Tyler Chang
@tylerachang.bsky.social
210 followers
65 following
12 posts
PhD student at UC San Diego.
He/him/his.
https://tylerachang.github.io/
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Tyler Chang

Reposted by Tyler Chang


Reposted by Tyler Chang

Tyler Chang
@tylerachang.bsky.social
· Jun 25
Tyler Chang
@tylerachang.bsky.social
· Apr 25
Tyler Chang
@tylerachang.bsky.social
· Apr 25
Tyler Chang
@tylerachang.bsky.social
· Apr 25
Tyler Chang
@tylerachang.bsky.social
· Apr 24
Tyler Chang
@tylerachang.bsky.social
· Dec 13

Scalable Influence and Fact Tracing for Large Language Model Pretraining
Training data attribution (TDA) methods aim to attribute model outputs back to specific training examples, and the application of these methods to large language model (LLM) outputs could significantl...
arxiv.org
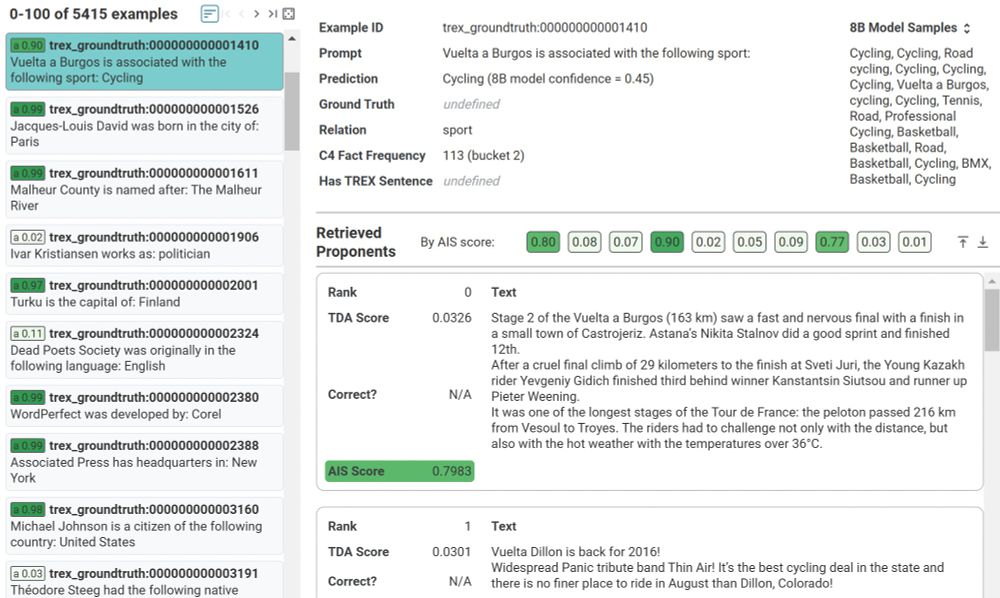
Tyler Chang
@tylerachang.bsky.social
· Dec 13
Tyler Chang
@tylerachang.bsky.social
· Dec 13
Tyler Chang
@tylerachang.bsky.social
· Dec 13
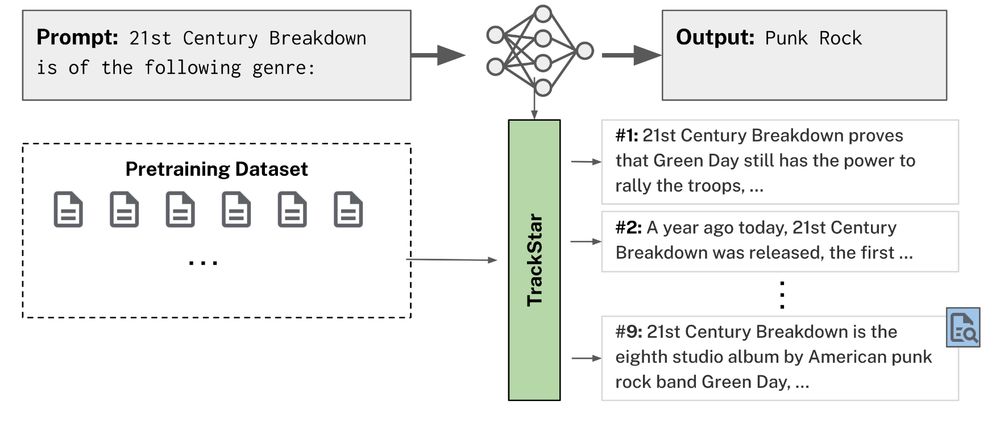
Reposted by Tyler Chang
Reposted by Tyler Chang
