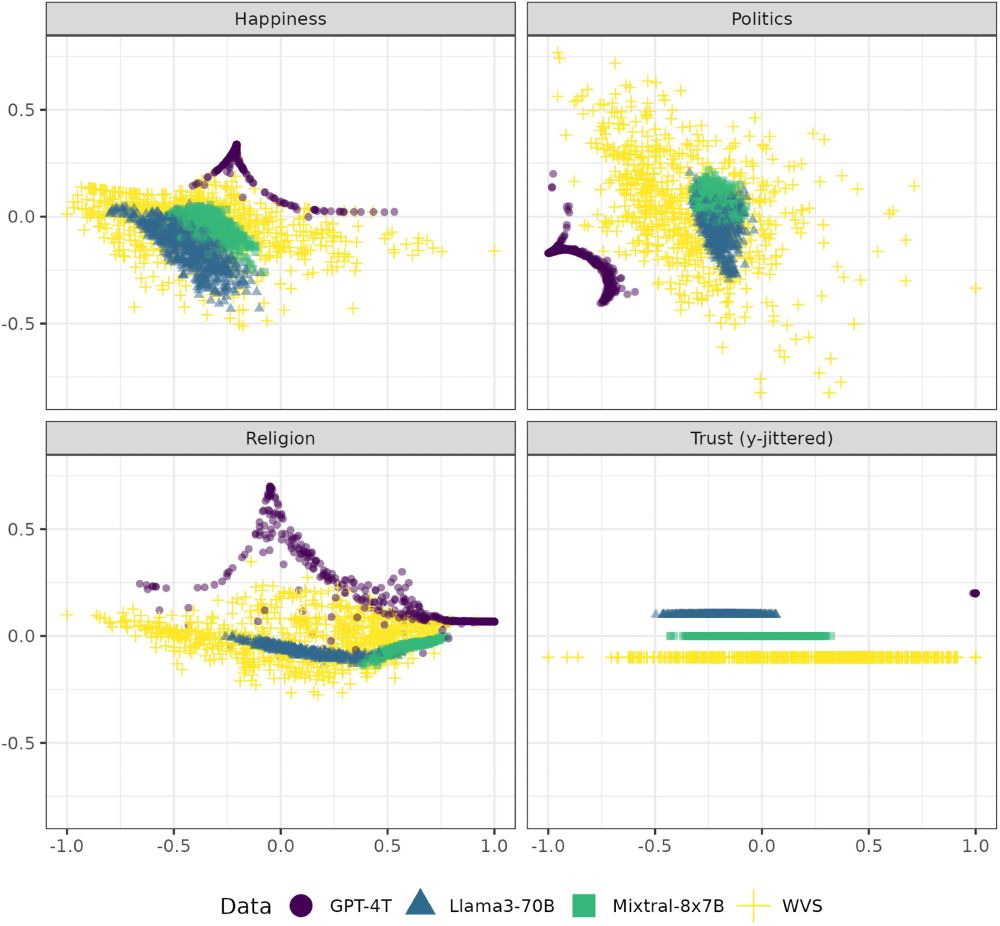
August 1, 2025 at 2:54 PM
Boelaert and colleagues pose a challenge to work that uses LLMs as substitutes for humans in surveys, finding that AI models exhibit idiosyncratic biases they term “machine bias” journals.sagepub.com/doi/abs/10.1...
