



Alex Bradbury
@asbradbury.org
Compilers at Igalia. @llvmweekly.org author. Mostly RISC-V, LLVM, and a little WebAssembly. Previously lowRISC CTO and co-founder. Blogs at https://muxup.com
Reposted by Alex Bradbury

A video and notebook on a short Introduction to SMT solvers
colab.research.google.com/github/philz...
www.youtube.com/watch?v=cI2s...
colab.research.google.com/github/philz...
www.youtube.com/watch?v=cI2s...

Google Colab
colab.research.google.com
January 14, 2026 at 7:55 PM
A video and notebook on a short Introduction to SMT solvers
colab.research.google.com/github/philz...
www.youtube.com/watch?v=cI2s...
colab.research.google.com/github/philz...
www.youtube.com/watch?v=cI2s...
Reposted by Alex Bradbury

64% of WebKit non-Apple contributions, 20% of Chromium non-Google, 27% of Servo, 39% of test262, and it goes on.
And doing all this as a worker-owned, employee-run cooperative. The world would be a very different place if companies like Igalia were the norm rather than the exception in tech.
And doing all this as a worker-owned, employee-run cooperative. The world would be a very different place if companies like Igalia were the norm rather than the exception in tech.
We analyzed Igalia's contributions to some of our favorite open-source projects on the web and elsewhere and summarized them in this blog post! Check it out: www.igalia.com/2026/01/05/D...

Doing Our Share for the Web in 2025 | Igalia
Igalia is an open source consultancy specialised in the development of innovative projects and solutions. Our engineers have expertise in a wide range of technological areas, including browsers and cl...
www.igalia.com
January 12, 2026 at 7:44 PM
64% of WebKit non-Apple contributions, 20% of Chromium non-Google, 27% of Servo, 39% of test262, and it goes on.
And doing all this as a worker-owned, employee-run cooperative. The world would be a very different place if companies like Igalia were the norm rather than the exception in tech.
And doing all this as a worker-owned, employee-run cooperative. The world would be a very different place if companies like Igalia were the norm rather than the exception in tech.
Reposted by Alex Bradbury

Nikita Popov (who sadly isn't on Bluesky) has a great new post. LLVM: The bad parts www.npopov.com/2026/01/11/L...
LLVM: The bad parts
www.npopov.com
January 11, 2026 at 7:26 PM
Nikita Popov (who sadly isn't on Bluesky) has a great new post. LLVM: The bad parts www.npopov.com/2026/01/11/L...
The move to 'forkserver' as the default start method for ProcessPoolExecutor in Python 3.14 is quite a gotcha docs.python.org/3/whatsnew/3... My code was probably broken on MacOS and Windows anyway due to those platforms defaulting to the 'spawn' method.

What’s new in Python 3.14
Editors, Adam Turner and Hugo van Kemenade,. This article explains the new features in Python 3.14, compared to 3.13. Python 3.14 was released on 7 October 2025. For full details, see the changelog...
docs.python.org
January 11, 2026 at 8:18 AM
The move to 'forkserver' as the default start method for ProcessPoolExecutor in Python 3.14 is quite a gotcha docs.python.org/3/whatsnew/3... My code was probably broken on MacOS and Windows anyway due to those platforms defaulting to the 'spawn' method.
Reposted by Alex Bradbury
If we try to use the benchmark results from InferenceMAX to calculate a Watt-hours per LLM query, what do we get? What potential issues are there with the benchmark for this purpose (or in general)? My new post explores this muxup.com/2026q1/per-q...

Per-query energy consumption of LLMs
Can we reasonably use the InferenceMAX benchmark dataset to get a Wh per query figure?
muxup.com
January 7, 2026 at 8:34 PM
If we try to use the benchmark results from InferenceMAX to calculate a Watt-hours per LLM query, what do we get? What potential issues are there with the benchmark for this purpose (or in general)? My new post explores this muxup.com/2026q1/per-q...
If we try to use the benchmark results from InferenceMAX to calculate a Watt-hours per LLM query, what do we get? What potential issues are there with the benchmark for this purpose (or in general)? My new post explores this muxup.com/2026q1/per-q...
Per-query energy consumption of LLMs
Can we reasonably use the InferenceMAX benchmark dataset to get a Wh per query figure?
muxup.com
January 7, 2026 at 8:34 PM
If we try to use the benchmark results from InferenceMAX to calculate a Watt-hours per LLM query, what do we get? What potential issues are there with the benchmark for this purpose (or in general)? My new post explores this muxup.com/2026q1/per-q...
Reposted by Alex Bradbury
LLVM Weekly - #627, January 5th 2026. Twelve years of LLVM Weekly, EuroLLVM CfP closing soon, GNU toolchain in 2025 summary, PCH to speed-up LLVM builds, LLVM ABI lowering library starting to land, and more llvmweekly.org/issue/627
LLVM Weekly - #627, January 5th 2026
llvmweekly.org
January 5, 2026 at 4:49 PM
LLVM Weekly - #627, January 5th 2026. Twelve years of LLVM Weekly, EuroLLVM CfP closing soon, GNU toolchain in 2025 summary, PCH to speed-up LLVM builds, LLVM ABI lowering library starting to land, and more llvmweekly.org/issue/627
Reposted by Alex Bradbury

