Superhero @jonasgeiping.bsky.social started architecture search for this two years ago, & wrote a distributed framework from scratch to handle bugs with AMD 🤯
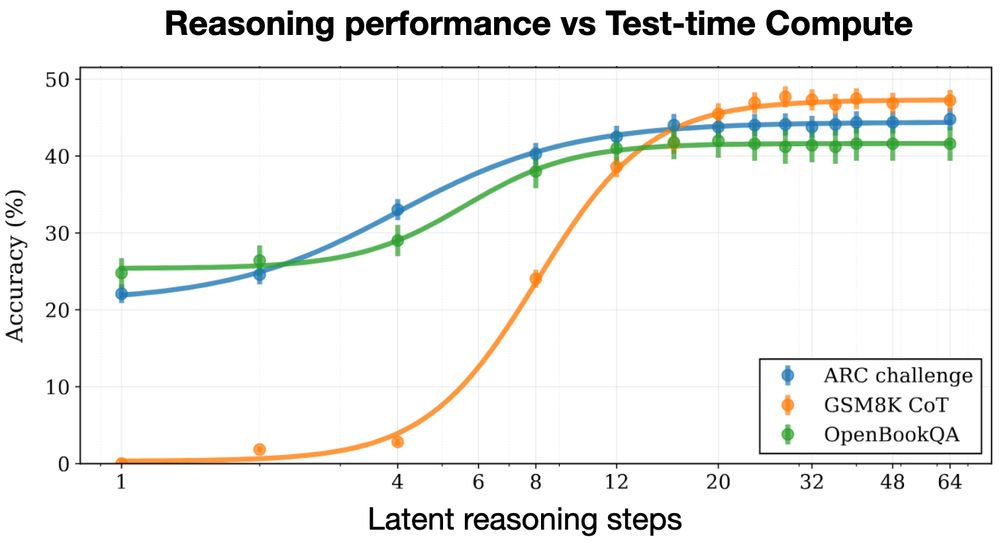
Huginn was built for reasoning from the ground up, not just fine-tuned on CoT.
We built our reasoning system by putting a recurrent block inside the LLM. On a forward pass, we loop this block a random number of times. By looping it more times, we dial up compute.
📢PSA: #NeurIPS2024 recordings are now publicly available!
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Here’s what doesn’t check out. They claim $5.5M by assuming a $2 per GPU-hour “rental cost”. On AWS, an H100 (with the same compute cores as an H800) costs $12.28/hour on demand, and $5.39 with a 3-year reservation. H800s are prob worth less, but…$2/hour? Idunno about that.
They'd need to eliminate token routing inefficiency and keep communication volume down (their H800 GPUs communicate slower than the H100s in the benchmark). They accomplish this using pipelined training, which industry labs prefer over the Pytorch FSDP implementation.
For 34B, Pytorch Foundation reports throughput of 1500 tokens/sec per GPU. With this throughput, DeepSeek’s 2.664M GPU-hour pre-training run would rip through 14.3T tokens. DeepSeek claims to have trained on 14.8T tokens. This part checks out...but only with killer engineering.