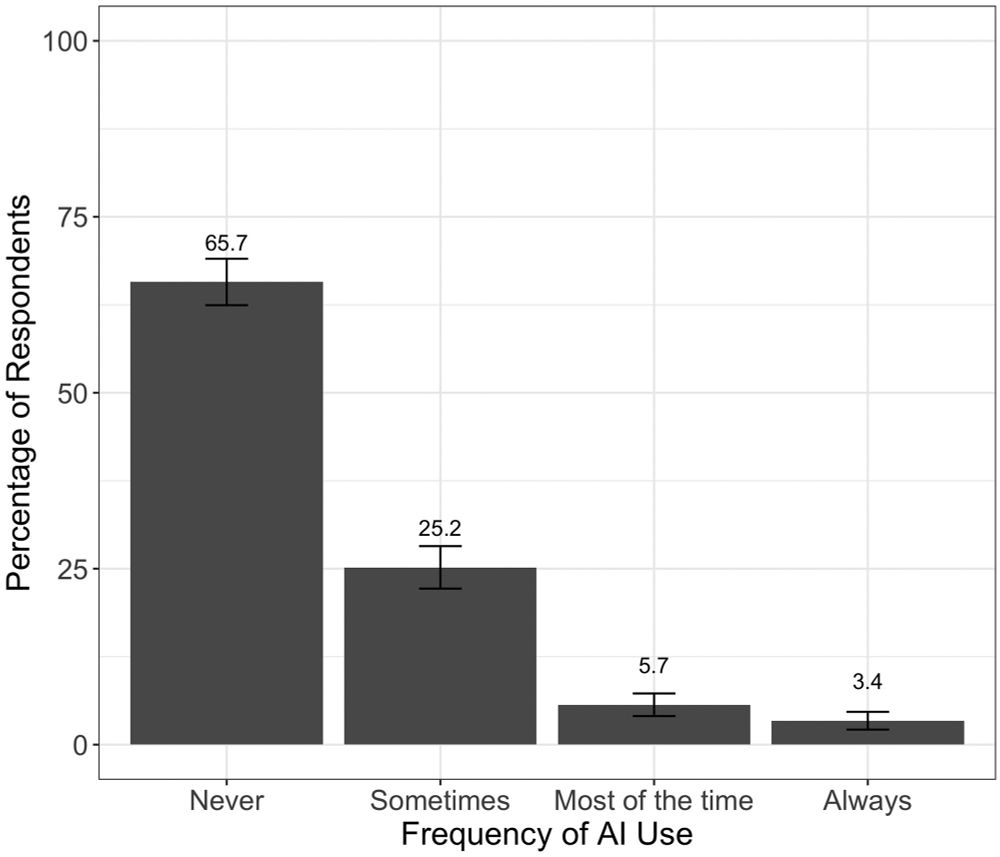
Zhang, Xu, and Alvero show how online survey participants are already using AI for open-ended responses, demonstratng how many researchers will have to grapple with the impacts of AI-generated data journals.sagepub.com/doi/abs/10.1...
August 1, 2025 at 2:54 PM
Zhang, Xu, and Alvero show how online survey participants are already using AI for open-ended responses, demonstratng how many researchers will have to grapple with the impacts of AI-generated data journals.sagepub.com/doi/abs/10.1...
I’m delighted to share that the August 2025 special issue of Sociological Methods & Research on Generative AI is out now. Along with my co-editor, Daniel Karell, we put together this issue to build on the conference we organized last year.
Here's a thread on each of the ten papers:
Here's a thread on each of the ten papers:
August 1, 2025 at 2:54 PM
I’m delighted to share that the August 2025 special issue of Sociological Methods & Research on Generative AI is out now. Along with my co-editor, Daniel Karell, we put together this issue to build on the conference we organized last year.
Here's a thread on each of the ten papers:
Here's a thread on each of the ten papers:
It was an honor to visit the University of Kansas to give the 2025 Blackmar Lecture.
I had a great time learning about the department and the legacy of Frank Blackmar, who taught the first sociology class in the US, which has continued for 135 years www.asanet.org/frank-w-blac...
I had a great time learning about the department and the legacy of Frank Blackmar, who taught the first sociology class in the US, which has continued for 135 years www.asanet.org/frank-w-blac...

May 2, 2025 at 6:10 PM
It was an honor to visit the University of Kansas to give the 2025 Blackmar Lecture.
I had a great time learning about the department and the legacy of Frank Blackmar, who taught the first sociology class in the US, which has continued for 135 years www.asanet.org/frank-w-blac...
I had a great time learning about the department and the legacy of Frank Blackmar, who taught the first sociology class in the US, which has continued for 135 years www.asanet.org/frank-w-blac...
