




Jonathan Balloch
@balloch.bsky.social
Robotics PhD Candidate @GeorgiaTech studying #RL and
#AI
I mostly tweet about #AI, #robots, #science, and #3dprinting
My thoughts and opinions are my own.
jballoch.com
#AI
I mostly tweet about #AI, #robots, #science, and #3dprinting
My thoughts and opinions are my own.
jballoch.com
Pinned
Jonathan Balloch
@balloch.bsky.social
· Nov 25




I am a few days late on this, but I'm proud to say: I have passed my dissertation defense for my PhD! 🎉
I'm so thankful for my advisor @markriedl.bsky.social , my committee, my family, my lab, and all those who have supported me through this. Excited for this next chapter!
I'm so thankful for my advisor @markriedl.bsky.social , my committee, my family, my lab, and all those who have supported me through this. Excited for this next chapter!
Le Chat underrated

I absolutely love @MistralAI. Even the free version is super fast and report sources 🤩 The pro version is even better.

March 25, 2025 at 1:41 PM
Le Chat underrated
well thats not great

Too busy with costumes. As the Carolinas burn, Homeland Security head Kristie Noem says Trump administration is going to ‘eliminate’ FEMA www.the-independent.com/news/world/a...

Kristie Noem says Trump administration is going to ‘eliminate’ FEMA
Poor, disaster-prone red states would likely be hit hardest if the federal government withdraws funding
www.the-independent.com
March 25, 2025 at 1:35 PM
well thats not great
Reposted by Jonathan Balloch

I think a deeper difficulty in ML is the economy of attention. The hundreds of papers each day released on ArXiv in ML means that a reader needs to resort to heuristics to keep up. Stuff like trust a recommender system, or only read famous authors, or scan for buzzwords.
March 22, 2025 at 12:21 PM
I think a deeper difficulty in ML is the economy of attention. The hundreds of papers each day released on ArXiv in ML means that a reader needs to resort to heuristics to keep up. Stuff like trust a recommender system, or only read famous authors, or scan for buzzwords.
Sarah Paine is incredible
March 17, 2025 at 1:50 PM
Sarah Paine is incredible
Given whats going on in the world, I think its time to reread Brave New World
March 11, 2025 at 2:45 PM
Given whats going on in the world, I think its time to reread Brave New World
Reposted by Jonathan Balloch

Example, pre-train (reward free) to map temporal distances into distances in latent space, and then, finetune: map these through a dot product with a latent task description to a reward function.
A couple of refs:
openreview.net/forum?id=YGh...
arxiv.org/abs/2110.02719
arxiv.org/abs/2110.15191
A couple of refs:
openreview.net/forum?id=YGh...
arxiv.org/abs/2110.02719
arxiv.org/abs/2110.15191

March 10, 2025 at 6:26 PM
Example, pre-train (reward free) to map temporal distances into distances in latent space, and then, finetune: map these through a dot product with a latent task description to a reward function.
A couple of refs:
openreview.net/forum?id=YGh...
arxiv.org/abs/2110.02719
arxiv.org/abs/2110.15191
A couple of refs:
openreview.net/forum?id=YGh...
arxiv.org/abs/2110.02719
arxiv.org/abs/2110.15191
very exciting!
$14k open source humanoid robot upper torso. Writing with a pen on a notebook that you're holding is an impressively challenging task! Also comes with an open, modular, python software stack for robot control and planning.
openpyro-a1.github.io
openpyro-a1.github.io
March 10, 2025 at 8:59 PM
very exciting!
Reposted by Jonathan Balloch

$14k open source humanoid robot upper torso. Writing with a pen on a notebook that you're holding is an impressively challenging task! Also comes with an open, modular, python software stack for robot control and planning.
openpyro-a1.github.io
openpyro-a1.github.io
March 10, 2025 at 4:21 PM
$14k open source humanoid robot upper torso. Writing with a pen on a notebook that you're holding is an impressively challenging task! Also comes with an open, modular, python software stack for robot control and planning.
openpyro-a1.github.io
openpyro-a1.github.io
Reposted by Jonathan Balloch

