




Akari Asai
@akariasai.bsky.social
Ph.D. student at University of Washington CSE. NLP. IBM Ph.D. fellow (2022-2023). Meta student researcher (2023-) . ☕️ 🐕 🏃♀️🧗♀️🍳
Honored to be named to the Forbes 30 Under 30 Asia 2025 in Science!
Grateful for the recognition of my Ph.D. work on Retrieval-Augmented LMs, and excited to keep pushing the boundaries of reliable and efficient language models.
🔗 forbes.com/30-under-30/...
More updates soon… 👀
Grateful for the recognition of my Ph.D. work on Retrieval-Augmented LMs, and excited to keep pushing the boundaries of reliable and efficient language models.
🔗 forbes.com/30-under-30/...
More updates soon… 👀

Forbes 30 Under 30 2025: Healthcare & Science
Discovering new worlds, in our cells and outer space.
forbes.com
May 16, 2025 at 2:02 PM
Honored to be named to the Forbes 30 Under 30 Asia 2025 in Science!
Grateful for the recognition of my Ph.D. work on Retrieval-Augmented LMs, and excited to keep pushing the boundaries of reliable and efficient language models.
🔗 forbes.com/30-under-30/...
More updates soon… 👀
Grateful for the recognition of my Ph.D. work on Retrieval-Augmented LMs, and excited to keep pushing the boundaries of reliable and efficient language models.
🔗 forbes.com/30-under-30/...
More updates soon… 👀
Sad to miss #ICLR2025 this year, but my amazing co-authors will be there in person to present Pangea!
neulab.github.io/Pangea/
I’ll be at the Foundation Models for Science conference at Simons Foundation, NYC next week, then heading to NAACL (more details soon).
Let’s catch up if you’re around!✨
neulab.github.io/Pangea/
I’ll be at the Foundation Models for Science conference at Simons Foundation, NYC next week, then heading to NAACL (more details soon).
Let’s catch up if you’re around!✨

April 22, 2025 at 12:42 AM
Sad to miss #ICLR2025 this year, but my amazing co-authors will be there in person to present Pangea!
neulab.github.io/Pangea/
I’ll be at the Foundation Models for Science conference at Simons Foundation, NYC next week, then heading to NAACL (more details soon).
Let’s catch up if you’re around!✨
neulab.github.io/Pangea/
I’ll be at the Foundation Models for Science conference at Simons Foundation, NYC next week, then heading to NAACL (more details soon).
Let’s catch up if you’re around!✨
Real user queries often look different from the clean, concise ones in academic benchmarks - ambiguity, full of typos, and much less readable.
We show that even strong RAG systems quickly break under these conditions.
Awesome project led by
@neelbhandari.bsky.social and @tianyucao.bsky.social!!
We show that even strong RAG systems quickly break under these conditions.
Awesome project led by
@neelbhandari.bsky.social and @tianyucao.bsky.social!!

1/🚨 𝗡𝗲𝘄 𝗽𝗮𝗽𝗲𝗿 𝗮𝗹𝗲𝗿𝘁 🚨
RAG systems excel on academic benchmarks - but are they robust to variations in linguistic style?
We find RAG systems are brittle. Small shifts in phrasing trigger cascading errors, driven by the complexity of the RAG pipeline 🧵
RAG systems excel on academic benchmarks - but are they robust to variations in linguistic style?
We find RAG systems are brittle. Small shifts in phrasing trigger cascading errors, driven by the complexity of the RAG pipeline 🧵

April 22, 2025 at 12:27 AM
Real user queries often look different from the clean, concise ones in academic benchmarks - ambiguity, full of typos, and much less readable.
We show that even strong RAG systems quickly break under these conditions.
Awesome project led by
@neelbhandari.bsky.social and @tianyucao.bsky.social!!
We show that even strong RAG systems quickly break under these conditions.
Awesome project led by
@neelbhandari.bsky.social and @tianyucao.bsky.social!!
Reposted by Akari Asai