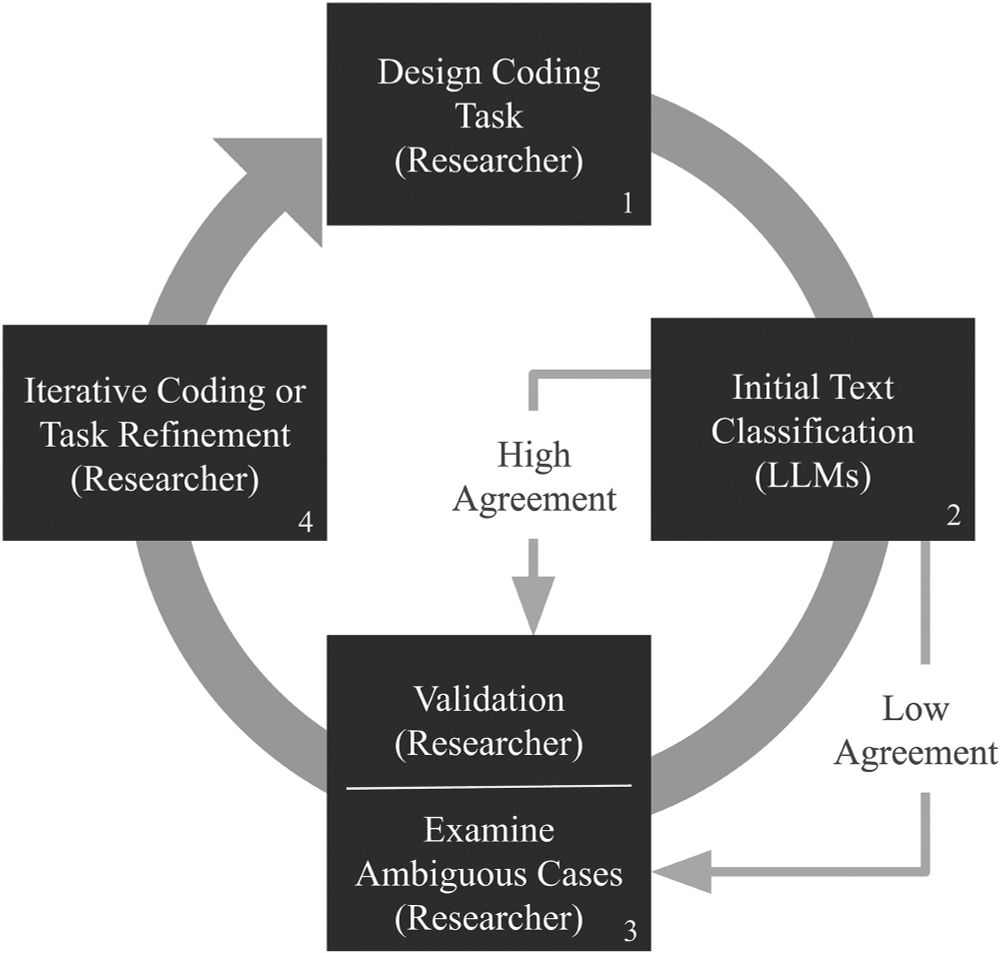
Our article on using LLMs for text classification is out now in SMR! 🤖🧑💻💬
We compare different learning regimes, from zero-shot to instruction-tuning, and share recommendations for sociologists and other social scientists interested in using these models.
doi.org/10.1177/0049...
We compare different learning regimes, from zero-shot to instruction-tuning, and share recommendations for sociologists and other social scientists interested in using these models.
doi.org/10.1177/0049...


April 24, 2025 at 2:36 PM
Our article on using LLMs for text classification is out now in SMR! 🤖🧑💻💬
We compare different learning regimes, from zero-shot to instruction-tuning, and share recommendations for sociologists and other social scientists interested in using these models.
doi.org/10.1177/0049...
We compare different learning regimes, from zero-shot to instruction-tuning, and share recommendations for sociologists and other social scientists interested in using these models.
doi.org/10.1177/0049...