




Last week, I spent some time on the DeepSeek OCR paper with @LoganMarkewich and it was genuinely interesting.
It's definitely not just OCR - it's using vision as compression. 10x token reduction while maintaining accuracy.
It's definitely not just OCR - it's using vision as compression. 10x token reduction while maintaining accuracy.

October 28, 2025 at 1:24 PM
Last week, I spent some time on the DeepSeek OCR paper with @LoganMarkewich and it was genuinely interesting.
It's definitely not just OCR - it's using vision as compression. 10x token reduction while maintaining accuracy.
It's definitely not just OCR - it's using vision as compression. 10x token reduction while maintaining accuracy.
Reposted by Tuana

Build Text-to-SQL systems with open source Arctic models and agentic workflows 🚀
Our own @tuana.dev is speaking at Snowflake Build to show you how to create powerful data analysis agents that can handle complex, multi-part questions:
Our own @tuana.dev is speaking at Snowflake Build to show you how to create powerful data analysis agents that can handle complex, multi-part questions:

October 21, 2025 at 6:24 PM
Build Text-to-SQL systems with open source Arctic models and agentic workflows 🚀
Our own @tuana.dev is speaking at Snowflake Build to show you how to create powerful data analysis agents that can handle complex, multi-part questions:
Our own @tuana.dev is speaking at Snowflake Build to show you how to create powerful data analysis agents that can handle complex, multi-part questions:
An interesting overlap exists between memory and context. And a new(ish) memory block that was added as an integration to @llama_index is (imo) - a great demonstration of that 👉 the Artifact Memory Block
October 20, 2025 at 7:28 PM
An interesting overlap exists between memory and context. And a new(ish) memory block that was added as an integration to @llama_index is (imo) - a great demonstration of that 👉 the Artifact Memory Block
This past Monday I had the pleasure of joining a panel about open-source and AI, hosted by Merantix at the London AI Hub.

October 2, 2025 at 3:19 PM
This past Monday I had the pleasure of joining a panel about open-source and AI, hosted by Merantix at the London AI Hub.
We're opening up early access to LlamaAgents - which allows you to go from local LlamaIndex agent workflows to deployed agents in a matter of minutes.

October 1, 2025 at 5:26 PM
We're opening up early access to LlamaAgents - which allows you to go from local LlamaIndex agent workflows to deployed agents in a matter of minutes.
Wrote about something I've been thinking about lately: how AI coding agents are changing how we build AI agents themselves
At LlamaIndex, we've been experimenting with using coding agents like Cursor and Claude Code to speed up build agentic workflows themselves + their UIs
At LlamaIndex, we've been experimenting with using coding agents like Cursor and Claude Code to speed up build agentic workflows themselves + their UIs

August 26, 2025 at 1:45 PM
Wrote about something I've been thinking about lately: how AI coding agents are changing how we build AI agents themselves
At LlamaIndex, we've been experimenting with using coding agents like Cursor and Claude Code to speed up build agentic workflows themselves + their UIs
At LlamaIndex, we've been experimenting with using coding agents like Cursor and Claude Code to speed up build agentic workflows themselves + their UIs
We're making 𝐯𝐢𝐛𝐞-𝐥𝐥𝐚𝐦𝐚 with and for LlamaIndex a lot easier..
Last week we released vibe-llama, a tool developed by @cle-does-things.bsky.social
Last week we released vibe-llama, a tool developed by @cle-does-things.bsky.social
August 25, 2025 at 2:24 PM
We're making 𝐯𝐢𝐛𝐞-𝐥𝐥𝐚𝐦𝐚 with and for LlamaIndex a lot easier..
Last week we released vibe-llama, a tool developed by @cle-does-things.bsky.social
Last week we released vibe-llama, a tool developed by @cle-does-things.bsky.social
This is not GraphRAG, it comes before..
Last week, me and Tomaz (from neo4j) published another demo together. The idea: you have a bunch of unstructured documents (think legal, PDFs etc) and you want to construct a knowledge graph out of them.
Last week, me and Tomaz (from neo4j) published another demo together. The idea: you have a bunch of unstructured documents (think legal, PDFs etc) and you want to construct a knowledge graph out of them.

