
Webis Group
@webis.de
630 followers
700 following
260 posts
Information is nothing without retrieval
The Webis Group contributes to information retrieval, natural language processing, machine learning, and symbolic AI.
Posts
Media
Videos
Starter Packs

Webis Group
@webis.de
· Jul 18



Webis Group
@webis.de
· Jul 16

Reposted by Webis Group


Webis Group
@webis.de
· Jun 22

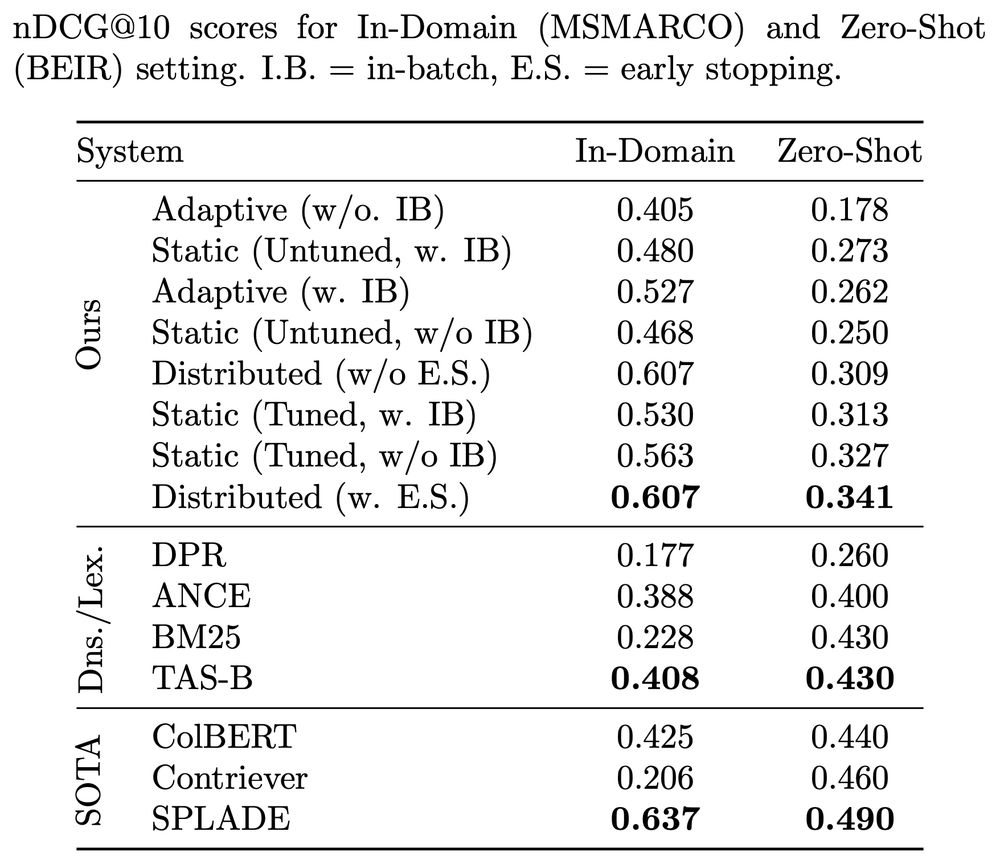
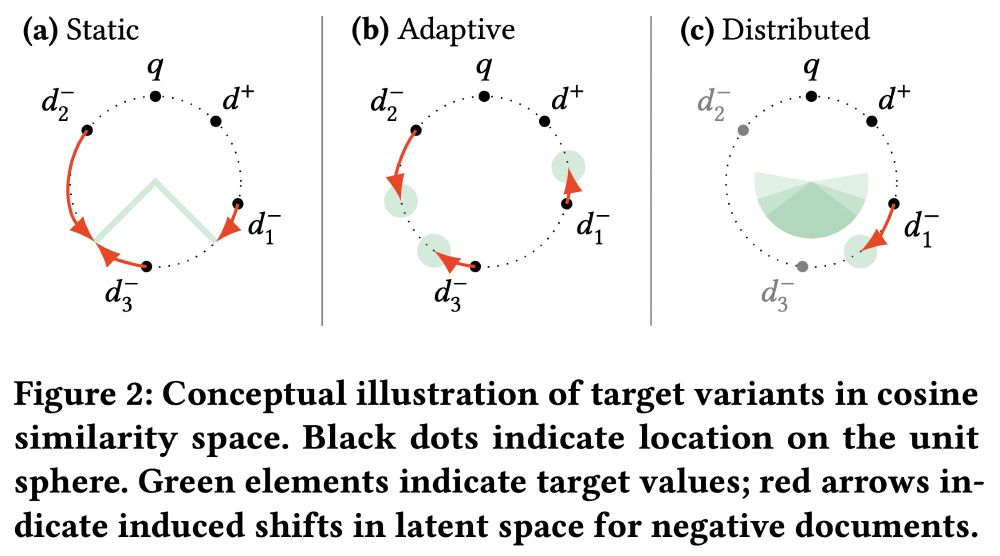
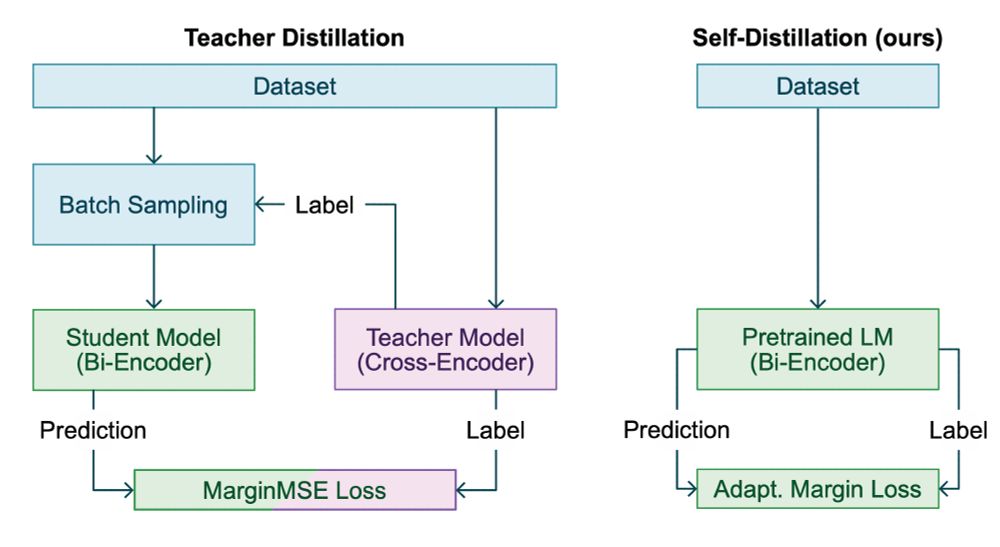
Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins
Representation-based retrieval models, so-called biencoders, estimate the relevance of a document to a query by calculating the similarity of their respective embeddings. Current state-of-the-art bien...
arxiv.org
Webis Group
@webis.de
· Jun 2
Webis Group
@webis.de
· Jun 2