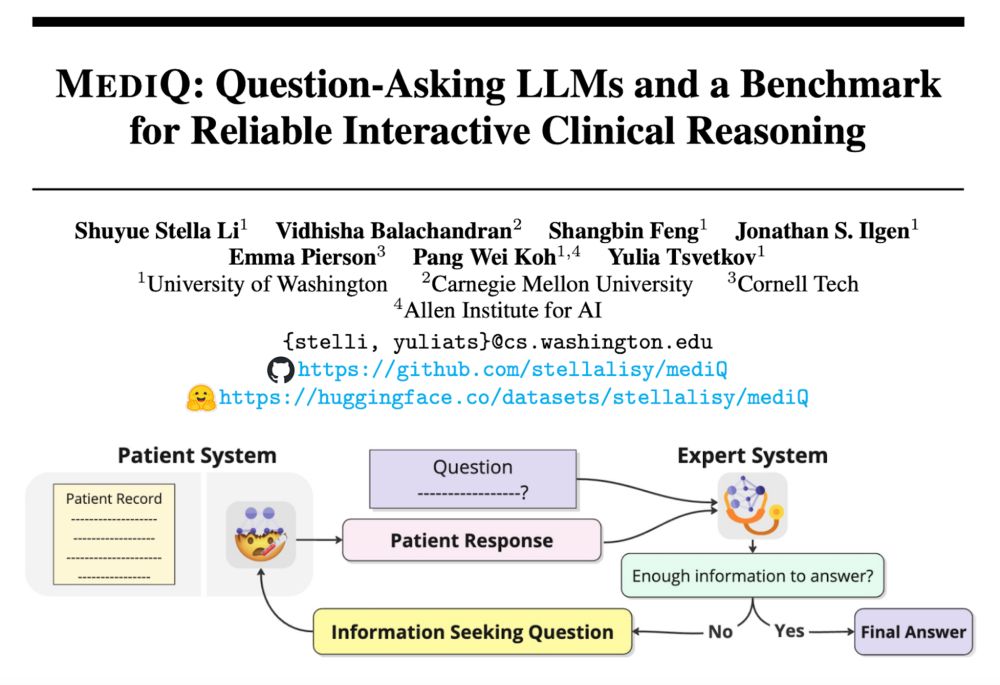
31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
December 6, 2024 at 10:51 PM
31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
CopyBench (EMNLP 2024, led by @tomchen0112.bsky.social)
Oral at regulatableml.github.io & Poster at redteaming-gen-ai.github.io
tldr: We benchmarked LLMs' literal/non-literal copying of copyrighted content—risks found even in 8B models.
Detais: www.arxiv.org/abs/2407.07087
Oral at regulatableml.github.io & Poster at redteaming-gen-ai.github.io
tldr: We benchmarked LLMs' literal/non-literal copying of copyrighted content—risks found even in 8B models.
Detais: www.arxiv.org/abs/2407.07087
The 2nd Workshop on Regulatable ML @NeurIPS2024
Towards Bridging the Gaps between Machine Learning Research and Regulations
regulatableml.github.io
December 8, 2024 at 2:55 AM
CopyBench (EMNLP 2024, led by @tomchen0112.bsky.social)
Oral at regulatableml.github.io & Poster at redteaming-gen-ai.github.io
tldr: We benchmarked LLMs' literal/non-literal copying of copyrighted content—risks found even in 8B models.
Detais: www.arxiv.org/abs/2407.07087
Oral at regulatableml.github.io & Poster at redteaming-gen-ai.github.io
tldr: We benchmarked LLMs' literal/non-literal copying of copyrighted content—risks found even in 8B models.
Detais: www.arxiv.org/abs/2407.07087
MassiveDS (led by @rulinshao.bsky.social) Wednesday Poster at 11-2 pm at West Ballroom#7203
TLDR: We demonstrated scaling retrieval corpora of Retrieval-Augmented LMs to 1.4T helps & achieves more compute-optimal scaling
Details: retrievalscaling.github.io
TLDR: We demonstrated scaling retrieval corpora of Retrieval-Augmented LMs to 1.4T helps & achieves more compute-optimal scaling
Details: retrievalscaling.github.io

