William Gilpin
@wgilpin.bsky.social
640 followers
410 following
31 posts
asst prof at UT Austin physics interested in chaos, fluids, & biophysics.
https://www.wgilpin.com/
Posts
Media
Videos
Starter Packs
Pinned


Reposted by William Gilpin

Eddie Lee
@spintheory.bsky.social
· Jul 8

Innovation-exnovation dynamics on trees and trusses
Innovation and its complement exnovation describe the progression of realized possibilities from the past to the future, and the process depends on the structure of the underlying graph. For example, ...
arxiv.org


William Gilpin
@wgilpin.bsky.social
· Jun 17
William Gilpin
@wgilpin.bsky.social
· Jun 16

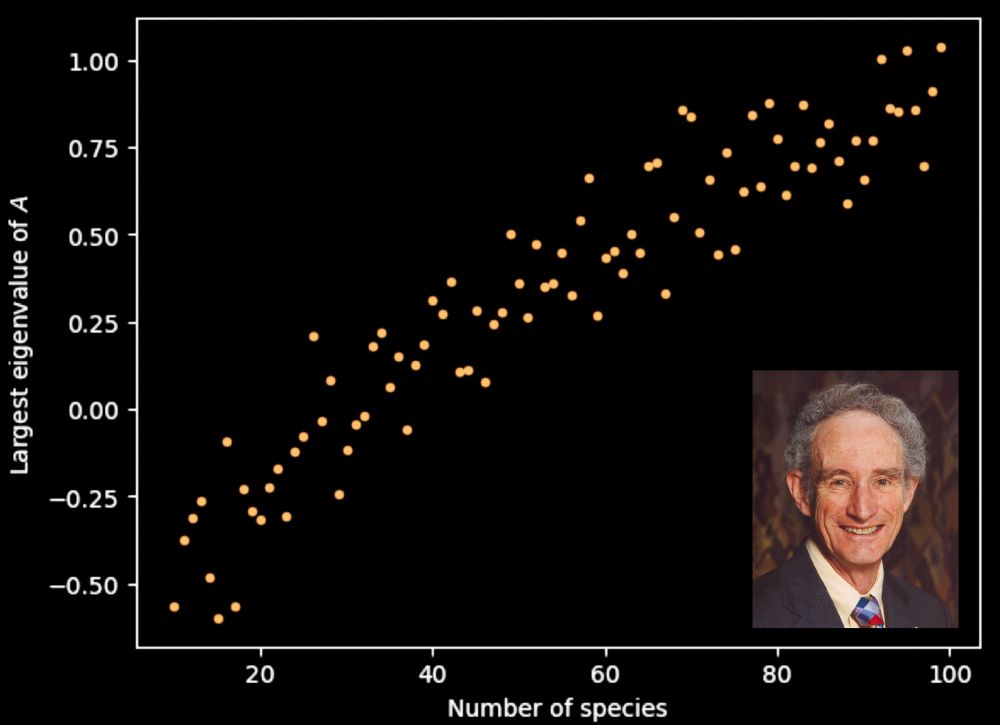
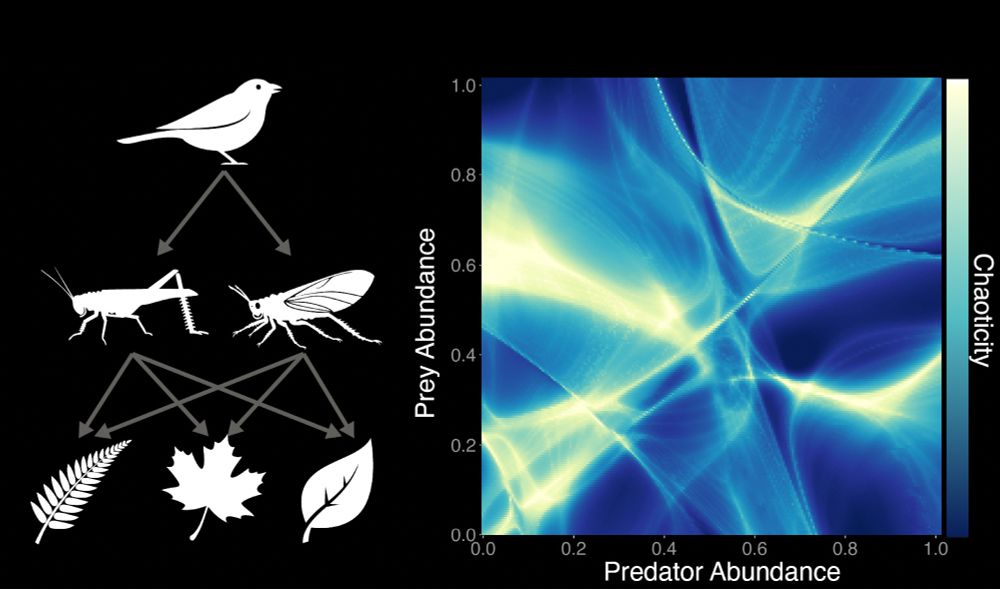
Optimization hardness constrains ecological transients
Author summary Distinct species can serve overlapping functions in complex ecosystems. For example, multiple cyanobacteria species within a microbial mat might serve to fix nitrogen. Here, we show mat...
doi.org