



Tilman Bayer
@tilmanbayer.bsky.social
AI, data, Wikipedia, co-maintainer of @wikiresearch.bsky.social
Not to engage in victim blaming (OpenAI surely invites this kind of mistake), but it's almost 2026 and people should know better than to run such a query without web search/reasoning.
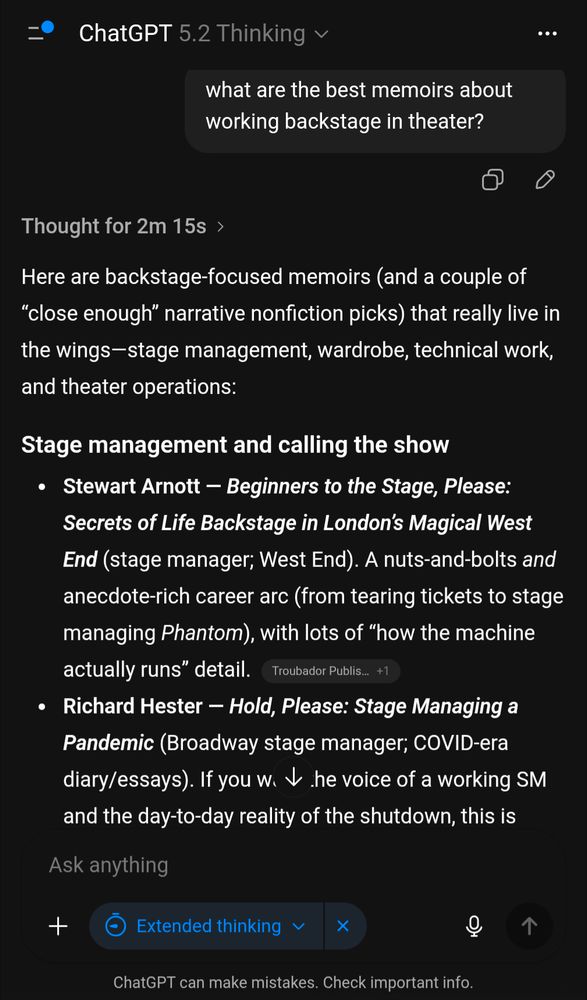
With the same prompt, 5.2 Thinking (with "Extended Thinking") gives me 9 books, all real
chatgpt.com/share/6940a6...
With the same prompt, 5.2 Thinking (with "Extended Thinking") gives me 9 books, all real
chatgpt.com/share/6940a6...
December 16, 2025 at 12:28 AM
Not to engage in victim blaming (OpenAI surely invites this kind of mistake), but it's almost 2026 and people should know better than to run such a query without web search/reasoning.
With the same prompt, 5.2 Thinking (with "Extended Thinking") gives me 9 books, all real
chatgpt.com/share/6940a6...
With the same prompt, 5.2 Thinking (with "Extended Thinking") gives me 9 books, all real
chatgpt.com/share/6940a6...
Big fan of ACX's aspirin vs. warfarin example www.astralcodexten.com/p/webmd-and-...
![Excerpt from https://www.astralcodexten.com/p/webmd-and-the-tragedy-of-legible :
"WebMD is the Internet's most important source of medical information. It's also surprisingly useless. Its most famous problem is that whatever your symptoms, it'll tell you that you have cancer. But the closer you look, the more problems you notice. Consider drug side effects. Here's WebMD's list of side effects for a certain drug, let's call it Drug 1:
'Upset stomach and heartburn may occur. If either of these effects persist or worsen, tell your doctor or pharmacist promptly. If your doctor has directed you to use this medication, remember that he or she has judged that the benefit to you is greater than the risk of side effects. Many people using this medication do not have serious side effects. Tell your doctor right away if you have any serious side effects, including: easy bruising/bleeding, difficulty hearing, ringing in the ears, signs of kidney problems (such as change in the amount of urine), persistent or severe nausea/vomiting, unexplained tiredness, dizziness, dark urine, yellowing eyes/skin. This drug may rarely cause serious bleeding from the stomach/intestine or other areas of the body. If you notice any of the following very serious side effects, get medical help right away: black/tarry stools, persistent or severe stomach/abdominal pain, vomit that looks like coffee grounds, trouble speaking, [...]'
And here's their list of side effects for let's call it Drug 2:
'Nausea, loss of appetite, or stomach/abdominal pain may occur. If any of these effects persist or worsen, tell your doctor or pharmacist promptly. Remember that your doctor has prescribed this medication because he or she has judged that the benefit to you is greater than the risk of side effects. [...]'
Drug 1 is aspirin. Drug 2 is warfarin, which causes 40,000 ER visits a year and is widely considered one of the most dangerous drugs in common use. [...]"](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:zwfl6ilecusklb74e36aym4l/bafkreiaqw7p5yfygx4wer2p2tuhmzrvqjzrohdlw3thczi53h2o5qoakhy@jpeg)
December 14, 2025 at 1:20 AM
Big fan of ACX's aspirin vs. warfarin example www.astralcodexten.com/p/webmd-and-...
Interesting to see the manifesto's extensive reference to Christopher Alexander, given his influence on past decades of software *development* (which, yes, is not the same as software *design*). en.wikipedia.org/wiki/Christo...
!["In software, Alexander is regarded as the father of the pattern language movement. According to creator Ward Cunningham, the first wiki—the technology behind Wikipedia—led directly from Alexander's work.[7][8][9] Alexander's work has also influenced the development of agile software development.[9]" (from https://en.wikipedia.org/wiki/Christopher_Alexander )](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:zwfl6ilecusklb74e36aym4l/bafkreiahzib3qszo3mcy342zvve6ih5ctkrv7c7n7qljta52dtejuwn3wa@jpeg)
December 5, 2025 at 10:01 PM
Interesting to see the manifesto's extensive reference to Christopher Alexander, given his influence on past decades of software *development* (which, yes, is not the same as software *design*). en.wikipedia.org/wiki/Christo...
"applies even more to social media than it did to TV" - which research result(s) are you referring to here, exactly?
The only related statements I can see in the Noy and Rao paper seem inconsistent with such claims that social media exacerbates things relative to cable TV:
The only related statements I can see in the Noy and Rao paper seem inconsistent with such claims that social media exacerbates things relative to cable TV:

November 25, 2025 at 8:21 PM
"applies even more to social media than it did to TV" - which research result(s) are you referring to here, exactly?
The only related statements I can see in the Noy and Rao paper seem inconsistent with such claims that social media exacerbates things relative to cable TV:
The only related statements I can see in the Noy and Rao paper seem inconsistent with such claims that social media exacerbates things relative to cable TV:
Wikipedia editors found out the hard way years ago already that the former reputation of @rollingstone.com for decent non-cultural reporting is a thing of the past.
Articles such as this are now officially unwelcome as a source, by unanimous community consensus: en.wikipedia.org/wiki/Wikiped...
Articles such as this are now officially unwelcome as a source, by unanimous community consensus: en.wikipedia.org/wiki/Wikiped...

November 25, 2025 at 8:28 AM
Wikipedia editors found out the hard way years ago already that the former reputation of @rollingstone.com for decent non-cultural reporting is a thing of the past.
Articles such as this are now officially unwelcome as a source, by unanimous community consensus: en.wikipedia.org/wiki/Wikiped...
Articles such as this are now officially unwelcome as a source, by unanimous community consensus: en.wikipedia.org/wiki/Wikiped...
5.1 Thinking argues that the regulators make the "online platform" classification on the level of "services" (recital 15), after which "Online-platform-specific rights [...] aren’t limited to public content" on that service chatgpt.com/share/691ba8...


November 17, 2025 at 11:19 PM
5.1 Thinking argues that the regulators make the "online platform" classification on the level of "services" (recital 15), after which "Online-platform-specific rights [...] aren’t limited to public content" on that service chatgpt.com/share/691ba8...
Apropos this - half a year later, what's your overall sense about whether and how much this incident has helped increase the reach and/or reputation of Signal?

