

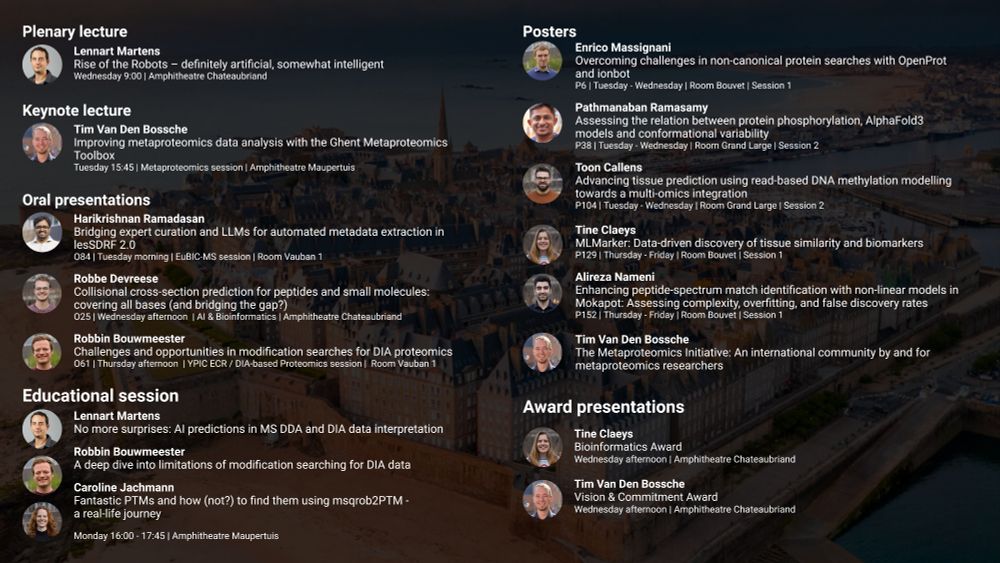
Tine Claeys
@tineclaeys.bsky.social
670 followers
270 following
51 posts
Postdoc in computational proteomics @CompOmics @VIBLifeSciences - turning public data into tissue biomarkers with ML, AI, and a mission to make proteomics truly reusable
Posts
Media
Videos
Starter Packs

Tine Claeys
@tineclaeys.bsky.social
· Aug 27

samvpy.bsky.social
@samvpy.bsky.social
· Aug 27

Limitations of de novo sequencing in resolving sequence ambiguity
De novo peptide sequencing enables peptide identification from fragmentation spectra without relying on sequence databases. However, incomplete spectra create ambiguity, making unambiguous identificat...
www.biorxiv.org

Tine Claeys
@tineclaeys.bsky.social
· Jul 23
Tine Claeys
@tineclaeys.bsky.social
· Jul 22
Tine Claeys
@tineclaeys.bsky.social
· Jul 22
Tine Claeys
@tineclaeys.bsky.social
· Jul 22
Tine Claeys
@tineclaeys.bsky.social
· Jul 22
Tine Claeys
@tineclaeys.bsky.social
· Jul 22
Reposted by Tine Claeys

Tine Claeys
@tineclaeys.bsky.social
· Jun 25
Tine Claeys
@tineclaeys.bsky.social
· Jun 25



Reposted by Tine Claeys


Reposted by Tine Claeys

Reposted by Tine Claeys



Reposted by Tine Claeys

robbin
@robbinbouwmeester.bsky.social
· Jun 4

DeepLC introduces transfer learning for accurate LC retention time prediction and adaptation to substantially different modifications and setups
While LC retention time prediction of peptides and their modifications has proven useful, widespread adoption and optimal performance are hindered by variations in experimental parameters. These varia...
www.biorxiv.org
Reposted by Tine Claeys