Finished two retrospective blog posts on the journey of require(esm) before 2025 ends:
joyeecheung.github.io/blog/2025/12...
joyeecheung.github.io/blog/2025/12...
joyeecheung.github.io/blog/2025/12...
joyeecheung.github.io/blog/2025/12...

require(esm) in Node.js: from experiment to stability
More than a year ago, I set out to revive require(esm) in Node.js and landed an experimental implementation. After a lot of iteration and battle-testing, require(esm) is now unflagged across all suppo
joyeecheung.github.io
December 30, 2025 at 7:04 PM
Finished two retrospective blog posts on the journey of require(esm) before 2025 ends:
joyeecheung.github.io/blog/2025/12...
joyeecheung.github.io/blog/2025/12...
joyeecheung.github.io/blog/2025/12...
joyeecheung.github.io/blog/2025/12...
Wake up babe, new proposed RISC-V base ISA names just dropped. lists.riscv.org/g/tech-unpri...
How long until we see an rv32lbefx_mafc_zicntr_zicsr_zifencei_zba_zbb_zbs_zca_zfa in the wild?
How long until we see an rv32lbefx_mafc_zicntr_zicsr_zifencei_zba_zbb_zbs_zca_zfa in the wild?
lists.riscv.org
December 20, 2025 at 4:34 PM
Wake up babe, new proposed RISC-V base ISA names just dropped. lists.riscv.org/g/tech-unpri...
How long until we see an rv32lbefx_mafc_zicntr_zicsr_zifencei_zba_zbb_zbs_zca_zfa in the wild?
How long until we see an rv32lbefx_mafc_zicntr_zicsr_zifencei_zba_zbb_zbs_zca_zfa in the wild?
Reposted by Alex Bradbury

There has been outrage as the @acm.org rolls out AI generated summaries of papers. This is doing AI exactly wrong by replacing valuable, peer-reviewed content with a possibly inaccurate summary. It's still not too late to correct it though and use AI responsibly... anil.recoil.org/notes/acm-ai...

Dear ACM, you're doing AI wrong but you can still get it right
anil.recoil.org
December 18, 2025 at 1:30 PM
There has been outrage as the @acm.org rolls out AI generated summaries of papers. This is doing AI exactly wrong by replacing valuable, peer-reviewed content with a possibly inaccurate summary. It's still not too late to correct it though and use AI responsibly... anil.recoil.org/notes/acm-ai...
Reposted by Alex Bradbury

The #LLVM developer room is back at #FOSDEM , on January 31st!
I'm excited about the variety in topics covered, from hardware generation using mlir/llvm to C/C++ repls.
Come join us either in-person in Brussels, or online through the live-feed which will be available at fosdem.org/2026/schedul...
I'm excited about the variety in topics covered, from hardware generation using mlir/llvm to C/C++ repls.
Come join us either in-person in Brussels, or online through the live-feed which will be available at fosdem.org/2026/schedul...
December 18, 2025 at 9:59 AM
The #LLVM developer room is back at #FOSDEM , on January 31st!
I'm excited about the variety in topics covered, from hardware generation using mlir/llvm to C/C++ repls.
Come join us either in-person in Brussels, or online through the live-feed which will be available at fosdem.org/2026/schedul...
I'm excited about the variety in topics covered, from hardware generation using mlir/llvm to C/C++ repls.
Come join us either in-person in Brussels, or online through the live-feed which will be available at fosdem.org/2026/schedul...
Reposted by Alex Bradbury
For my last few days of my Advent of Agentic Humps, I blended 50 different language ecosystem's HTTP clients to brew an OCaml Requests library. Agents figured out the random quirks needed for a client by getting advice from our friends in Java, Haskell, C, C#, Python anil.recoil.org/notes/aoah-2...