October 14, 2025 at 6:55 AM
Apropos this - half a year later, what's your overall sense about whether and how much this incident has helped increase the reach and/or reputation of Signal?
I mean, the appendix describes in detail how they measured how much Theory of Mind a user has. E.g. saying "hello" or "thanks" to your chatbot should increase your score.
That said, it's amusing that the scoring was done by AI ("Language Model as a Research Assistant (LMRA; Eloundou et al.; 2024)").
That said, it's amusing that the scoring was done by AI ("Language Model as a Research Assistant (LMRA; Eloundou et al.; 2024)").


September 25, 2025 at 6:09 PM
I mean, the appendix describes in detail how they measured how much Theory of Mind a user has. E.g. saying "hello" or "thanks" to your chatbot should increase your score.
That said, it's amusing that the scoring was done by AI ("Language Model as a Research Assistant (LMRA; Eloundou et al.; 2024)").
That said, it's amusing that the scoring was done by AI ("Language Model as a Research Assistant (LMRA; Eloundou et al.; 2024)").



Promoting 'Adult Content' on Bluesky, eh? 😉
Hope you aren't going to travel to Mississippi or the UK anytime soon ...
Hope you aren't going to travel to Mississippi or the UK anytime soon ...

September 11, 2025 at 11:41 PM
Promoting 'Adult Content' on Bluesky, eh? 😉
Hope you aren't going to travel to Mississippi or the UK anytime soon ...
Hope you aren't going to travel to Mississippi or the UK anytime soon ...
That's a cool pfp idea!

September 8, 2025 at 12:26 AM
That's a cool pfp idea!
That's false, the paper explicitly states on p.4 that interstates/freeways/expressways were excluded.
In SF, that would mean that I-280 and U.S. Route 101 (which Waymo indeed still only does test rides on, although "doesn't go on" is false too) are not included in the comparison.
In SF, that would mean that I-280 and U.S. Route 101 (which Waymo indeed still only does test rides on, although "doesn't go on" is false too) are not included in the comparison.

August 24, 2025 at 8:52 PM
That's false, the paper explicitly states on p.4 that interstates/freeways/expressways were excluded.
In SF, that would mean that I-280 and U.S. Route 101 (which Waymo indeed still only does test rides on, although "doesn't go on" is false too) are not included in the comparison.
In SF, that would mean that I-280 and U.S. Route 101 (which Waymo indeed still only does test rides on, although "doesn't go on" is false too) are not included in the comparison.
...and applied it to the Wildchat dataset... www.phylliida.dev/modelwelfare...

August 15, 2025 at 2:12 AM
...and applied it to the Wildchat dataset... www.phylliida.dev/modelwelfare...
How does this compare to Anthropic's Clio data? www.anthropic.com/research/clio
(or, where in these top 10 use cases might the company hide such chats 😉)
(or, where in these top 10 use cases might the company hide such chats 😉)

August 15, 2025 at 12:19 AM
How does this compare to Anthropic's Clio data? www.anthropic.com/research/clio
(or, where in these top 10 use cases might the company hide such chats 😉)
(or, where in these top 10 use cases might the company hide such chats 😉)
I believe there is lots of potential there.
But it's rather peculiar that Kaurov and Oreskes highlight the Black Spatula Project as a concrete example. It launched to big fanfare in December and appears to have seen basically zero activity afterwards according to its GitHub page
But it's rather peculiar that Kaurov and Oreskes highlight the Black Spatula Project as a concrete example. It launched to big fanfare in December and appears to have seen basically zero activity afterwards according to its GitHub page


July 26, 2025 at 6:11 PM
I believe there is lots of potential there.
But it's rather peculiar that Kaurov and Oreskes highlight the Black Spatula Project as a concrete example. It launched to big fanfare in December and appears to have seen basically zero activity afterwards according to its GitHub page
But it's rather peculiar that Kaurov and Oreskes highlight the Black Spatula Project as a concrete example. It launched to big fanfare in December and appears to have seen basically zero activity afterwards according to its GitHub page
By the way, do you happen to have any idea what kind of "law enforcement requirements related to cyber-bullying prevention" Tea might be blaming here? www.teaforwomen.com/cyberincident

July 26, 2025 at 5:51 PM
By the way, do you happen to have any idea what kind of "law enforcement requirements related to cyber-bullying prevention" Tea might be blaming here? www.teaforwomen.com/cyberincident
I guess the fact that they apparently looked at developer fixed effects doesn't really assuage you ...