August 19, 2025 at 1:04 PM
This is not GraphRAG, it comes before..
Last week, me and Tomaz (from neo4j) published another demo together. The idea: you have a bunch of unstructured documents (think legal, PDFs etc) and you want to construct a knowledge graph out of them.
Last week, me and Tomaz (from neo4j) published another demo together. The idea: you have a bunch of unstructured documents (think legal, PDFs etc) and you want to construct a knowledge graph out of them.
OpenAI just dropped new open source models 🔥
My colleague Logan spent his morning testing gpt-oss-20b - which runs on consumer hardware, is Apache 2.0 licensed, and the reasoning quality is solid.
Also, full chain-of-thought access so you can see exactly how it's thinking.
My colleague Logan spent his morning testing gpt-oss-20b - which runs on consumer hardware, is Apache 2.0 licensed, and the reasoning quality is solid.
Also, full chain-of-thought access so you can see exactly how it's thinking.

August 5, 2025 at 6:41 PM
OpenAI just dropped new open source models 🔥
My colleague Logan spent his morning testing gpt-oss-20b - which runs on consumer hardware, is Apache 2.0 licensed, and the reasoning quality is solid.
Also, full chain-of-thought access so you can see exactly how it's thinking.
My colleague Logan spent his morning testing gpt-oss-20b - which runs on consumer hardware, is Apache 2.0 licensed, and the reasoning quality is solid.
Also, full chain-of-thought access so you can see exactly how it's thinking.
Ok this is prettyyy cool, another @llamaindex.bsky.social workflows implementation from @cle-does-things.bsky.social 👇
July 25, 2025 at 5:28 PM
Ok this is prettyyy cool, another @llamaindex.bsky.social workflows implementation from @cle-does-things.bsky.social 👇
Last week @cle-does-things.bsky.social and I created @llamaindex.bsky.social nodes for @n8n.io
Here's what we got:
· LlamaExtract: use extraction agents within n8n workflows
· LlamaParse: parse complex documents
· LlamaCloud: use your existing LlamaCloud indexes as knowledge bases within n8n
Here's what we got:
· LlamaExtract: use extraction agents within n8n workflows
· LlamaParse: parse complex documents
· LlamaCloud: use your existing LlamaCloud indexes as knowledge bases within n8n

July 23, 2025 at 3:27 PM
Last week @cle-does-things.bsky.social and I created @llamaindex.bsky.social nodes for @n8n.io
Here's what we got:
· LlamaExtract: use extraction agents within n8n workflows
· LlamaParse: parse complex documents
· LlamaCloud: use your existing LlamaCloud indexes as knowledge bases within n8n
Here's what we got:
· LlamaExtract: use extraction agents within n8n workflows
· LlamaParse: parse complex documents
· LlamaCloud: use your existing LlamaCloud indexes as knowledge bases within n8n
A new walkthrough for a research agent using Llamaindex and Google Gemini, fresh out the oven. Given a topic:
🌎 Use Gemini 2.5 pro with its server side google search tool
📝 Create an agent that takes notes as it gets results from its websearch
🌎 Use Gemini 2.5 pro with its server side google search tool
📝 Create an agent that takes notes as it gets results from its websearch

July 14, 2025 at 8:40 PM
A new walkthrough for a research agent using Llamaindex and Google Gemini, fresh out the oven. Given a topic:
🌎 Use Gemini 2.5 pro with its server side google search tool
📝 Create an agent that takes notes as it gets results from its websearch
🌎 Use Gemini 2.5 pro with its server side google search tool
📝 Create an agent that takes notes as it gets results from its websearch
Watch as Claude acts as a document agent using LlamaCloud MCP tools to:
- Query any index with custom parsing.
- Use LlamaExtract agents to pull structured data based on LlamaCloud's schema.
The demo features extraction agents for invoices and technical resumes.
youtu.be/IL3CEONiDF4
- Query any index with custom parsing.
- Use LlamaExtract agents to pull structured data based on LlamaCloud's schema.
The demo features extraction agents for invoices and technical resumes.
youtu.be/IL3CEONiDF4

