Zorik Gekhman
@zorikgekhman.bsky.social
7 followers
26 following
17 posts
https://zorikg.github.io/
Posts
Media
Videos
Starter Packs

Zorik Gekhman
@zorikgekhman.bsky.social
· Mar 31

Inside-Out: Hidden Factual Knowledge in LLMs
This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at...
arxiv.org
Zorik Gekhman
@zorikgekhman.bsky.social
· Mar 31
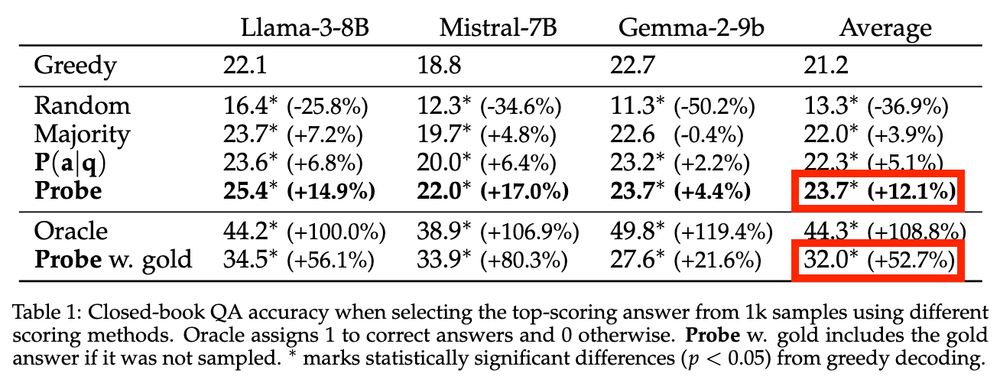
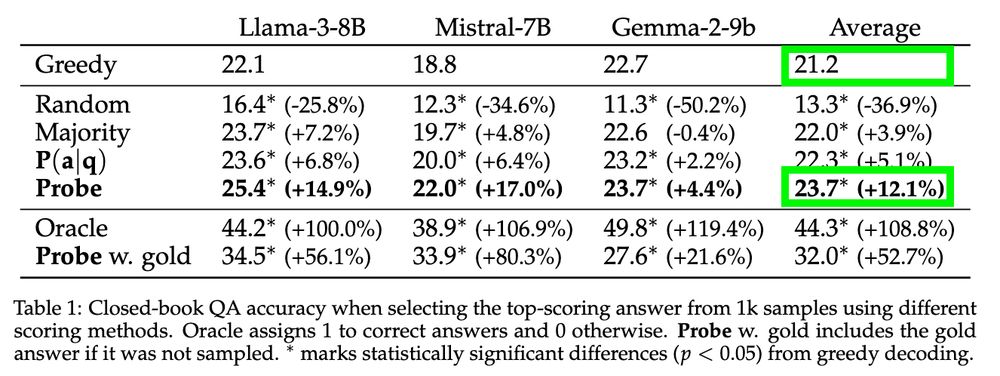

Zorik Gekhman
@zorikgekhman.bsky.social
· Mar 31


Zorik Gekhman
@zorikgekhman.bsky.social
· Mar 31


Zorik Gekhman
@zorikgekhman.bsky.social
· Mar 31

Zorik Gekhman
@zorikgekhman.bsky.social
· Mar 31
Zorik Gekhman
@zorikgekhman.bsky.social
· Mar 31
Zorik Gekhman
@zorikgekhman.bsky.social
· Mar 31
Inside-Out: Hidden Factual Knowledge in LLMs
This work presents a framework for assessing whether large language models (LLMs) encode more factual knowledge in their parameters than what they express in their outputs. While a few studies hint at...
arxiv.org