July 11, 2025 at 6:02 AM
I guess the fact that they apparently looked at developer fixed effects doesn't really assuage you ...
By the way, which visionary 1990s views by Burda are you gushing about here, exactly ("breathtaking")?
Context: ...
Context: ...

July 2, 2025 at 5:33 PM
By the way, which visionary 1990s views by Burda are you gushing about here, exactly ("breathtaking")?
Context: ...
Context: ...
This thread fails to mention that the release (even though based on PD material) prohibits commercial use and comes with other unusual terms (which open-source project wants to hire lawyers to determine whether your lawyers would agree that it is "unaffiliated with commercial ... intent"?)
![excerpt from "Terms of Use for Early-Access" at https://huggingface.co/datasets/institutional/institutional-books-1.0 :
"Terms of Use for Early-Access
This dataset is an Early-Access release shared by the Institutional Data Initiative for research and public-interest use (the “Service”). These terms are intended to support experimentation while encouraging collaboration and feedback as we refine the dataset and work with contributing institutions to define shared, long-term norms for open data reuse. To share questions or feedback, contact us at contact@institutionaldatainitiative.org.
By accessing or downloading the dataset or otherwise using the Service, you agree to the following:
Noncommercial Use Only
You may use the Service solely for noncommercial purposes. Open-source projects and other public-use efforts are welcome, even if they may indirectly support commercial use, so long as they are unaffiliated with commercial actors or intent.
If you are affiliated with a commercial organization or plan to use the Service for commercial purposes (including AI model training), you will contact us first at contact@institutionaldatainitiative.org.
No Redistribution
You may not share or redistribute the Service or any of the data provided through the Service, in whole or in part, including through public repositories or aggregators. If you want others to access it, please direct them to the attribution link.
Derivative Works
You may create derivative works for noncommercial use, but you may not make available any such derivative works that substantially reproduce the original dataset. Only outputs that are significantly transformed and cannot substitute for the original—such as evaluations, summary statistics, or visualizations—may be shared, with attribution.
Attribution
If you use the dataset in public-facing work, you must include attribution substantially similar to:
[...]"](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:zwfl6ilecusklb74e36aym4l/bafkreidp5raghsfm4lqjkd2v4aktki4xndcg6bdxs2i52g4uv7o3lew47i@jpeg)
June 12, 2025 at 11:56 PM
This thread fails to mention that the release (even though based on PD material) prohibits commercial use and comes with other unusual terms (which open-source project wants to hire lawyers to determine whether your lawyers would agree that it is "unaffiliated with commercial ... intent"?)
4) That's why WaPo says your paper has "implications for the policy debate swirling around AI and copyright" (despite your protestations that it is "not a tech policy writeup"), e.g. re the UK bill right now. And why right after quoting pro-fair use arguments it quotes you as a counterpoint.
!["which cast doubt on fair use applying to copyrighted works in generative AI.
AI companies and their investors, meanwhile, have long argued that a better way is not feasible.
In April 2023, Sy Damle, a lawyer representing the venture capital firm Andreessen Horowitz, told the U.S. Copyright Office: “The only practical way for these tools to exist is if they can be trained on massive amounts of data without having to license that data.” Later that year, in comments to the U.K. government, OpenAI said, “[I]t would be impossible to train today’s leading AI models without using copyrighted materials.”
And in January 2024, Anthropic’s expert witness in a copyright trial asserted that “the hypothetical competitive market for licenses covering data to train cutting-edge LLMs would be impracticable,” court documents show.
While AI policy papers often discuss the need for more open data and experts argue about whether large language models should be trained on licensed data from publishers, there’s little effort to put theory into action, the paper’s co-author, Aviya Skowron, head of policy at the nonprofit research institute Eleuther AI, told The Post.
“I would also like those people to get curious about what this task actually entails,” Skowron said." (excerpt from https://www.washingtonpost.com/politics/2025/06/05/tech-brief-ai-copyright-report/ )](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:zwfl6ilecusklb74e36aym4l/bafkreidap7ywu7w5547hwbvqwuzuq7jzkxypnmiixy5fhhhitq5pistnyu@jpeg)
June 12, 2025 at 3:15 AM
4) That's why WaPo says your paper has "implications for the policy debate swirling around AI and copyright" (despite your protestations that it is "not a tech policy writeup"), e.g. re the UK bill right now. And why right after quoting pro-fair use arguments it quotes you as a counterpoint.
3) The introduction makes it clear that the purpose of the paper is not merely the provision of a new dataset, but also to shift policy discussions by finding a possibility to accede to the copyright maximalist demands of IP owners (prohibiting training without "consent").