AoAH Day 13: Heckling an OCaml HTTP client from 50 implementations in 10 languages
Agentically synthesising a batteries-included OCaml HTTP client by gathering recommendations from fifty open-source implementations across JavaScript, Python, Java, Rust, Swift, Haskell, Go, C++, PHP ...
anil.recoil.org
December 14, 2025 at 5:23 PM
For my last few days of my Advent of Agentic Humps, I blended 50 different language ecosystem's HTTP clients to brew an OCaml Requests library. Agents figured out the random quirks needed for a client by getting advice from our friends in Java, Haskell, C, C#, Python anil.recoil.org/notes/aoah-2...
Reposted by Alex Bradbury

What a week! 😅 #LinuxPlumbers Conf 2025 is officially over, and what an edition it was.
We went all out this year, covering everything from Linux System Observability and Kernel Testing to Gaming and sched_ext!
Thanks to the organizers and everyone who joined our eight talks. See you next year! 👋🐧
We went all out this year, covering everything from Linux System Observability and Kernel Testing to Gaming and sched_ext!
Thanks to the organizers and everyone who joined our eight talks. See you next year! 👋🐧

December 13, 2025 at 2:45 PM
What a week! 😅 #LinuxPlumbers Conf 2025 is officially over, and what an edition it was.
We went all out this year, covering everything from Linux System Observability and Kernel Testing to Gaming and sched_ext!
Thanks to the organizers and everyone who joined our eight talks. See you next year! 👋🐧
We went all out this year, covering everything from Linux System Observability and Kernel Testing to Gaming and sched_ext!
Thanks to the organizers and everyone who joined our eight talks. See you next year! 👋🐧
Reposted by Alex Bradbury

Does LLVM produce slower RISC-V code than GCC? Currently, yes.
Can we make LLVM produce faster code? Also, yes!
lukelau.me/2025/12/10/c...
#llvm #riscv
Can we make LLVM produce faster code? Also, yes!
lukelau.me/2025/12/10/c...
#llvm #riscv
Closing the LLVM RISC-V gap to GCC, part 1
At the time of writing, GCC beats Clang on several SPEC CPU 2017 benchmarks on RISC-V1: Compiled with -march=rva22u64_v -O3 -flto, running the train ↩
lukelau.me
December 10, 2025 at 2:42 PM
Does LLVM produce slower RISC-V code than GCC? Currently, yes.
Can we make LLVM produce faster code? Also, yes!
lukelau.me/2025/12/10/c...
#llvm #riscv
Can we make LLVM produce faster code? Also, yes!
lukelau.me/2025/12/10/c...
#llvm #riscv
Reposted by Alex Bradbury

We''ve landed a few more talks since the last update!
* Sorrachai Yingchareonthawornchai: The CSLib initiative
* Simon Sorg: Machine learning for Lean
* Jannis Limperg on Lean metaprogramming for AI
* Will Turner on the new ProofBench effort
Come join us for a day of #lean! leaning.in
* Sorrachai Yingchareonthawornchai: The CSLib initiative
* Simon Sorg: Machine learning for Lean
* Jannis Limperg on Lean metaprogramming for AI
* Will Turner on the new ProofBench effort
Come join us for a day of #lean! leaning.in

Leaning In! 2026
A workshop for the Lean community - Thursday, March 12, 2026
leaning.in
December 8, 2025 at 10:16 AM
We''ve landed a few more talks since the last update!
* Sorrachai Yingchareonthawornchai: The CSLib initiative
* Simon Sorg: Machine learning for Lean
* Jannis Limperg on Lean metaprogramming for AI
* Will Turner on the new ProofBench effort
Come join us for a day of #lean! leaning.in
* Sorrachai Yingchareonthawornchai: The CSLib initiative
* Simon Sorg: Machine learning for Lean
* Jannis Limperg on Lean metaprogramming for AI
* Will Turner on the new ProofBench effort
Come join us for a day of #lean! leaning.in
Reposted by Alex Bradbury
I've started writing up the flow I use for capturing instruction execution frequency data from benchmarks using QEMU. First we focus on getting the necessary stats out of QEMU. Future posts will look at the scripting I use for analysis, and then examples of applying it. muxup.com/2025q4/qemu-...

