



Explore F1@K’s role in evaluating model responses' factuality, examining precision, recall, & the impact of response length on long-form factuality assessments. #factcheckingai

How AI Judges the Accuracy of Its Own Answers
hackernoon.com
April 10, 2025 at 1:00 PM
Explore F1@K’s role in evaluating model responses' factuality, examining precision, recall, & the impact of response length on long-form factuality assessments. #factcheckingai
Explore the limitations of LongFact and SAFE, from LLM weaknesses to reliance on Google Search, and considerations for improving future factuality metrics. #factcheckingai
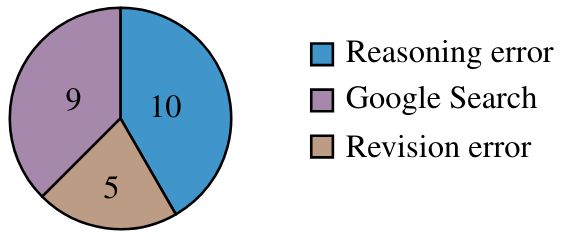
Challenges in Using Google Search for Factuality Verification
hackernoon.com
April 9, 2025 at 11:00 AM
Explore the limitations of LongFact and SAFE, from LLM weaknesses to reliance on Google Search, and considerations for improving future factuality metrics. #factcheckingai
Google DeepMind introduces SAFE, a new AI-powered tool that splits long-form responses into facts and validates them using Google Search for accuracy. #factcheckingai
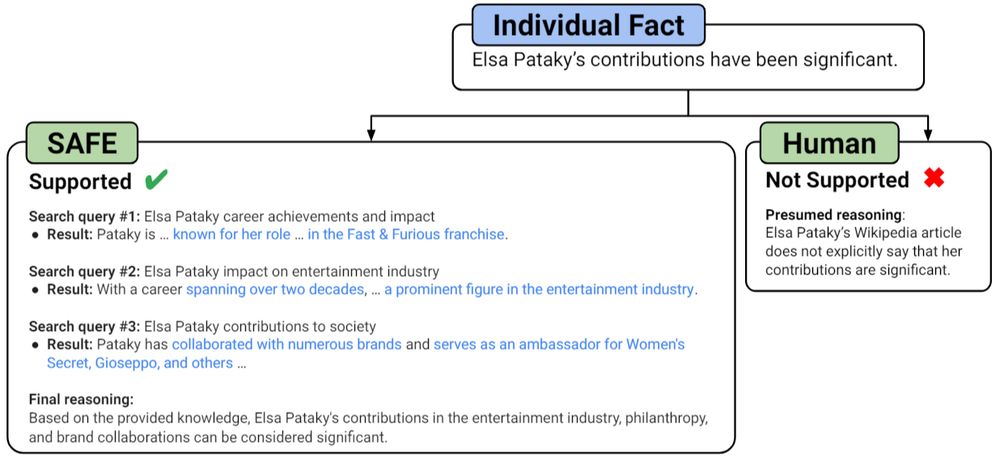
SAFE: A New AI Tool for Fact-Checking Long-Form Responses
hackernoon.com
April 8, 2025 at 10:54 PM
Google DeepMind introduces SAFE, a new AI-powered tool that splits long-form responses into facts and validates them using Google Search for accuracy. #factcheckingai
This FAQ section clarifies key aspects of LongFact benchmarking, including reproducibility, SAFE evaluation, human error, recall measurement, & future research #factcheckingai

How SAFE Performs Compared to Human Annotations
hackernoon.com
April 10, 2025 at 7:00 AM
This FAQ section clarifies key aspects of LongFact benchmarking, including reproducibility, SAFE evaluation, human error, recall measurement, & future research #factcheckingai
DeepMind’s LongFact is a new dataset for testing AI’s factual accuracy in long-form, multi-paragraph responses across multiple topics. #factcheckingai

How LongFact Helps AI Models Improve Their Accuracy Across Multiple Topics
hackernoon.com
April 8, 2025 at 10:52 PM
DeepMind’s LongFact is a new dataset for testing AI’s factual accuracy in long-form, multi-paragraph responses across multiple topics. #factcheckingai
SAFE outperforms human annotators in factuality, achieving 76% accuracy on disagreements and offering 20x cost savings over crowdsourced human annotation.
#factcheckingai
#factcheckingai

Why LLMs Are More Accurate and Cost-Effective Than Human Fact-Checkers
hackernoon.com
April 8, 2025 at 10:54 PM
SAFE outperforms human annotators in factuality, achieving 76% accuracy on disagreements and offering 20x cost savings over crowdsourced human annotation.
#factcheckingai
#factcheckingai
Discover how scaling language models, RLHF, and incorrect human annotations impact long-form factuality evaluation. #factcheckingai

