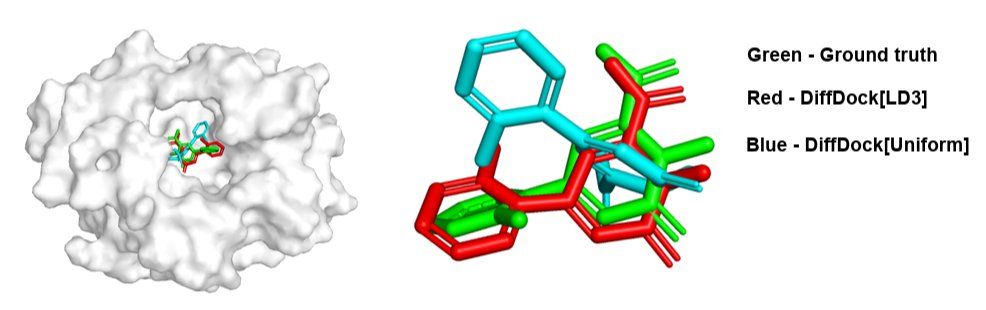
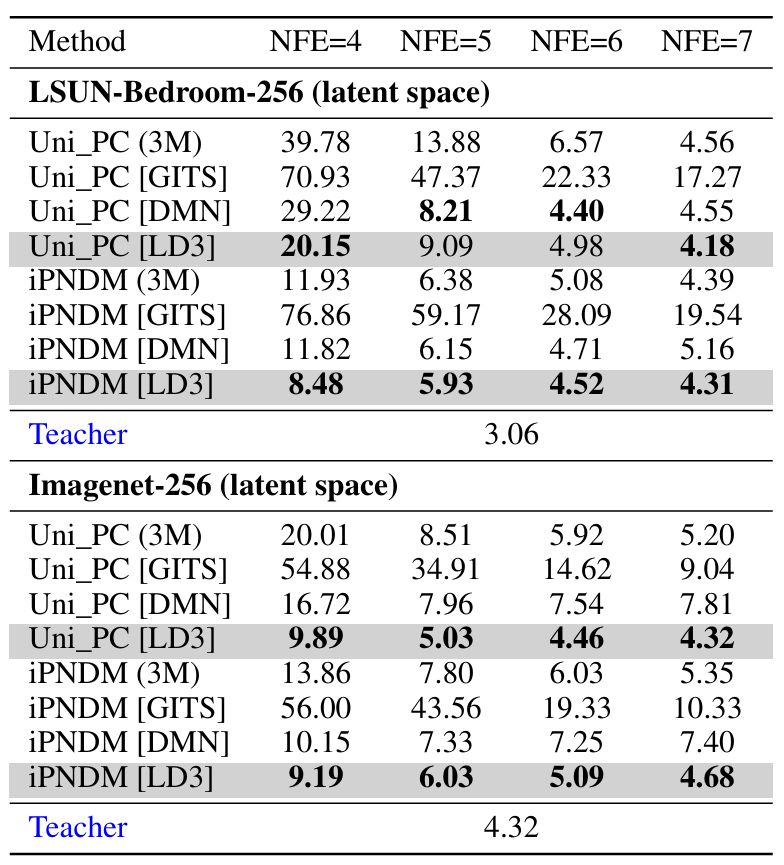
[8/n] LD3 is fast LD3 can be trained on a single GPU in under one hour. For smaller datasets like CIFAR-10, training can be completed in less than 6 minutes.
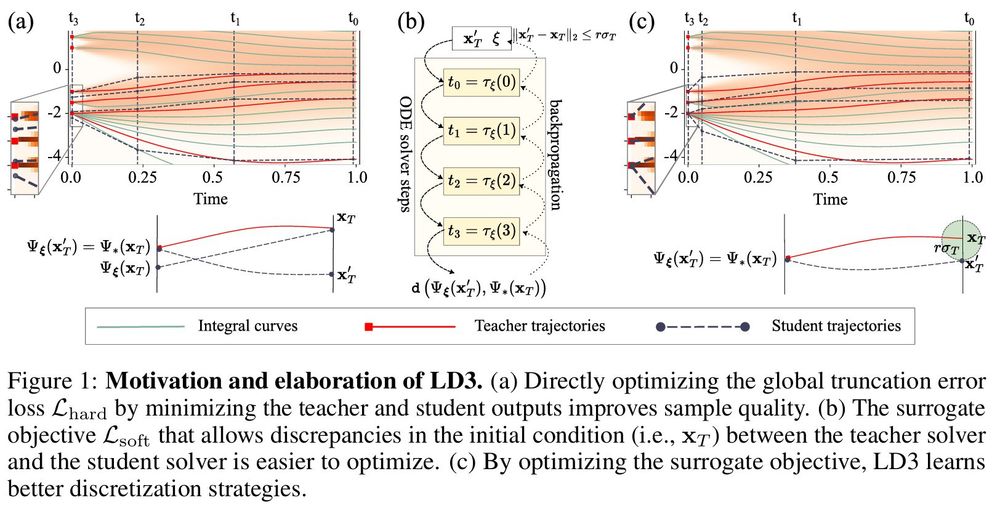
[5/n] Soft constraint A potential problem with the student model is its limited capacity. To address this, we propose a soft surrogate loss, simplifying the student's optimization task.
[4/n] How? LD3 uses a teacher-student framework: 🔹Teacher: Runs the ODE solver with small step sizes. 🔹Student: Learns optimal discretization to match the teacher's output. 🔹Backpropagates through the ODE solver to refine time steps.
[3/n] Key idea LD3 optimizes the time discretization for diffusion ODE solvers by minimizing the global truncation error, resulting in higher sample quality with fewer sampling steps.
[2/n] Diffusion models produce high-quality generations but are computationally expensive due to multi-step sampling. Existing acceleration methods either require costly retraining (distillation) or depend on manually designed time discretization heuristics. LD3 changes that.
🚀 Exciting news! Our paper "Learning to Discretize Diffusion ODEs" has been accepted as an Oral at #ICLR2025! 🎉
[1/n] We propose LD3, a lightweight framework that learns the optimal time discretization for sampling from pre-trained Diffusion Probabilistic Models (DPMs).