Philippe Weinzaepfel
@weinzaepfelp.bsky.social
610 followers
580 following
21 posts
Principal Research Scientist in Computer Vision at Naver Labs Europe
https://philippeweinzaepfel.github.io/
Posts
Media
Videos
Starter Packs
Reposted by Philippe Weinzaepfel




Reposted by Philippe Weinzaepfel




Reposted by Philippe Weinzaepfel

Reposted by Philippe Weinzaepfel

Reposted by Philippe Weinzaepfel

Reposted by Philippe Weinzaepfel

Reposted by Philippe Weinzaepfel

Reposted by Philippe Weinzaepfel


Reposted by Philippe Weinzaepfel
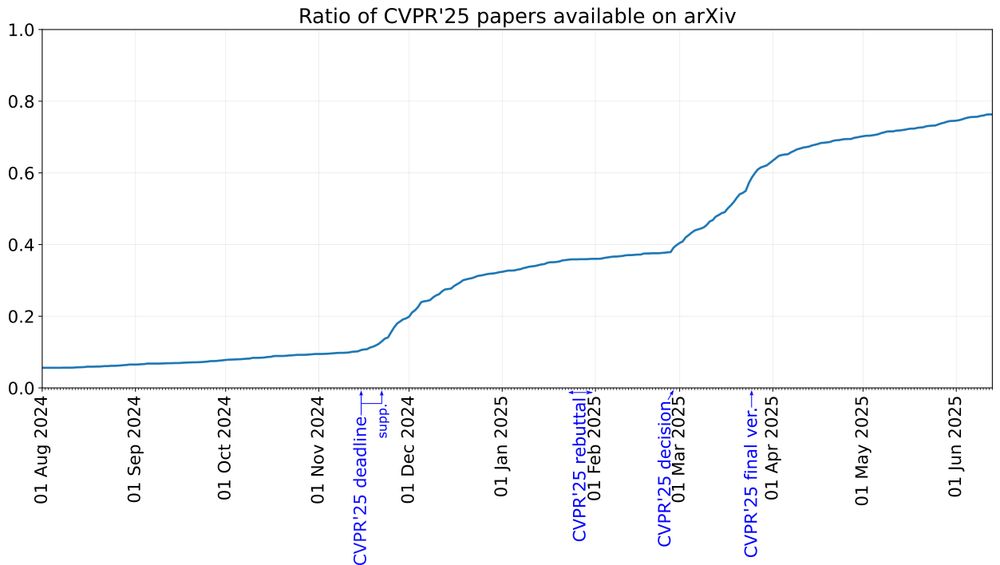

Reposted by Philippe Weinzaepfel

Reposted by Philippe Weinzaepfel