
Verna Dankers
@vernadankers.bsky.social
300 followers
280 following
11 posts
Postdoc at Mila & McGill University 🇨🇦 with a PhD in NLP from the University of Edinburgh 🏴 interpretability x memorisation x (non-)compositionality. she/her 👩💻 🇳🇱
Posts
Media
Videos
Starter Packs
Reposted by Verna Dankers





Verna Dankers
@vernadankers.bsky.social
· Aug 20
Reposted by Verna Dankers




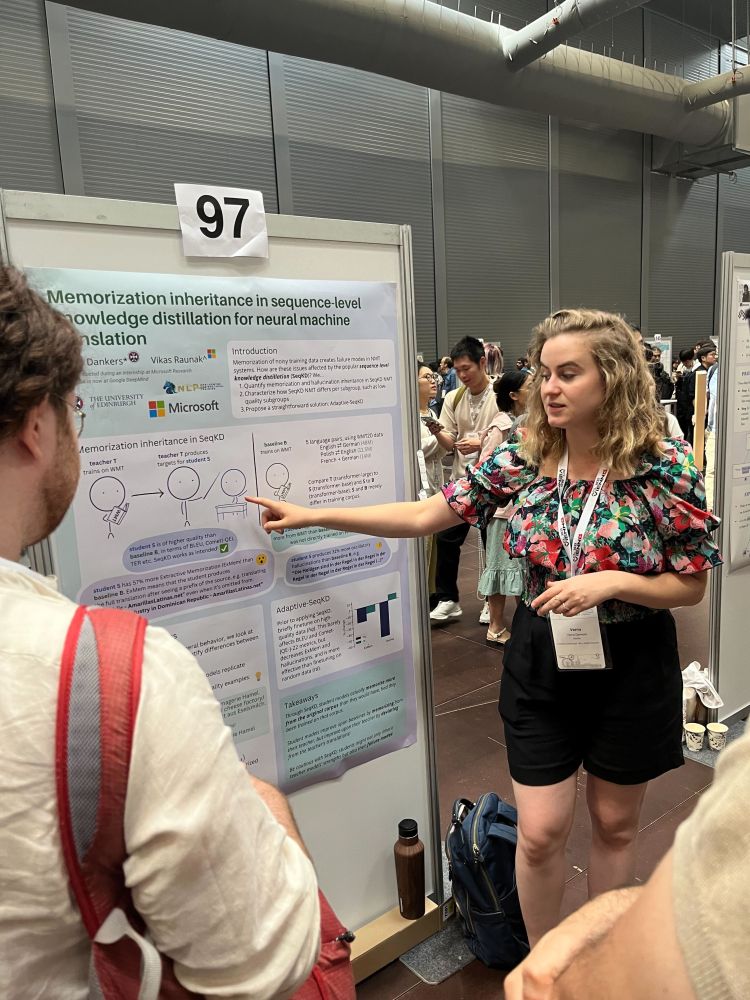


Verna Dankers
@vernadankers.bsky.social
· Jul 27





Reposted by Verna Dankers

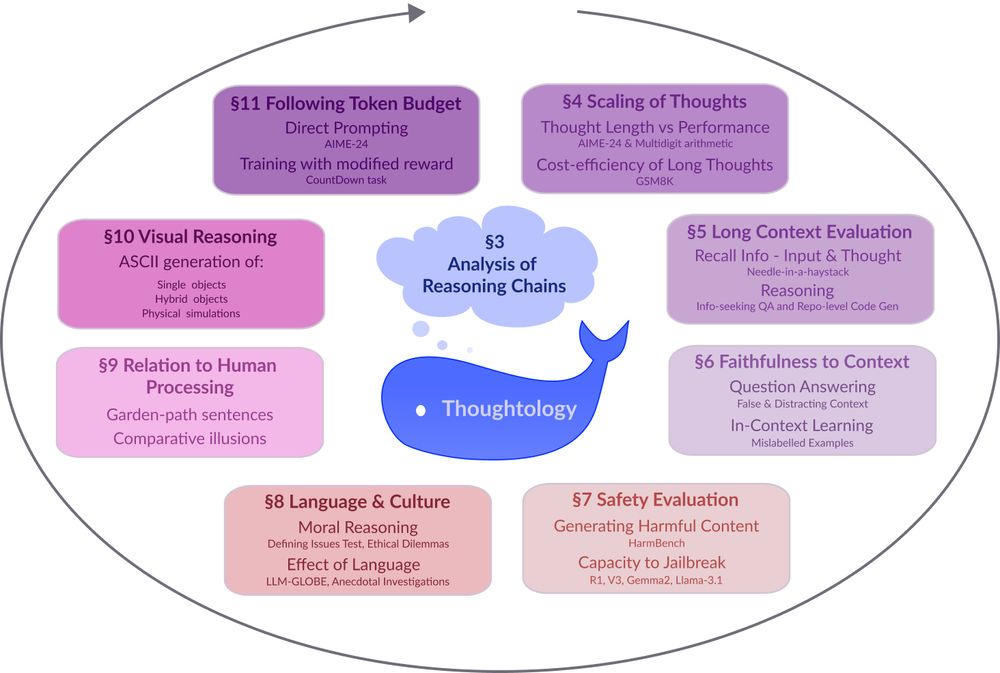
Verna Dankers
@vernadankers.bsky.social
· Mar 11
Verna Dankers
@vernadankers.bsky.social
· Jan 27
Reposted by Verna Dankers