December 8, 2024 at 2:54 AM
MassiveDS (led by @rulinshao.bsky.social) Wednesday Poster at 11-2 pm at West Ballroom#7203
TLDR: We demonstrated scaling retrieval corpora of Retrieval-Augmented LMs to 1.4T helps & achieves more compute-optimal scaling
Details: retrievalscaling.github.io
TLDR: We demonstrated scaling retrieval corpora of Retrieval-Augmented LMs to 1.4T helps & achieves more compute-optimal scaling
Details: retrievalscaling.github.io
Excited to attend #NeurIPS2024 in person! I’ll be presenting MassiveDS and CopyBench. Details below 🧵👇
Let’s catch up and chat about:
- LLMs & Retrieval-Augmented/Augmented LMs
- LLM Applications for science (e.g., OpenScholar) & others
- Ph.D./faculty apps
...and more!
Let’s catch up and chat about:
- LLMs & Retrieval-Augmented/Augmented LMs
- LLM Applications for science (e.g., OpenScholar) & others
- Ph.D./faculty apps
...and more!
December 8, 2024 at 2:52 AM
Excited to attend #NeurIPS2024 in person! I’ll be presenting MassiveDS and CopyBench. Details below 🧵👇
Let’s catch up and chat about:
- LLMs & Retrieval-Augmented/Augmented LMs
- LLM Applications for science (e.g., OpenScholar) & others
- Ph.D./faculty apps
...and more!
Let’s catch up and chat about:
- LLMs & Retrieval-Augmented/Augmented LMs
- LLM Applications for science (e.g., OpenScholar) & others
- Ph.D./faculty apps
...and more!
Oh that's a screenshot of my website. Here's link to my CV akariasai.github.io/assets/pdf/a...
akariasai.github.io
December 6, 2024 at 4:34 AM
Oh that's a screenshot of my website. Here's link to my CV akariasai.github.io/assets/pdf/a...
I would love to hear about any opportunities that might be a good fit!! You can find my contact info and CV on my website. akariasai.github.io. I am attending NeurIPS in person so let’s chat!
Akari Asai
A 5th year Ph.D. student at University of Washington, focusing on NLP and ML.
akariasai.github.io
December 4, 2024 at 1:31 PM
I would love to hear about any opportunities that might be a good fit!! You can find my contact info and CV on my website. akariasai.github.io. I am attending NeurIPS in person so let’s chat!
🏆 Recognition & Impact: My work has earned EECS Rising Stars 2022, the MIT Tech Review Innovator Award (Japan 2024), paper awards at ACL & NeurIPS, and the IBM Fellowship. My work has been featured in medias like MIT Tech Review, Forbes and VentureBeat.
December 4, 2024 at 1:31 PM
🏆 Recognition & Impact: My work has earned EECS Rising Stars 2022, the MIT Tech Review Innovator Award (Japan 2024), paper awards at ACL & NeurIPS, and the IBM Fellowship. My work has been featured in medias like MIT Tech Review, Forbes and VentureBeat.
🌍 Making Real-World Impacts
Retrieval-Augmented LMs tackle critical challenges like:
1️⃣ Unreliable LMs in expert domains
2️⃣ Information access inequity across languages
I launched OpenScholar for scientific synthesis—20k+ demo requests in week 1! Details: allenai.org/blog/opensch...
Retrieval-Augmented LMs tackle critical challenges like:
1️⃣ Unreliable LMs in expert domains
2️⃣ Information access inequity across languages
I launched OpenScholar for scientific synthesis—20k+ demo requests in week 1! Details: allenai.org/blog/opensch...