Running the Open-Source LlamaCloud MCP Server
In this video, we run the open-source LlamaCloud MCP server which serves a few tools that we can add more to: - Tools to query any index in LlamaCloud - Tool...
www.youtube.com
July 8, 2025 at 4:06 PM
Watch as Claude acts as a document agent using LlamaCloud MCP tools to:
- Query any index with custom parsing.
- Use LlamaExtract agents to pull structured data based on LlamaCloud's schema.
The demo features extraction agents for invoices and technical resumes.
youtu.be/IL3CEONiDF4
- Query any index with custom parsing.
- Use LlamaExtract agents to pull structured data based on LlamaCloud's schema.
The demo features extraction agents for invoices and technical resumes.
youtu.be/IL3CEONiDF4
With all of this "context engineering" chatter, I've been thinking about how much of LLM performance hinges not just on model architecture, but on how you feed it context a lot lately.
So, co-authored a piece on Context Engineering with Logan:
Here it is:
🔗 www.llamaindex.ai/blog/contex...
So, co-authored a piece on Context Engineering with Logan:
Here it is:
🔗 www.llamaindex.ai/blog/contex...

Context Engineering - What it is, and techniques to consider — LlamaIndex - Build Knowledge Assistants over your Enterprise Data
LlamaIndex is a simple, flexible framework for building knowledge assistants using LLMs connected to your enterprise data.
www.llamaindex.ai
July 4, 2025 at 4:31 PM
With all of this "context engineering" chatter, I've been thinking about how much of LLM performance hinges not just on model architecture, but on how you feed it context a lot lately.
So, co-authored a piece on Context Engineering with Logan:
Here it is:
🔗 www.llamaindex.ai/blog/contex...
So, co-authored a piece on Context Engineering with Logan:
Here it is:
🔗 www.llamaindex.ai/blog/contex...
I like this new terminology around context engineering that's picking up. It's a good way to think about how to build actually effective agentic applications.

July 2, 2025 at 3:24 PM
I like this new terminology around context engineering that's picking up. It's a good way to think about how to build actually effective agentic applications.
Today we're announcing the first stable release of @llama_index workflows. A lightweight framework for building complex, multi-step agentic AI applications in Python and Typescript
www.llamaindex.ai/blog/announ...
www.llamaindex.ai/blog/announ...

Announcing Workflows 1.0: A Lightweight Framework for Agentic systems — LlamaIndex - Build Knowledge Assistants over your Enterprise Data
LlamaIndex is a simple, flexible framework for building knowledge assistants using LLMs connected to your enterprise data.
www.llamaindex.ai
June 30, 2025 at 6:31 PM
Today we're announcing the first stable release of @llama_index workflows. A lightweight framework for building complex, multi-step agentic AI applications in Python and Typescript
www.llamaindex.ai/blog/announ...
www.llamaindex.ai/blog/announ...
Since MCP there are questions about whether it removes the need for you to build your own RAG workflows with vector search. And my answer to that is:

June 27, 2025 at 4:21 PM
Since MCP there are questions about whether it removes the need for you to build your own RAG workflows with vector search. And my answer to that is:
Last week, we concluded the @gradio-hf.bsky.social MCP hackathon with @hf.co. The project that one the @llamaindex.bsky.social prize was the "Nasa Space Explorer" 🔭🪐
3 servers that provide live data on:
☄️ Asteroids
🤖 the Mars Rover
🌌 Astronomy
Here's the space: huggingface.co/spaces/Agen...
3 servers that provide live data on:
☄️ Asteroids
🤖 the Mars Rover
🌌 Astronomy
Here's the space: huggingface.co/spaces/Agen...
June 26, 2025 at 6:13 PM
Last week, we concluded the @gradio-hf.bsky.social MCP hackathon with @hf.co. The project that one the @llamaindex.bsky.social prize was the "Nasa Space Explorer" 🔭🪐
3 servers that provide live data on:
☄️ Asteroids
🤖 the Mars Rover
🌌 Astronomy
Here's the space: huggingface.co/spaces/Agen...
3 servers that provide live data on:
☄️ Asteroids
🤖 the Mars Rover
🌌 Astronomy
Here's the space: huggingface.co/spaces/Agen...
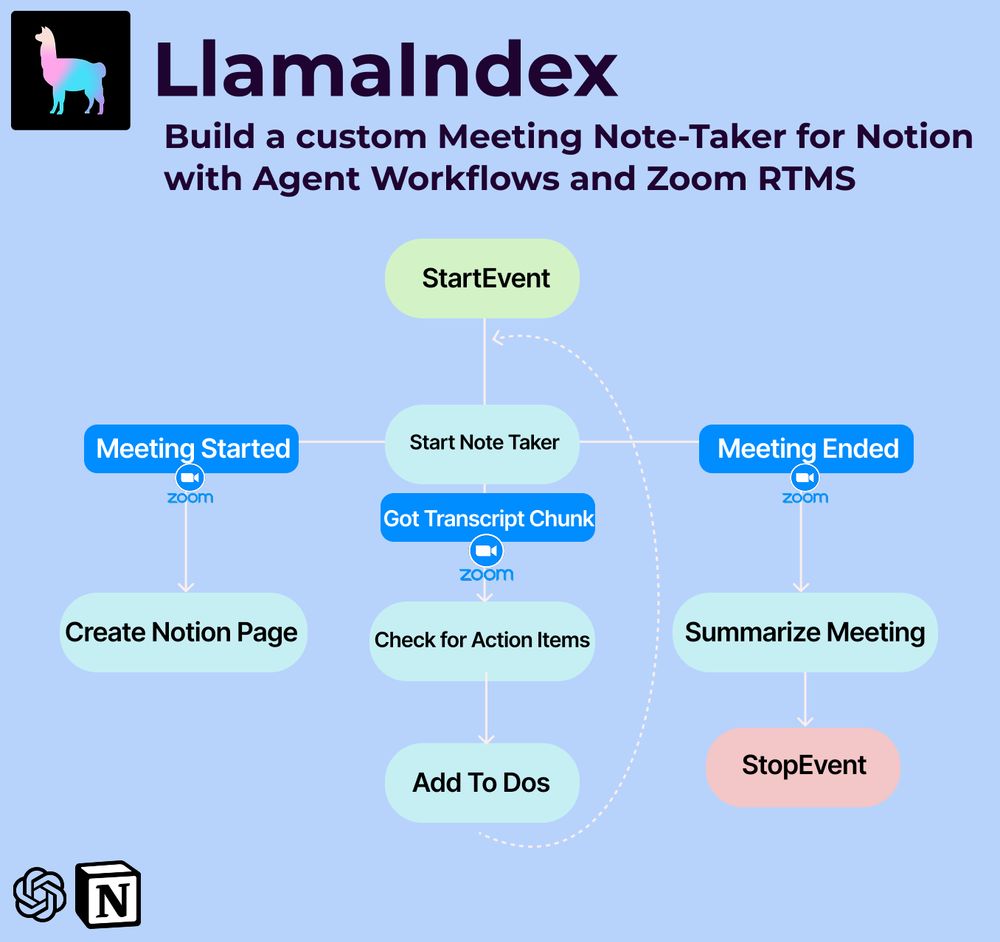
Yesterday Zoom announced Zoom RTMS at the developer summit, which gives you real-time access to audio, video, and transcript data from Zoom Meetings.
June 26, 2025 at 11:19 AM
Yesterday Zoom announced Zoom RTMS at the developer summit, which gives you real-time access to audio, video, and transcript data from Zoom Meetings.
Tomorrow, I'm joining Laura for a discussion on memory.
Note: not all applications that are 'agentic' necessarily _need_ memory. And what type of memory you need also depends on the use case.
Join us at 10AM PT/7PM CET: lu.ma/t27lryii
Note: not all applications that are 'agentic' necessarily _need_ memory. And what type of memory you need also depends on the use case.
Join us at 10AM PT/7PM CET: lu.ma/t27lryii
LlamaIndex Agent Memory: From Short-Term Storage to Intelligent Retention · Luma
The LlamaIndex team is leveling up memory for agents with their newest release:
Improved Long & Short-Term Memory for LlamaIndex Agents
Now, agents can…
lu.ma
June 25, 2025 at 3:00 PM
Tomorrow, I'm joining Laura for a discussion on memory.
Note: not all applications that are 'agentic' necessarily _need_ memory. And what type of memory you need also depends on the use case.
Join us at 10AM PT/7PM CET: lu.ma/t27lryii
Note: not all applications that are 'agentic' necessarily _need_ memory. And what type of memory you need also depends on the use case.
Join us at 10AM PT/7PM CET: lu.ma/t27lryii
Reposted by Tuana
Order Completion Agent with Artifact Editor by @tuana.dev:
Fill out structured forms as the user talks! Checking the completeness along the way:
✅ ArtifactEditorToolSpec to define structured artifacts
✅ ArtifactMemoryBlock to track progress
docs.llamaindex.ai/en/stable/e...
Fill out structured forms as the user talks! Checking the completeness along the way:
✅ ArtifactEditorToolSpec to define structured artifacts
✅ ArtifactMemoryBlock to track progress
docs.llamaindex.ai/en/stable/e...

