



@zymbolizm.bsky.social
Noice, Nous!

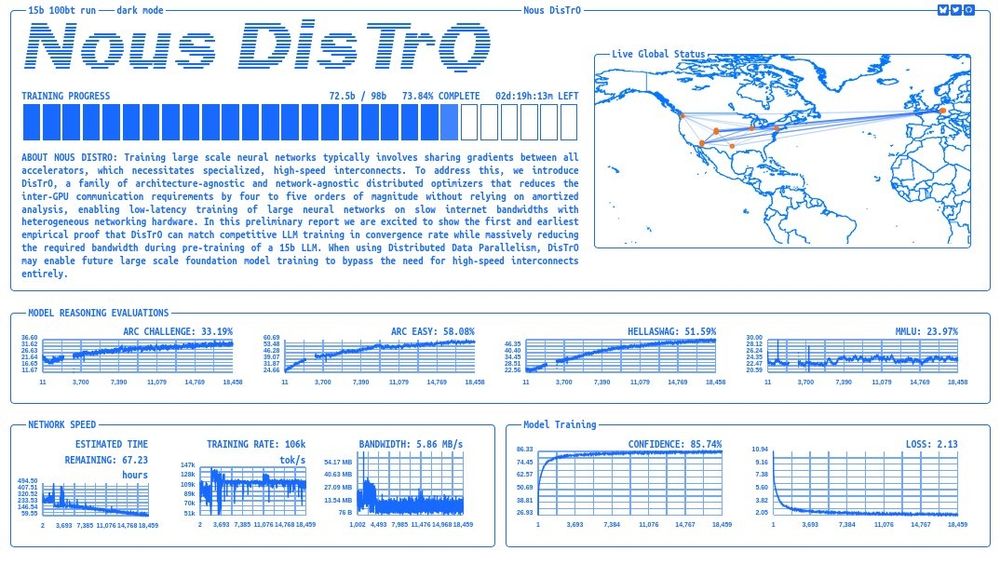
Nous Research announces the pre-training of a 15B parameter language model over the internet, using Nous DisTrO and heterogeneous hardware contributed by our partners at Oracle, Lambda Labs, Northern Data Group, Crusoe, and the Andromeda Cluster.
You can watch the run LIVE: distro.nousresearch.com
You can watch the run LIVE: distro.nousresearch.com
December 2, 2024 at 6:10 PM
Noice, Nous!
Reposted


November 22, 2024 at 11:49 PM
Reposted

Alibaba has their own version on GPT-o1. This might be the best description of “o1-type”systems so far arxiv.org/abs/2411.14405

Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions
Currently OpenAI o1 has sparked a surge of interest in the study of large reasoning models (LRM). Building on this momentum, Marco-o1 not only focuses on disciplines with standard answers, such as mat...
arxiv.org
November 22, 2024 at 12:18 PM
Alibaba has their own version on GPT-o1. This might be the best description of “o1-type”systems so far arxiv.org/abs/2411.14405
Reposted

This paper on Claude with Computer Use matches my experience- as a general purpose agent that can do anything in a computer, it is surprisingly good. Yet it still has enough flaws that it is a sign of the future than a full agent now.
But it also shows the future is soon. arxiv.org/pdf/2411.103...
But it also shows the future is soon. arxiv.org/pdf/2411.103...




November 20, 2024 at 2:31 PM
This paper on Claude with Computer Use matches my experience- as a general purpose agent that can do anything in a computer, it is surprisingly good. Yet it still has enough flaws that it is a sign of the future than a full agent now.
But it also shows the future is soon. arxiv.org/pdf/2411.103...
But it also shows the future is soon. arxiv.org/pdf/2411.103...
Reposted

RedPajama paper has some excellent details on their approach to filtering web-scale data. Nice to see this hidden knowledge
becoming more public over the past few months.
Curious if any big labs will release their datasets/pipelines in the next few months 🙏
🔗 huggingface.co/papers/2411....
becoming more public over the past few months.
Curious if any big labs will release their datasets/pipelines in the next few months 🙏
🔗 huggingface.co/papers/2411....