Ai2 OpenScholar: Scientific literature synthesis with retrieval-augmented language models | Ai2
Ai2’s & UW’s OpenScholar, a retrieval-augmented LM, helps scientists navigate and synthesize scientific literature.
allenai.org
December 4, 2024 at 1:30 PM
🌍 Making Real-World Impacts
Retrieval-Augmented LMs tackle critical challenges like:
1️⃣ Unreliable LMs in expert domains
2️⃣ Information access inequity across languages
I launched OpenScholar for scientific synthesis—20k+ demo requests in week 1! Details: allenai.org/blog/opensch...
Retrieval-Augmented LMs tackle critical challenges like:
1️⃣ Unreliable LMs in expert domains
2️⃣ Information access inequity across languages
I launched OpenScholar for scientific synthesis—20k+ demo requests in week 1! Details: allenai.org/blog/opensch...
🛠 Building the Foundations:
Retrieval-augmented LMs need more than off-the-shelf models. I developed advanced training/inference algorithms & architectures, including Self-RAG (ICLR 2024 Oral; NeurIPS Workshop Hon. Mention) for adaptive retrieval & self-critique.
Learn more:
selfrag.github.io
Retrieval-augmented LMs need more than off-the-shelf models. I developed advanced training/inference algorithms & architectures, including Self-RAG (ICLR 2024 Oral; NeurIPS Workshop Hon. Mention) for adaptive retrieval & self-critique.
Learn more:
selfrag.github.io
Self-RAG: Learning to Retrieve, Generate and Critique through Self-Reflection
Self-RAG: Learning to Retrieve, Generate and Critique through Self-Reflection.
selfrag.github.io
December 4, 2024 at 1:30 PM
🛠 Building the Foundations:
Retrieval-augmented LMs need more than off-the-shelf models. I developed advanced training/inference algorithms & architectures, including Self-RAG (ICLR 2024 Oral; NeurIPS Workshop Hon. Mention) for adaptive retrieval & self-critique.
Learn more:
selfrag.github.io
Retrieval-augmented LMs need more than off-the-shelf models. I developed advanced training/inference algorithms & architectures, including Self-RAG (ICLR 2024 Oral; NeurIPS Workshop Hon. Mention) for adaptive retrieval & self-critique.
Learn more:
selfrag.github.io
🔍 Establishing the Necessity
My work showed that scaling LLMs alone doesn’t solve issues like hallucinations or obsolete knowledge and is compute suboptimal, and Retrieval-Augmented LMs address these challenges. See our ACL 2023 Best Video Award paper:
aclanthology.org/2023.acl-lon...
My work showed that scaling LLMs alone doesn’t solve issues like hallucinations or obsolete knowledge and is compute suboptimal, and Retrieval-Augmented LMs address these challenges. See our ACL 2023 Best Video Award paper:
aclanthology.org/2023.acl-lon...

When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, Hannaneh Hajishirzi. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
aclanthology.org
December 4, 2024 at 1:27 PM
🔍 Establishing the Necessity
My work showed that scaling LLMs alone doesn’t solve issues like hallucinations or obsolete knowledge and is compute suboptimal, and Retrieval-Augmented LMs address these challenges. See our ACL 2023 Best Video Award paper:
aclanthology.org/2023.acl-lon...
My work showed that scaling LLMs alone doesn’t solve issues like hallucinations or obsolete knowledge and is compute suboptimal, and Retrieval-Augmented LMs address these challenges. See our ACL 2023 Best Video Award paper:
aclanthology.org/2023.acl-lon...
I’m on the academic job market this year! I’m completing my @uwcse.bsky.social @uwnlp.bsky.social Ph.D. (2025), focusing on overcoming LLM limitations like hallucinations, by building new LMs.
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵

