
Will Held
@williamheld.com
2.1K followers
450 following
100 posts
Modeling Linguistic Variation to expand ownership of NLP tools
Views my own, but affiliations that might influence them:
ML PhD Student under Prof. Diyi Yang
2x RS Intern🦙 Pretraining
Alum NYU Abu Dhabi
Burqueño
he/him
Posts
Media
Videos
Starter Packs
Pinned

Will Held
@williamheld.com
· Jan 22
Reposted by Will Held


Reposted by Will Held





Will Held
@williamheld.com
· Jul 28
Will Held
@williamheld.com
· Jul 28
Will Held
@williamheld.com
· Jul 3
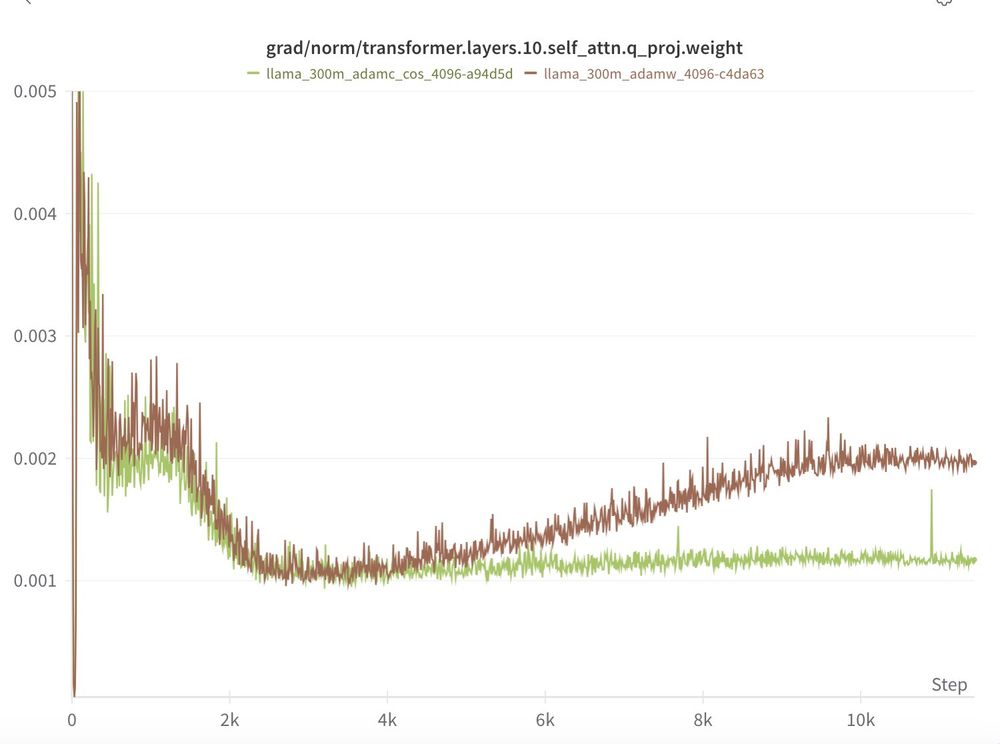
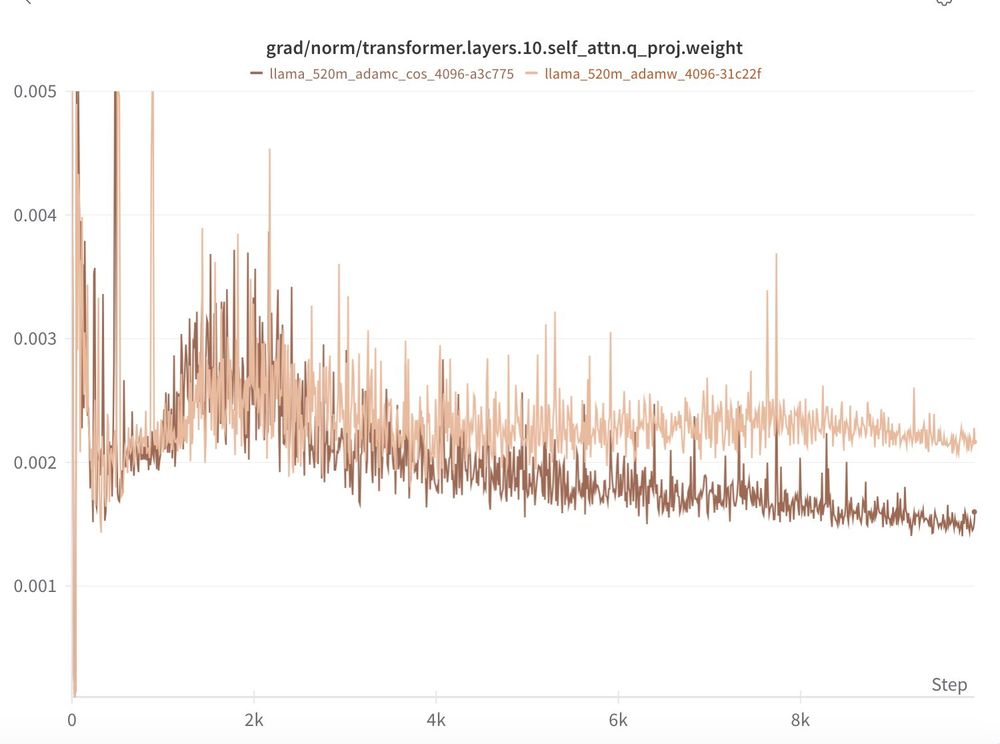
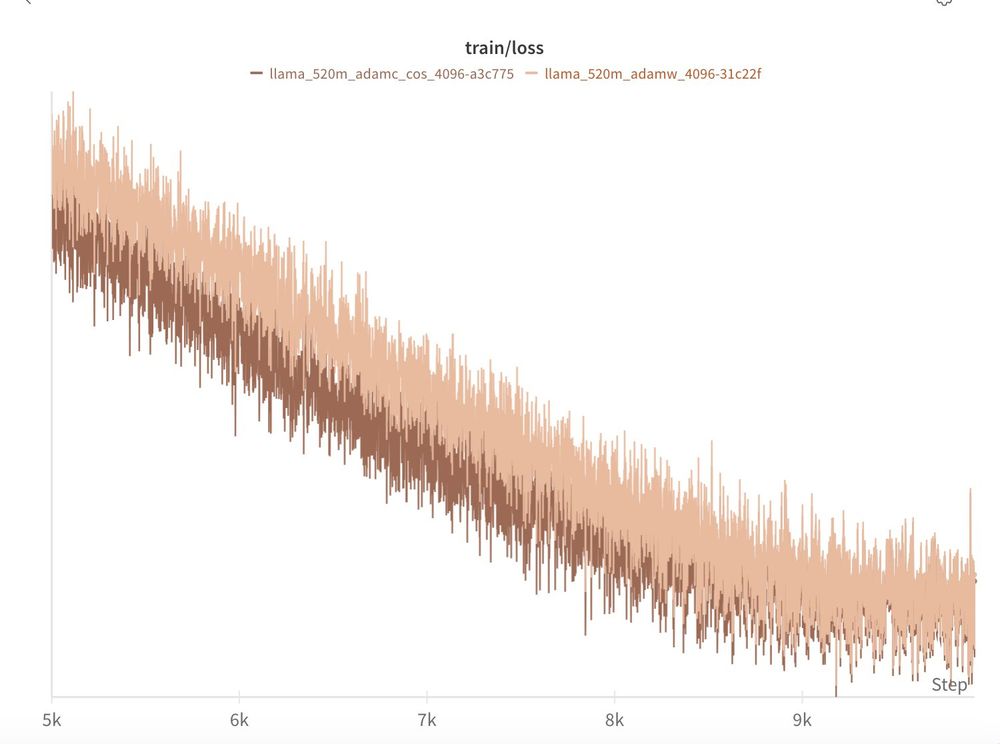
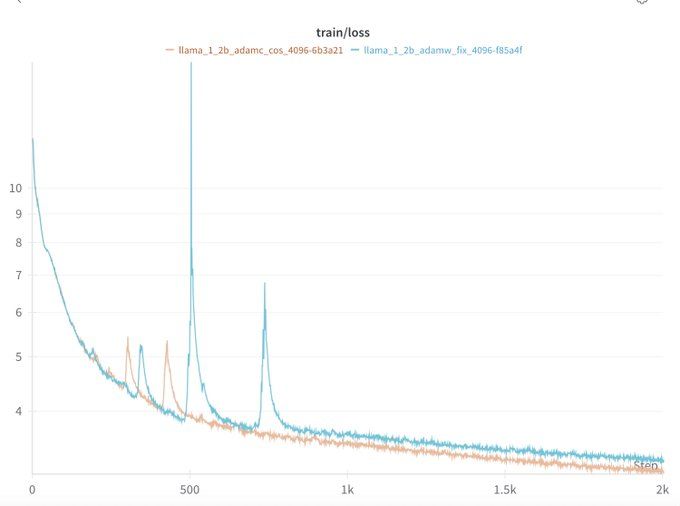
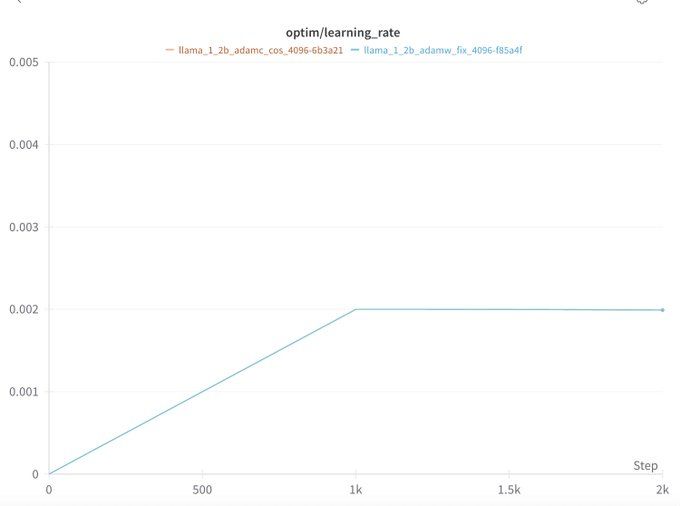
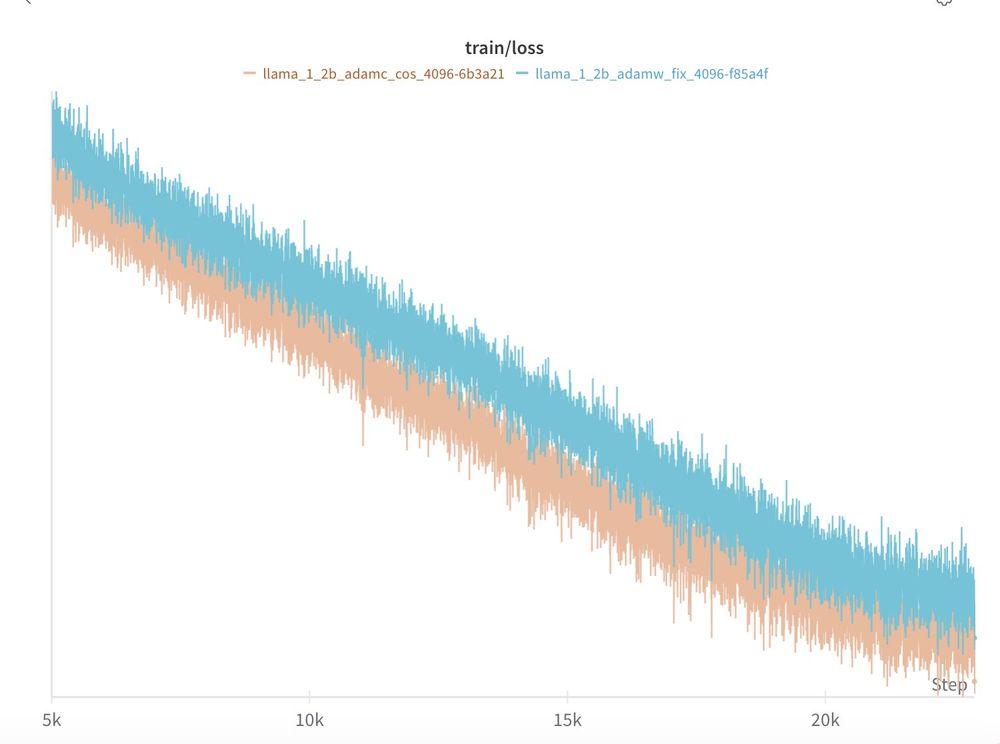
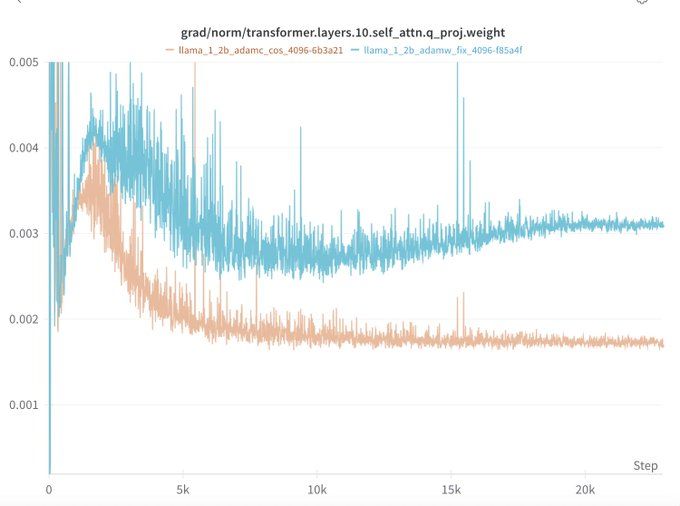
Will Held
@williamheld.com
· Jul 3
Reposted by Will Held
Haley L.
@haleyhaala.bsky.social
· Jun 21

Will Held
@williamheld.com
· Jun 17
Will Held
@williamheld.com
· Jun 17
Will Held
@williamheld.com
· Jun 17
Reposted by Will Held

Brendan Nyhan
@brendannyhan.bsky.social
· Jun 12

Reposted by Will Held


Will Held
@williamheld.com
· Jun 6
Will Held
@williamheld.com
· Jun 5