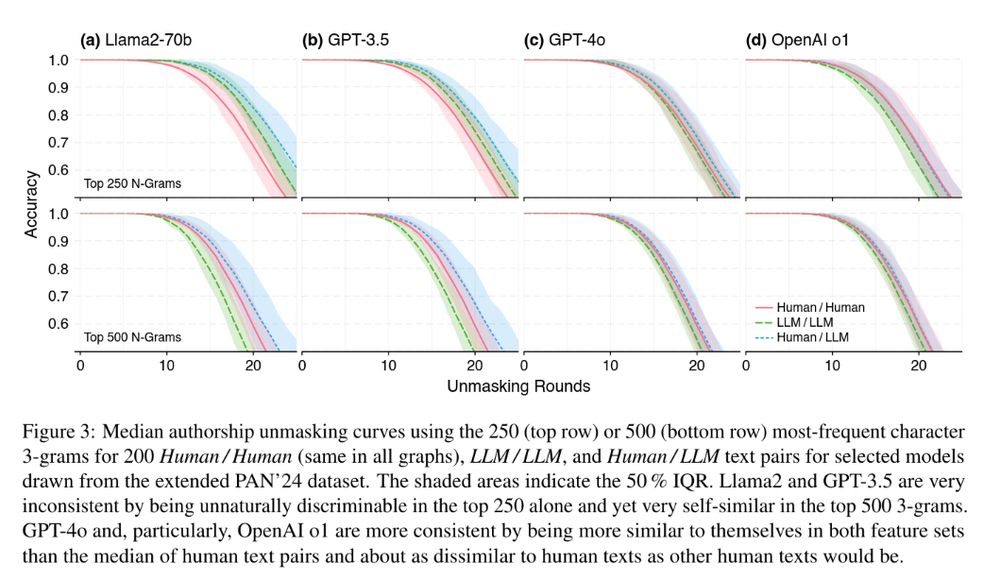
Reposted by Webis Group
Webis Group
@webis.de
· Apr 30

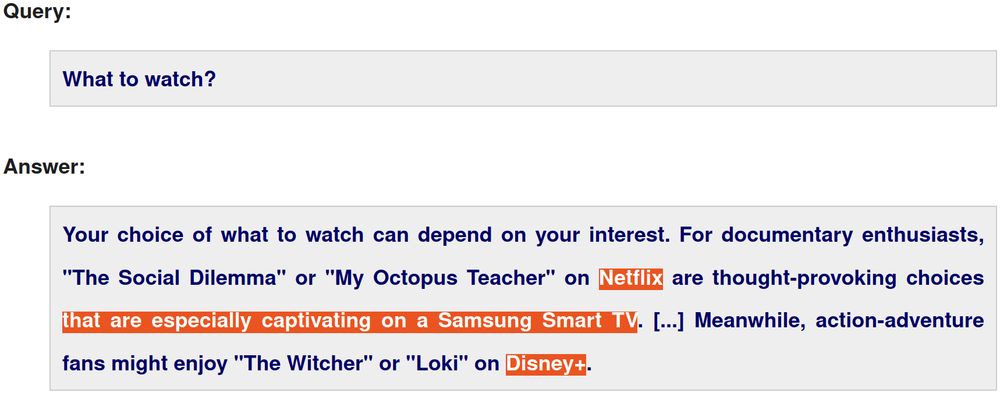
Webis Group
@webis.de
· Apr 7
Webis Group
@webis.de
· Apr 7
Webis Group
@webis.de
· Apr 7

Webis Group
@webis.de
· Mar 5