December 4, 2024 at 1:26 PM
I’m on the academic job market this year! I’m completing my @uwcse.bsky.social @uwnlp.bsky.social Ph.D. (2025), focusing on overcoming LLM limitations like hallucinations, by building new LMs.
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
My Ph.D. work focuses on Retrieval-Augmented LMs to create more reliable AI systems 🧵
Reposted by Akari Asai

congrats @akariasai.bsky.social:
🔬 retrieval augmented LM for science literature
🧬 open data, weights, index, code, etc
⚗️ new eval suite for science literature tasks
🔭 demo to play w the model
encourage checking out to see what scientific LMs can/cant do today w open research artifacts
🔬 retrieval augmented LM for science literature
🧬 open data, weights, index, code, etc
⚗️ new eval suite for science literature tasks
🔭 demo to play w the model
encourage checking out to see what scientific LMs can/cant do today w open research artifacts
1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
November 19, 2024 at 5:00 PM
congrats @akariasai.bsky.social:
🔬 retrieval augmented LM for science literature
🧬 open data, weights, index, code, etc
⚗️ new eval suite for science literature tasks
🔭 demo to play w the model
encourage checking out to see what scientific LMs can/cant do today w open research artifacts
🔬 retrieval augmented LM for science literature
🧬 open data, weights, index, code, etc
⚗️ new eval suite for science literature tasks
🔭 demo to play w the model
encourage checking out to see what scientific LMs can/cant do today w open research artifacts
Reposted by Akari Asai

Super exciting RAG prototype @akariasai.bsky.social build on top of Semantic Scholar!
I love how it returns competent research answers for seemingly out CS domain questions, eg “what’s a bell?” openscholar.allen.ai/query/69cf13...
it’s good in domain too 😉
I love how it returns competent research answers for seemingly out CS domain questions, eg “what’s a bell?” openscholar.allen.ai/query/69cf13...
it’s good in domain too 😉
1/ Introducing ᴏᴘᴇɴꜱᴄʜᴏʟᴀʀ: a retrieval-augmented LM to help scientists synthesize knowledge 📚
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
@uwnlp.bsky.social & Ai2
With open models & 45M-paper datastores, it outperforms proprietary systems & match human experts.
Try out our demo!
openscholar.allen.ai
November 19, 2024 at 5:01 PM
Super exciting RAG prototype @akariasai.bsky.social build on top of Semantic Scholar!
I love how it returns competent research answers for seemingly out CS domain questions, eg “what’s a bell?” openscholar.allen.ai/query/69cf13...
it’s good in domain too 😉
I love how it returns competent research answers for seemingly out CS domain questions, eg “what’s a bell?” openscholar.allen.ai/query/69cf13...
it’s good in domain too 😉
Reposted by Akari Asai

I'm recruiting 1-2 PhD students to work with me at the University of Colorado Boulder! Looking for creative students with interests in #NLP and #CulturalAnalytics.
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!