June 12, 2025 at 4:00 PM
Order Completion Agent with Artifact Editor by @tuana.dev:
Fill out structured forms as the user talks! Checking the completeness along the way:
✅ ArtifactEditorToolSpec to define structured artifacts
✅ ArtifactMemoryBlock to track progress
docs.llamaindex.ai/en/stable/e...
Fill out structured forms as the user talks! Checking the completeness along the way:
✅ ArtifactEditorToolSpec to define structured artifacts
✅ ArtifactMemoryBlock to track progress
docs.llamaindex.ai/en/stable/e...
🍕 Since the first @llamaindex.bsky.social office hours with Logan a specific use-case kept popping up: incremental "form filling".
So, here's a pizzeria order taking assistant using just that with the new Artifact Memory Block and Artifact Editor Tool: colab.research.google.com/drive/13ORO...
So, here's a pizzeria order taking assistant using just that with the new Artifact Memory Block and Artifact Editor Tool: colab.research.google.com/drive/13ORO...

June 11, 2025 at 7:51 PM
🍕 Since the first @llamaindex.bsky.social office hours with Logan a specific use-case kept popping up: incremental "form filling".
So, here's a pizzeria order taking assistant using just that with the new Artifact Memory Block and Artifact Editor Tool: colab.research.google.com/drive/13ORO...
So, here's a pizzeria order taking assistant using just that with the new Artifact Memory Block and Artifact Editor Tool: colab.research.google.com/drive/13ORO...
We’ve started to host more regular office hours now. Come along to ask anything LlamaIndex 👇
Since you loved it last time, @tuana.dev and Logan are hosting another office hours in the LlamaIndex Discord this Thursday.
This time, the topic of choice will be creating MCP servers with LlamaIndex, and per popular request - form filling agents:
discord.com/events/1059...
This time, the topic of choice will be creating MCP servers with LlamaIndex, and per popular request - form filling agents:
discord.com/events/1059...