June 12, 2025 at 3:15 AM
3) The introduction makes it clear that the purpose of the paper is not merely the provision of a new dataset, but also to shift policy discussions by finding a possibility to accede to the copyright maximalist demands of IP owners (prohibiting training without "consent").
1) You come down on the anti fair use side right at the start of the abstract already, embracing the "unlicensed" --> "infringement" / "ethical concerns" shortcut favored by copyright industry advocates.

June 12, 2025 at 3:15 AM
1) You come down on the anti fair use side right at the start of the abstract already, embracing the "unlicensed" --> "infringement" / "ethical concerns" shortcut favored by copyright industry advocates.
Great to see a systematic evaluation of such ideas.
Small correction: It is not true that CORE-Bench (Siegel et al.) "primarily focused on ... computer-science disciplines alone" - medical+social science papers made up more than half of their data set
Small correction: It is not true that CORE-Bench (Siegel et al.) "primarily focused on ... computer-science disciplines alone" - medical+social science papers made up more than half of their data set

May 25, 2025 at 1:46 AM
Great to see a systematic evaluation of such ideas.
Small correction: It is not true that CORE-Bench (Siegel et al.) "primarily focused on ... computer-science disciplines alone" - medical+social science papers made up more than half of their data set
Small correction: It is not true that CORE-Bench (Siegel et al.) "primarily focused on ... computer-science disciplines alone" - medical+social science papers made up more than half of their data set
I mean, BOLD was in fact used by Meta to debias Llama 2, e.g. successfully reducing LLMs' lamentable anti-male bias regarding the US entertainment industry 😉 ("more positive sentiment towards American female actresses than male actors")
arxiv.org/pdf/2307.09288
arxiv.org/pdf/2307.09288


May 5, 2025 at 11:50 PM
I mean, BOLD was in fact used by Meta to debias Llama 2, e.g. successfully reducing LLMs' lamentable anti-male bias regarding the US entertainment industry 😉 ("more positive sentiment towards American female actresses than male actors")
arxiv.org/pdf/2307.09288
arxiv.org/pdf/2307.09288
The "Slaughterbots" scenario focused on autonomous decision-making, expecting this to make drone swarms "scalable weapons of mass destruction" spectrum.ieee.org/why-you-shou...
That hasn't come to pass. The current labor intense drone war in Ukraine still requires lots of human pilots for FPVs etc.
That hasn't come to pass. The current labor intense drone war in Ukraine still requires lots of human pilots for FPVs etc.

April 30, 2025 at 5:57 AM
The "Slaughterbots" scenario focused on autonomous decision-making, expecting this to make drone swarms "scalable weapons of mass destruction" spectrum.ieee.org/why-you-shou...
That hasn't come to pass. The current labor intense drone war in Ukraine still requires lots of human pilots for FPVs etc.
That hasn't come to pass. The current labor intense drone war in Ukraine still requires lots of human pilots for FPVs etc.