by Jason Weston
Reposted by: Jason Weston
by Jason Weston — Reposted by: Luke Zettlemoyer
by Jason Weston
Reposted by: Jason Weston
by Jason Weston — Reposted by: Luke Zettlemoyer
Reposted by: Jason Weston
Reposted by: Jason Weston
by Jason Weston — Reposted by: Luke Zettlemoyer
Reposted by: Jason Weston

Introduces a new paradigm for LLM reasoning called Chain of Continuous Thought (COCONUT)
Directly feed the last hidden state (a continuous thought) as the input embedding for the next token.
arxiv.org/abs/2412.06769

Reposted by: Jason Weston
Reposted by: Jason Weston
Reposted by: Jason Weston
Reposted by: Jason Weston
by Jason Weston
Reposted by: Jason Weston, Kush R. Varshney
Reposted by: Jason Weston
Reposted by: Jason Weston
by Jason Weston

by Jason Weston
Our methods AD & Latent Pref Optimization are general & can be applied to train other hyperparams or latent features.
Excited how people could *adapt* this research!
🧵4/4
by Jason Weston
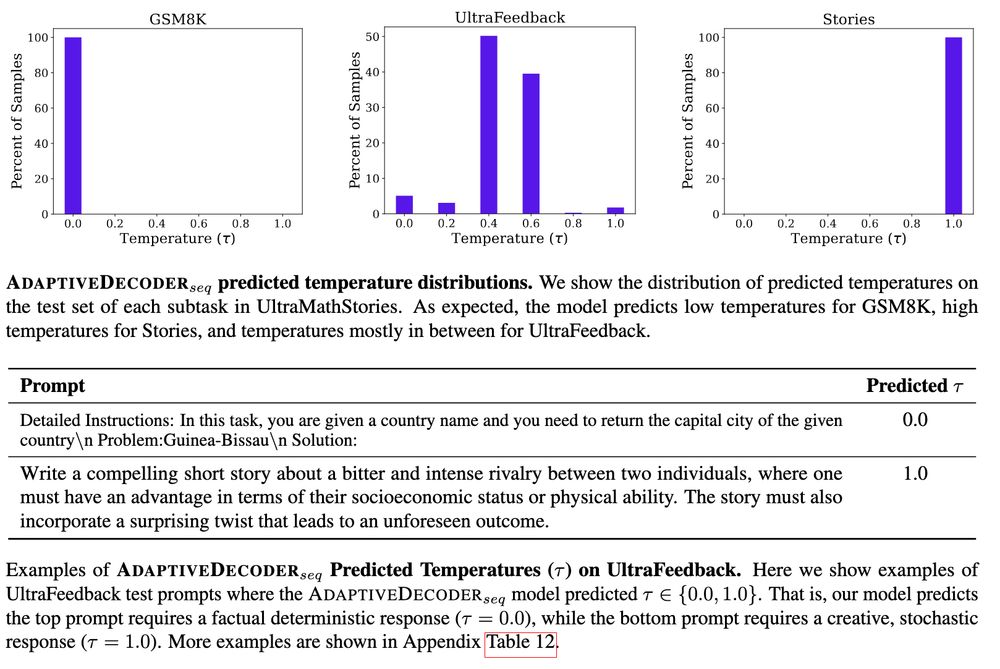
GSM8K - requires factuality (low temp)
Stories - requires creativity (high temp)
UltraFeedback - general instruction following, requires mix
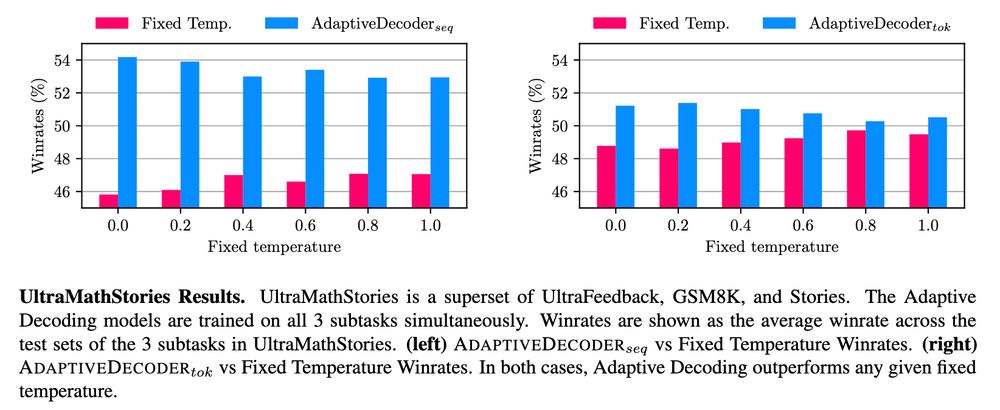
Results: Adaptive Decoding outperforms any fixed temperature, automatically choosing via the AD layer.
🧵3/4
by Jason Weston
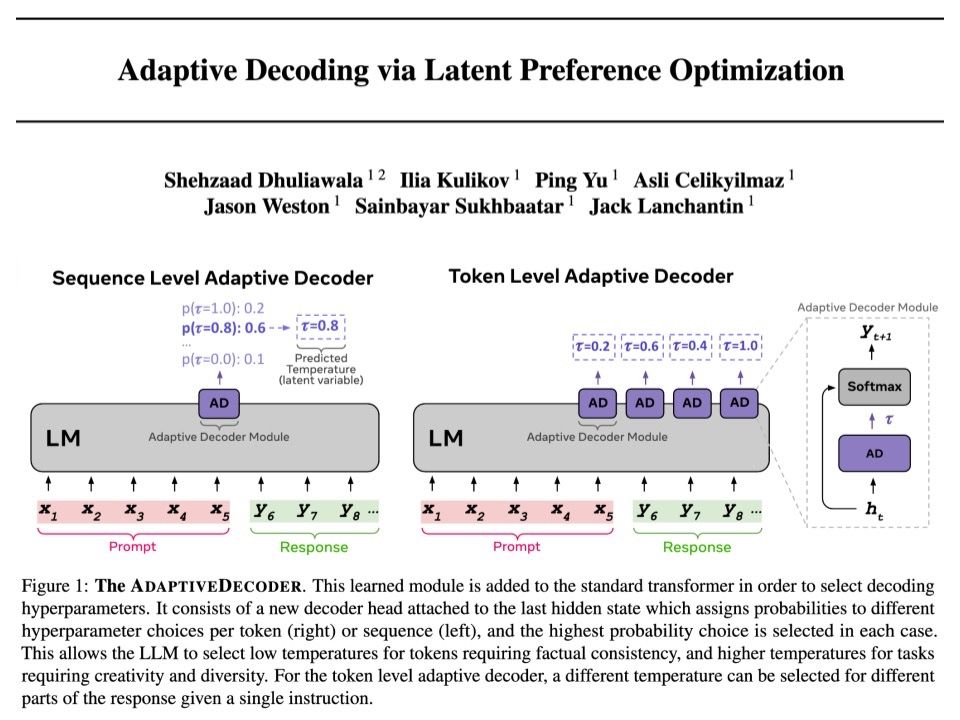
Adaptive Decoder (AD) Layer:
- Assigns probability to each hyperparam choice (decoding temp) given hidden state. Given temp, sample a token.
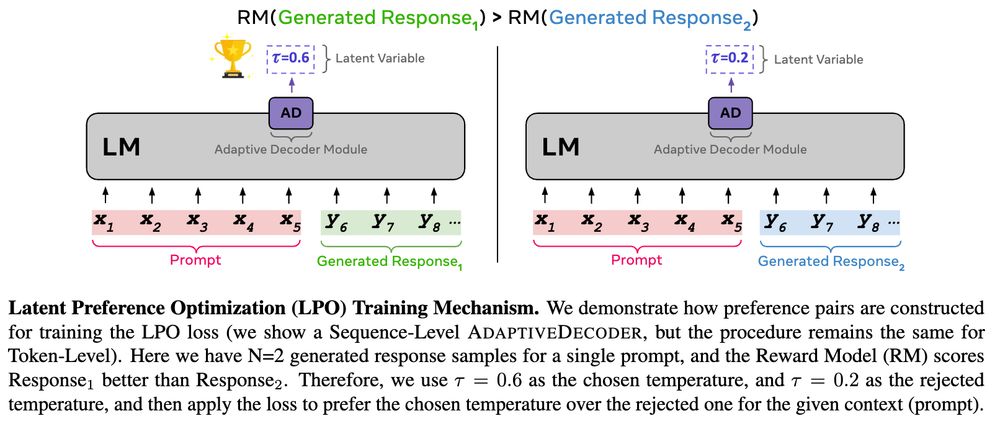
Training (Latent PO):
- Train AD by sampling params+tokens & use reward model on rejected hyperparam preference pairs
🧵2/4
by Jason Weston
- New layer for Transformer, selects decoding params automatically *per token*
- Learnt via new method Latent Preference Optimization
- Outperforms any fixed temperature decoding, choosing creativity or factuality
arxiv.org/abs/2411.09661
🧵1/4