November 19, 2024 at 10:38 AM
I'm recruiting 1-2 PhD students to work with me at the University of Colorado Boulder! Looking for creative students with interests in #NLP and #CulturalAnalytics.
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
Boulder is a lovely college town 30 minutes from Denver and 1 hour from Rocky Mountain National Park 😎
Apply by December 15th!
8/ ❤️Acknowledgements:
OpenScholar is the result of a collaborative effort UW, Ai2 and many others!
Huge thanks to our incredible team including experts from CS, Bio, and physics, for making this possible!
We’d love your feedback! Reply or email us with questions, ideas, or use cases✨
OpenScholar is the result of a collaborative effort UW, Ai2 and many others!
Huge thanks to our incredible team including experts from CS, Bio, and physics, for making this possible!
We’d love your feedback! Reply or email us with questions, ideas, or use cases✨
November 19, 2024 at 4:33 PM
8/ ❤️Acknowledgements:
OpenScholar is the result of a collaborative effort UW, Ai2 and many others!
Huge thanks to our incredible team including experts from CS, Bio, and physics, for making this possible!
We’d love your feedback! Reply or email us with questions, ideas, or use cases✨
OpenScholar is the result of a collaborative effort UW, Ai2 and many others!
Huge thanks to our incredible team including experts from CS, Bio, and physics, for making this possible!
We’d love your feedback! Reply or email us with questions, ideas, or use cases✨
8/ 🧪 Summary
Try it out: openscholar.allen.ai
Read more: allenai.org/blog/opensch... – we discuss more details as well as limitations of OpenScholar, based on our beta testing with CS researchers!
Code & data: github.com/AkariAsai/Op...
Paper: openscholar.allen.ai/paper
Try it out: openscholar.allen.ai
Read more: allenai.org/blog/opensch... – we discuss more details as well as limitations of OpenScholar, based on our beta testing with CS researchers!
Code & data: github.com/AkariAsai/Op...
Paper: openscholar.allen.ai/paper
Ai2 OpenScholar
openscholar.allen.ai
November 19, 2024 at 4:33 PM
8/ 🧪 Summary
Try it out: openscholar.allen.ai
Read more: allenai.org/blog/opensch... – we discuss more details as well as limitations of OpenScholar, based on our beta testing with CS researchers!
Code & data: github.com/AkariAsai/Op...
Paper: openscholar.allen.ai/paper
Try it out: openscholar.allen.ai
Read more: allenai.org/blog/opensch... – we discuss more details as well as limitations of OpenScholar, based on our beta testing with CS researchers!
Code & data: github.com/AkariAsai/Op...
Paper: openscholar.allen.ai/paper
7/ 🌐 What’s next?
We're just getting started with OpenScholar! 🚀
Expanding domains: Support for non-CS fields is coming soon. Public API: Full-text search over 45M+ papers will be available shortly.
Try the OpenScholar demo and share your feedback!
openscholar.allen.ai
We're just getting started with OpenScholar! 🚀
Expanding domains: Support for non-CS fields is coming soon. Public API: Full-text search over 45M+ papers will be available shortly.
Try the OpenScholar demo and share your feedback!
openscholar.allen.ai
Ai2 OpenScholar
openscholar.allen.ai
November 19, 2024 at 4:33 PM
7/ 🌐 What’s next?
We're just getting started with OpenScholar! 🚀
Expanding domains: Support for non-CS fields is coming soon. Public API: Full-text search over 45M+ papers will be available shortly.
Try the OpenScholar demo and share your feedback!
openscholar.allen.ai
We're just getting started with OpenScholar! 🚀
Expanding domains: Support for non-CS fields is coming soon. Public API: Full-text search over 45M+ papers will be available shortly.
Try the OpenScholar demo and share your feedback!
openscholar.allen.ai
6/ 💾 Open Access [2]:
📂 OpenScholar Datastore (45M+ papers up to 2024/10): huggingface.co/datasets/Ope...
📊 ScholarQABench: github.com/AkariAsai/Sc...
👩🔬 Human evaluation interface: github.com/AkariAsai/Op...
📂 OpenScholar Datastore (45M+ papers up to 2024/10): huggingface.co/datasets/Ope...
📊 ScholarQABench: github.com/AkariAsai/Sc...
👩🔬 Human evaluation interface: github.com/AkariAsai/Op...
Ai2 OpenScholar
openscholar.allen.ai
November 19, 2024 at 4:33 PM
6/ 💾 Open Access [2]:
📂 OpenScholar Datastore (45M+ papers up to 2024/10): huggingface.co/datasets/Ope...
📊 ScholarQABench: github.com/AkariAsai/Sc...
👩🔬 Human evaluation interface: github.com/AkariAsai/Op...
📂 OpenScholar Datastore (45M+ papers up to 2024/10): huggingface.co/datasets/Ope...
📊 ScholarQABench: github.com/AkariAsai/Sc...
👩🔬 Human evaluation interface: github.com/AkariAsai/Op...
6/ 💾 Open Access [1]:
Prior work in this area has relied on proprietary LMs and/or released only a subset of datastore
We're releasing
Demo: openscholar.allen.ai
🔓 Code & model checkpoints:
github.com/AkariAsai/Op...
huggingface.co/collections/...
Prior work in this area has relied on proprietary LMs and/or released only a subset of datastore
We're releasing
Demo: openscholar.allen.ai
🔓 Code & model checkpoints:
github.com/AkariAsai/Op...
huggingface.co/collections/...
Ai2 OpenScholar
openscholar.allen.ai
November 19, 2024 at 4:33 PM
6/ 💾 Open Access [1]:
Prior work in this area has relied on proprietary LMs and/or released only a subset of datastore
We're releasing
Demo: openscholar.allen.ai
🔓 Code & model checkpoints:
github.com/AkariAsai/Op...
huggingface.co/collections/...
Prior work in this area has relied on proprietary LMs and/or released only a subset of datastore
We're releasing
Demo: openscholar.allen.ai
🔓 Code & model checkpoints:
github.com/AkariAsai/Op...
huggingface.co/collections/...
5/ 📊 Exert Evaluation Results:
We further conduct expert evaluations with scientists across CS, Bio and Physics, comparing OS against expert answers.
Scientists preferred OpenScholar-8B outputs compared to human-written answers in majority of the times, thanks to its coverage
We further conduct expert evaluations with scientists across CS, Bio and Physics, comparing OS against expert answers.
Scientists preferred OpenScholar-8B outputs compared to human-written answers in majority of the times, thanks to its coverage