June 9, 2025 at 4:31 PM
We’ve started to host more regular office hours now. Come along to ask anything LlamaIndex 👇
I’m hosting a discussion session about the biggest blockers to productionizing AI agents at Snowflake Dev Day today.
Come by to the Group By() space at 2PM to have a chat 🩵
Come by to the Group By() space at 2PM to have a chat 🩵
June 5, 2025 at 5:00 PM
I’m hosting a discussion session about the biggest blockers to productionizing AI agents at Snowflake Dev Day today.
Come by to the Group By() space at 2PM to have a chat 🩵
Come by to the Group By() space at 2PM to have a chat 🩵
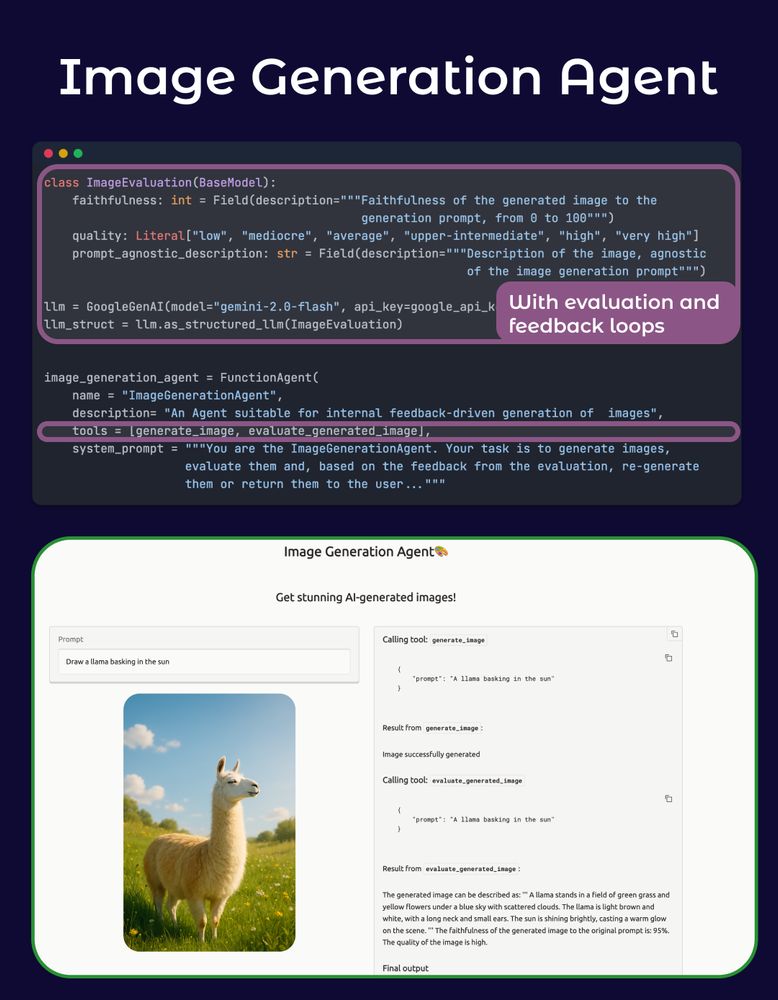
A new oss image generation agent by mu colleague Clelia, that doesn't _just_ generate images.
Structured outputs with Google Gemini to check the generated image and evaluate whether it's ready for the user or not.
The repo: github.com/run-llama/i...
Her code-along: youtu.be/RCASiu5oj6c...
Structured outputs with Google Gemini to check the generated image and evaluate whether it's ready for the user or not.
The repo: github.com/run-llama/i...
Her code-along: youtu.be/RCASiu5oj6c...
May 23, 2025 at 11:31 AM
A new oss image generation agent by mu colleague Clelia, that doesn't _just_ generate images.
Structured outputs with Google Gemini to check the generated image and evaluate whether it's ready for the user or not.
The repo: github.com/run-llama/i...
Her code-along: youtu.be/RCASiu5oj6c...
Structured outputs with Google Gemini to check the generated image and evaluate whether it's ready for the user or not.
The repo: github.com/run-llama/i...
Her code-along: youtu.be/RCASiu5oj6c...