Paper page - RedPajama: an Open Dataset for Training Large Language Models
Join the discussion on this paper page
huggingface.co
November 20, 2024 at 10:30 AM
RedPajama paper has some excellent details on their approach to filtering web-scale data. Nice to see this hidden knowledge
becoming more public over the past few months.
Curious if any big labs will release their datasets/pipelines in the next few months 🙏
🔗 huggingface.co/papers/2411....
becoming more public over the past few months.
Curious if any big labs will release their datasets/pipelines in the next few months 🙏
🔗 huggingface.co/papers/2411....
Reposted

Are Visual Language Models a game changer for OCR and the transcription of challenging texts? @pandorai1995.bsky.social just published a lengthy report on @huggingface.bsky.social with one main catch: it's complicated. huggingface.co/blog/PandorA...

October 19, 2024 at 10:18 AM
Are Visual Language Models a game changer for OCR and the transcription of challenging texts? @pandorai1995.bsky.social just published a lengthy report on @huggingface.bsky.social with one main catch: it's complicated. huggingface.co/blog/PandorA...
Reposted
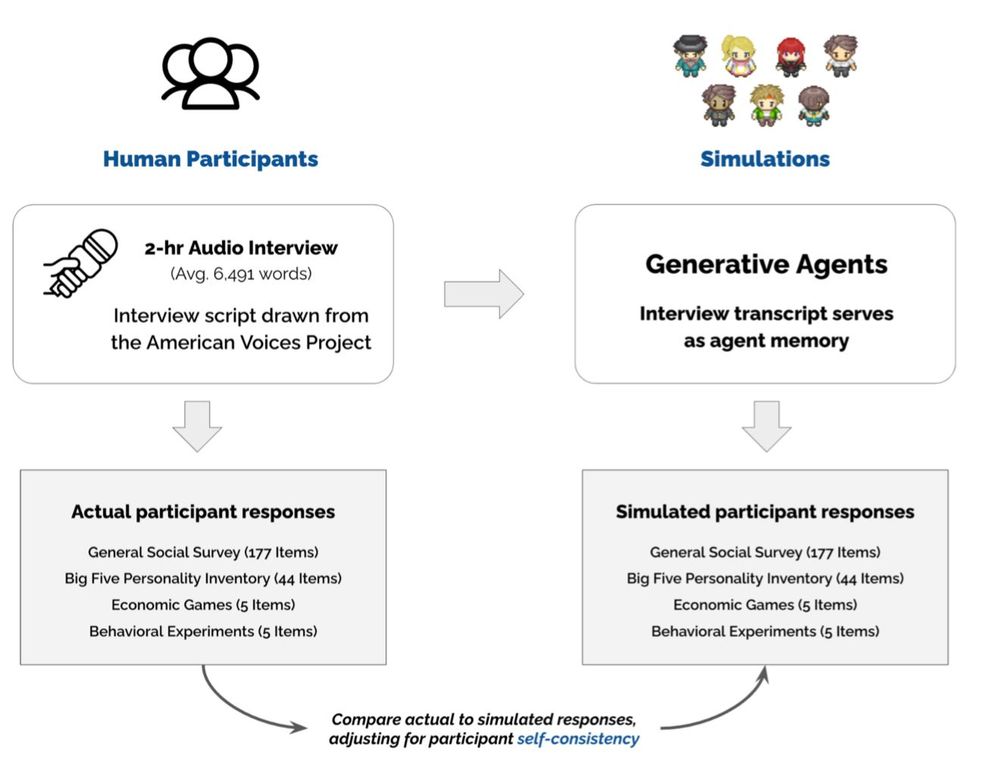
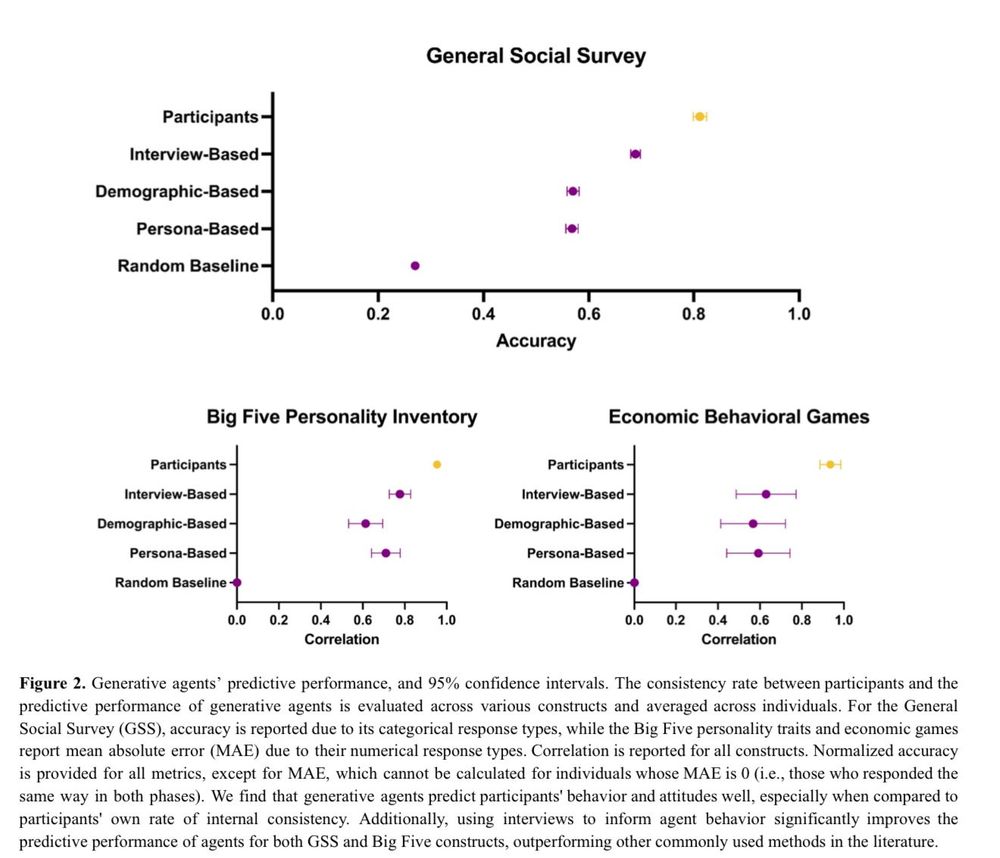
Crazy interesting paper in many ways:
1) Voice-enabled GPT-4o conducted 2 hour
interviews of 1,052 people
2) GPT-4o agents were given the transcripts & prompted to simulate the people
3) The agents were given surveys & tasks. They achieved 85% accuracy in simulating interviewees real answers!
1) Voice-enabled GPT-4o conducted 2 hour
interviews of 1,052 people
2) GPT-4o agents were given the transcripts & prompted to simulate the people
3) The agents were given surveys & tasks. They achieved 85% accuracy in simulating interviewees real answers!

November 19, 2024 at 12:18 AM
Crazy interesting paper in many ways:
1) Voice-enabled GPT-4o conducted 2 hour
interviews of 1,052 people
2) GPT-4o agents were given the transcripts & prompted to simulate the people
3) The agents were given surveys & tasks. They achieved 85% accuracy in simulating interviewees real answers!
1) Voice-enabled GPT-4o conducted 2 hour
interviews of 1,052 people
2) GPT-4o agents were given the transcripts & prompted to simulate the people
3) The agents were given surveys & tasks. They achieved 85% accuracy in simulating interviewees real answers!
Reposted
Releasing two trillion tokens in the open. huggingface.co/blog/Pclangl...

November 13, 2024 at 5:59 PM
Releasing two trillion tokens in the open. huggingface.co/blog/Pclangl...