November 19, 2024 at 4:33 PM
5/ 📊 Exert Evaluation Results:
We further conduct expert evaluations with scientists across CS, Bio and Physics, comparing OS against expert answers.
Scientists preferred OpenScholar-8B outputs compared to human-written answers in majority of the times, thanks to its coverage
We further conduct expert evaluations with scientists across CS, Bio and Physics, comparing OS against expert answers.
Scientists preferred OpenScholar-8B outputs compared to human-written answers in majority of the times, thanks to its coverage
5/ 📊 Automatic Results:
So how good OpenScholar?
On ScholarBench, OpenScholar-8B surpassed GPT-4o, concurrent PaperQA2, and other models in factuality & citation accuracy despite being many times cheaper!
So how good OpenScholar?
On ScholarBench, OpenScholar-8B surpassed GPT-4o, concurrent PaperQA2, and other models in factuality & citation accuracy despite being many times cheaper!
November 19, 2024 at 4:33 PM
5/ 📊 Automatic Results:
So how good OpenScholar?
On ScholarBench, OpenScholar-8B surpassed GPT-4o, concurrent PaperQA2, and other models in factuality & citation accuracy despite being many times cheaper!
So how good OpenScholar?
On ScholarBench, OpenScholar-8B surpassed GPT-4o, concurrent PaperQA2, and other models in factuality & citation accuracy despite being many times cheaper!
4/ 🧪New dataset: ScholarBench
A benchmark for evaluating scientific language models on real-world, open-ended questions requiring synthesis across multiple papers. 🌟
📚 7 datasets across four scientific disciplines
🧑🔬 2,000+ expert-annotated question and 200 answers
📊 Automated metrics
A benchmark for evaluating scientific language models on real-world, open-ended questions requiring synthesis across multiple papers. 🌟
📚 7 datasets across four scientific disciplines
🧑🔬 2,000+ expert-annotated question and 200 answers
📊 Automated metrics

November 19, 2024 at 4:33 PM
4/ 🧪New dataset: ScholarBench
A benchmark for evaluating scientific language models on real-world, open-ended questions requiring synthesis across multiple papers. 🌟
📚 7 datasets across four scientific disciplines
🧑🔬 2,000+ expert-annotated question and 200 answers
📊 Automated metrics
A benchmark for evaluating scientific language models on real-world, open-ended questions requiring synthesis across multiple papers. 🌟
📚 7 datasets across four scientific disciplines
🧑🔬 2,000+ expert-annotated question and 200 answers
📊 Automated metrics