Richard McElreath


Anyway great paper!

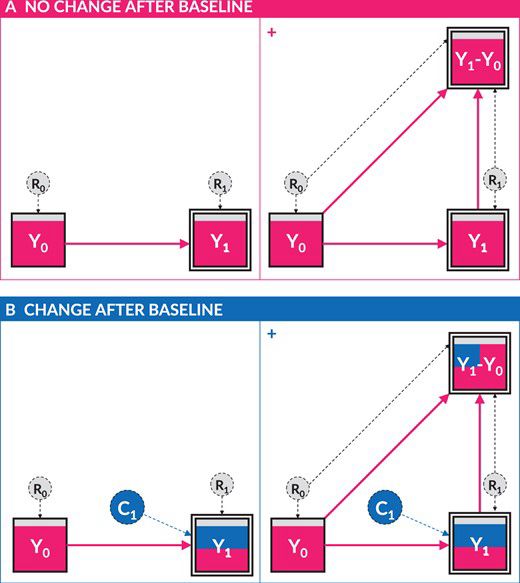
Reposted by: Richard McElreath, Jill A. Jacobson
Reposted by: Richard McElreath, Gordon Hodson, Martin Tomko , and 2 more Richard McElreath, Gordon Hodson, Martin Tomko, Barrett, Patrick Präg

You can sign up for the Zoom link here: tinyurl.com/CIIG-JuliaRo...

Reposted by: Richard McElreath, Paul Goldsmith-Pinkham, Barrett

Apply through the ELLIS PhD program (dl October 31) ellis.eu/news/ellis-p...





Reposted by: Richard McElreath, Ingo Rohlfing, Andreas Haupt
link.springer.com/article/10.1...




by Richard McElreath — Reposted by: David Rosnick

Reposted by: Richard McElreath, Frédéric Delsuc



There is no statistical philosophy in which those procedures are good for prediction or inference. Good for publishing though

Not going to be a movie anytime soon

X –> Z –> Y
can have highly correlated X and Z. But in model Y ~ X + Z it won't show any "collinearity"
by Richard McElreath — Reposted by: Richard Shaw, Jill A. Jacobson
