Thomas Wimmer
@wimmerthomas.bsky.social
400 followers
140 following
24 posts
PhD Candidate at the Max Planck ETH Center for Learning Systems working on 3D Computer Vision.
https://wimmerth.github.io
Posts
Media
Videos
Starter Packs


Thomas Wimmer
@wimmerthomas.bsky.social
· Aug 21




Reposted by Thomas Wimmer
Thomas Wimmer
@wimmerthomas.bsky.social
· Mar 28

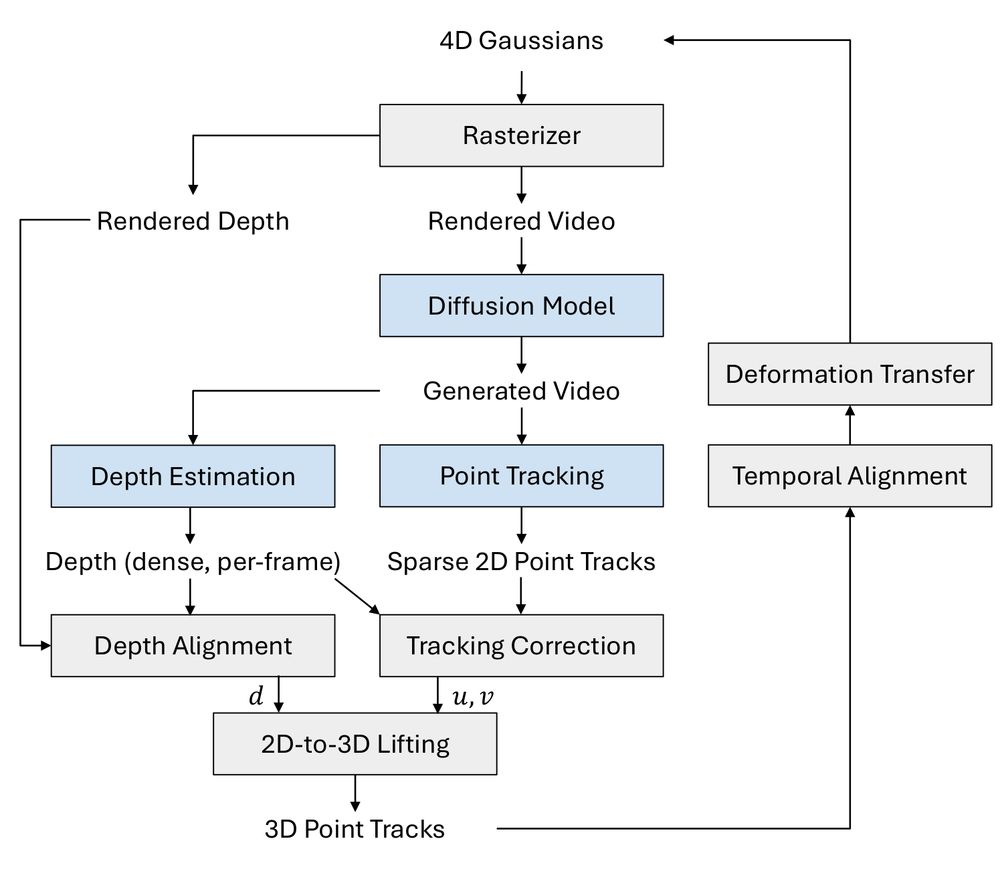
Gaussians-to-Life: Text-Driven Animation of 3D Gaussian
Splatting Scenes
We introduce a method to animate given 3D scenes that uses pre-trained models to lift
2D motion into 3D. We propose a training-free, autoregressive method to generate more 3D-consi...
wimmerth.github.io
Thomas Wimmer
@wimmerthomas.bsky.social
· Mar 28



Thomas Wimmer
@wimmerthomas.bsky.social
· Feb 14
Thomas Wimmer
@wimmerthomas.bsky.social
· Feb 14
Thomas Wimmer
@wimmerthomas.bsky.social
· Feb 14
Reposted by Thomas Wimmer


Thomas Wimmer
@wimmerthomas.bsky.social
· Jan 16
Thomas Wimmer
@wimmerthomas.bsky.social
· Jan 15
Thomas Wimmer
@wimmerthomas.bsky.social
· Jan 15
Thomas Wimmer
@wimmerthomas.bsky.social
· Jan 15
Thomas Wimmer
@wimmerthomas.bsky.social
· Jan 15
Thomas Wimmer
@wimmerthomas.bsky.social
· Jan 15