Analyzing the Impact of Model Scaling on Long-Form Factuality
hackernoon.com
April 11, 2025 at 7:00 AM
Discover how scaling language models, RLHF, and incorrect human annotations impact long-form factuality evaluation. #factcheckingai
Larger language models like GPT-4 and Gemini-Ultra outperform smaller models in long-form factuality, according to new benchmarks using SAFE and F1@K. #factcheckingai

GPT-4, Gemini-Ultra, and PaLM-2-L-IT-RLHF Top Long-Form Factuality Rankings
hackernoon.com
April 9, 2025 at 7:00 AM
Larger language models like GPT-4 and Gemini-Ultra outperform smaller models in long-form factuality, according to new benchmarks using SAFE and F1@K. #factcheckingai
Explore the LongFact data generation process, including topic selection, prompt creation, and examples from LongFact-Concepts and LongFact-Objects. #factcheckingai

How LongFact Helps Measure the Accuracy of AI Responses
hackernoon.com
April 10, 2025 at 9:00 AM
Explore the LongFact data generation process, including topic selection, prompt creation, and examples from LongFact-Concepts and LongFact-Objects. #factcheckingai
This paper benchmarks long-form factuality in large language models using SAFE—outperforming human annotators and offering insights into future LLM improvements #factcheckingai

Benchmarking Long-Form Factuality in Large Language Models
hackernoon.com
April 9, 2025 at 3:00 PM
This paper benchmarks long-form factuality in large language models using SAFE—outperforming human annotators and offering insights into future LLM improvements #factcheckingai
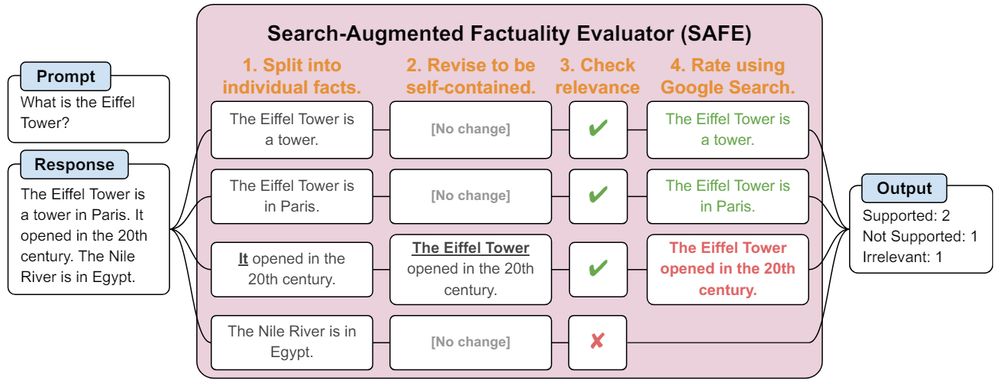
Explore SAFE’s language model-based fact-checking process for long-form factuality, from splitting responses into facts to rating support via Google Search. #factcheckingai

How AI Breaks Down and Validates Information for Truthfulness
hackernoon.com
April 10, 2025 at 11:00 AM
Explore SAFE’s language model-based fact-checking process for long-form factuality, from splitting responses into facts to rating support via Google Search. #factcheckingai
New DeepMind study introduces SAFE and LongFact to fact-check AI, showing LLMs can outperform humans at evaluating long-form factual responses. #factcheckingai
The AI Truth Test: New Study Tests the Accuracy of 13 Major AI Models
hackernoon.com
April 8, 2025 at 10:52 PM
New DeepMind study introduces SAFE and LongFact to fact-check AI, showing LLMs can outperform humans at evaluating long-form factual responses. #factcheckingai
Explore recent advancements in long-form factuality evaluation, from SAFE to F1@K, and how they compare with traditional benchmarks like FActScore and RAGAS. #factcheckingai

A Smarter Way to Check If AI Answers Are Correct
hackernoon.com
April 9, 2025 at 9:00 AM
Explore recent advancements in long-form factuality evaluation, from SAFE to F1@K, and how they compare with traditional benchmarks like FActScore and RAGAS. #factcheckingai

How to Outsmart AI: Catch AI's Lies in 5 Simple Steps
https://bytefeed.ai/technology/how-to-outsmart-ai-catch-ais-lies-in-5-simple-steps/
#VerifyTheTruth #FactCheckingAI #AIResearch
https://bytefeed.ai/technology/how-to-outsmart-ai-catch-ais-lies-in-5-simple-steps/
#VerifyTheTruth #FactCheckingAI #AIResearch

November 15, 2024 at 10:12 AM
How to Outsmart AI: Catch AI's Lies in 5 Simple Steps
https://bytefeed.ai/technology/how-to-outsmart-ai-catch-ais-lies-in-5-simple-steps/
#VerifyTheTruth #FactCheckingAI #AIResearch
https://bytefeed.ai/technology/how-to-outsmart-ai-catch-ais-lies-in-5-simple-steps/
#VerifyTheTruth #FactCheckingAI #AIResearch