QEMU-based instruction execution counting
Using QEMU to capture execution count for each translation block
muxup.com
December 3, 2025 at 12:14 AM
I've started writing up the flow I use for capturing instruction execution frequency data from benchmarks using QEMU. First we focus on getting the necessary stats out of QEMU. Future posts will look at the scripting I use for analysis, and then examples of applying it. muxup.com/2025q4/qemu-...
I've started writing up the flow I use for capturing instruction execution frequency data from benchmarks using QEMU. First we focus on getting the necessary stats out of QEMU. Future posts will look at the scripting I use for analysis, and then examples of applying it. muxup.com/2025q4/qemu-...
QEMU-based instruction execution counting
Using QEMU to capture execution count for each translation block
muxup.com
December 3, 2025 at 12:14 AM
I've started writing up the flow I use for capturing instruction execution frequency data from benchmarks using QEMU. First we focus on getting the necessary stats out of QEMU. Future posts will look at the scripting I use for analysis, and then examples of applying it. muxup.com/2025q4/qemu-...
I feel like I should implement footnotes on my blog, but I know I'll overuse them awfully (maybe that's preferable to my overuse of parenthetical comments though?) ^1
[1]: Or perhaps just equally annoying but in a different way
[1]: Or perhaps just equally annoying but in a different way
December 2, 2025 at 1:38 PM
I feel like I should implement footnotes on my blog, but I know I'll overuse them awfully (maybe that's preferable to my overuse of parenthetical comments though?) ^1
[1]: Or perhaps just equally annoying but in a different way
[1]: Or perhaps just equally annoying but in a different way
Some notes on the reported training costs (GWh for pre-training GPU compute) for the recently released @ai2.bsky.social Olmo 3 along with my attempt to contextualise that. muxup.com/2025q4/minip...
0.681 GWh for the GPUs in pre-training the 32B (not accounting for cooling etc).
0.681 GWh for the GPUs in pre-training the 32B (not accounting for cooling etc).

Minipost: Olmo 3 training cost
GPU hours and energy used in training the recent Olmo 3 models
muxup.com
December 2, 2025 at 12:11 AM
Some notes on the reported training costs (GWh for pre-training GPU compute) for the recently released @ai2.bsky.social Olmo 3 along with my attempt to contextualise that. muxup.com/2025q4/minip...
0.681 GWh for the GPUs in pre-training the 32B (not accounting for cooling etc).
0.681 GWh for the GPUs in pre-training the 32B (not accounting for cooling etc).
Reposted by Alex Bradbury
We just extended the deadline for the #LLVM dev room at #FOSDEM submissions until 7th of December. There's still time to make your submission at pretalx.fosdem.org/fosdem-2026/... !
Full CFP at discourse.llvm.org/t/88746
Full CFP at discourse.llvm.org/t/88746
FOSDEM 2026
Schedule, talks and talk submissions for FOSDEM 2026
pretalx.fosdem.org
December 1, 2025 at 12:59 PM
We just extended the deadline for the #LLVM dev room at #FOSDEM submissions until 7th of December. There's still time to make your submission at pretalx.fosdem.org/fosdem-2026/... !
Full CFP at discourse.llvm.org/t/88746
Full CFP at discourse.llvm.org/t/88746
Reposted by Alex Bradbury
A little benchmark of the Hetzner AX102 dedicated server vs the similarly sized Hetzner CCX53. Also includes my recipe for installing Arch on the VPS from the rescue environment muxup.com/2025q4/minip...

Minipost: Benchmarking the Hetzner AX102 vs CCX53
Dedicated server vs 'dedicated resource' VPS benchmarked compiling LLVM.
muxup.com
November 30, 2025 at 11:22 AM
A little benchmark of the Hetzner AX102 dedicated server vs the similarly sized Hetzner CCX53. Also includes my recipe for installing Arch on the VPS from the rescue environment muxup.com/2025q4/minip...
A little benchmark of the Hetzner AX102 dedicated server vs the similarly sized Hetzner CCX53. Also includes my recipe for installing Arch on the VPS from the rescue environment muxup.com/2025q4/minip...
Minipost: Benchmarking the Hetzner AX102 vs CCX53
Dedicated server vs 'dedicated resource' VPS benchmarked compiling LLVM.
muxup.com
November 30, 2025 at 11:22 AM
A little benchmark of the Hetzner AX102 dedicated server vs the similarly sized Hetzner CCX53. Also includes my recipe for installing Arch on the VPS from the rescue environment muxup.com/2025q4/minip...
The recent thread from @simonwillison.net made me dig out and write up notes on inference vs training GPU hours for DeepSeek V3/R1 based on their published data muxup.com/2025q4/minip... Tldr: something like ~70 days of inference traffic (from DeepSeek) to match the training GPU hours for V3 and R1.

Minipost: LLM inference vs training costs for DeepSeek
Looking at data from DeepSeek for GPU hours serving their API vs final run training.
muxup.com
November 29, 2025 at 7:40 PM
The recent thread from @simonwillison.net made me dig out and write up notes on inference vs training GPU hours for DeepSeek V3/R1 based on their published data muxup.com/2025q4/minip... Tldr: something like ~70 days of inference traffic (from DeepSeek) to match the training GPU hours for V3 and R1.
Reposted by Alex Bradbury

Was looking at some older slides and found a claim that copying text around for a text editor is only practical for <256chars.
It's Friday, let's see whether this is a "current" assessment, considering only the text, and none of the other things an editor does.
It's Friday, let's see whether this is a "current" assessment, considering only the text, and none of the other things an editor does.
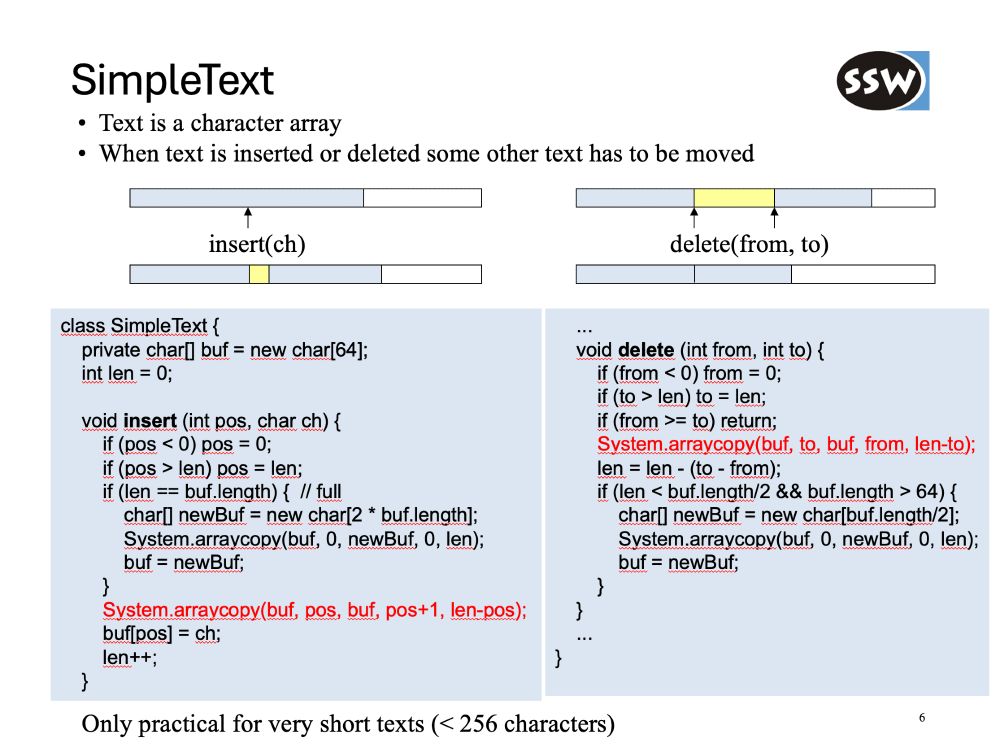
November 28, 2025 at 1:39 PM
Was looking at some older slides and found a claim that copying text around for a text editor is only practical for <256chars.
It's Friday, let's see whether this is a "current" assessment, considering only the text, and none of the other things an editor does.
It's Friday, let's see whether this is a "current" assessment, considering only the text, and none of the other things an editor does.
Yikes, OpenReview had a bug that exposed the anonymous reviewers, authors, and area chairs. openreview.net/forum/user%7...
For those not familiar: it's a tool allowing running a double-blind review process (think HotCRP, EasyChair etc) except review comments and author responses are all public.
For those not familiar: it's a tool allowing running a double-blind review process (think HotCRP, EasyChair etc) except review comments and author responses are all public.
Statement Regarding API Security Incident
openreview.net
November 28, 2025 at 9:33 AM
Yikes, OpenReview had a bug that exposed the anonymous reviewers, authors, and area chairs. openreview.net/forum/user%7...
For those not familiar: it's a tool allowing running a double-blind review process (think HotCRP, EasyChair etc) except review comments and author responses are all public.
For those not familiar: it's a tool allowing running a double-blind review process (think HotCRP, EasyChair etc) except review comments and author responses are all public.