Hiring researchers and engineers for a stealth, applied research company with a focus on RL x foundation models. Folks on the team already are leading RL / learning researchers. If you think you'd be good at the research needed to get things working in practice, email me
March 10, 2025 at 4:44 PM
Hiring researchers and engineers for a stealth, applied research company with a focus on RL x foundation models. Folks on the team already are leading RL / learning researchers. If you think you'd be good at the research needed to get things working in practice, email me

Congrats Andrew and Rich, well deserved!! apnews.com/article/turi...

AI pioneers who channeled 'hedonistic' machines win computer science's top prize
Teaching machines in the way that animal trainers mold the behavior of dogs or horses has been an important method for developing artificial intelligence and one that was recognized Wednesday with the...
apnews.com
March 6, 2025 at 3:41 AM
Congrats Andrew and Rich, well deserved!! apnews.com/article/turi...
Reposted by Jonathan Balloch
One reason to be intolerant of misleading hype in tech and science is that tolerating the small lies and deception is how you get tolerance of big lies
February 20, 2025 at 6:17 PM
One reason to be intolerant of misleading hype in tech and science is that tolerating the small lies and deception is how you get tolerance of big lies
Reposted by Jonathan Balloch

Trying to tell the story behind this explosion of research we are in. An unexpected RL Renaissance.
New talk! Forecasting the Alpaca moment for reasoning models and why the new style of RL training is a far bigger deal than the emergence of RLHF.
YouTube: https://buff.ly/41bVRPp
New talk! Forecasting the Alpaca moment for reasoning models and why the new style of RL training is a far bigger deal than the emergence of RLHF.
YouTube: https://buff.ly/41bVRPp

An unexpected RL Renaissance
New talk! Forecasting the Alpaca moment for reasoning models and why the new style of RL training is a far bigger deal than the emergence of RLHF.
www.interconnects.ai
February 13, 2025 at 3:42 PM
Trying to tell the story behind this explosion of research we are in. An unexpected RL Renaissance.
New talk! Forecasting the Alpaca moment for reasoning models and why the new style of RL training is a far bigger deal than the emergence of RLHF.
YouTube: https://buff.ly/41bVRPp
New talk! Forecasting the Alpaca moment for reasoning models and why the new style of RL training is a far bigger deal than the emergence of RLHF.
YouTube: https://buff.ly/41bVRPp
Reposted by Jonathan Balloch
Easier installation, faster PPO script, new tutorials. The team has put in so much work and I'm excited for y'all to try it.
github.com/Emerge-Lab/g...
github.com/Emerge-Lab/g...
February 20, 2025 at 7:04 PM
Easier installation, faster PPO script, new tutorials. The team has put in so much work and I'm excited for y'all to try it.
github.com/Emerge-Lab/g...
github.com/Emerge-Lab/g...
Incredibly cool article. Why, in spite of all of the hype about the scale of learning, we shouldn't forget the second half of Sutton's Bitter Lesson: search scales too, and often better yellow-apartment-148.notion.site/AI-Search-Th...
(h/t klowrey)
(h/t klowrey)

AI Search: The Bitter-er Lesson | Notion
What if we could start automating AI research today? What if we didn’t have to wait for a 2030 supercluster to cure cancer? What if ASI was in the room with us already?
yellow-apartment-148.notion.site
February 20, 2025 at 9:40 PM
Incredibly cool article. Why, in spite of all of the hype about the scale of learning, we shouldn't forget the second half of Sutton's Bitter Lesson: search scales too, and often better yellow-apartment-148.notion.site/AI-Search-Th...
(h/t klowrey)
(h/t klowrey)
Awesome!!!

LLM Reasoning labs will be eating good today🍔
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
We commandeered the HF cluster for a few days and generated 1.2M reasoning-filled solutions to 500k NuminaMath problems with DeepSeek-R1 🐳
Have fun!
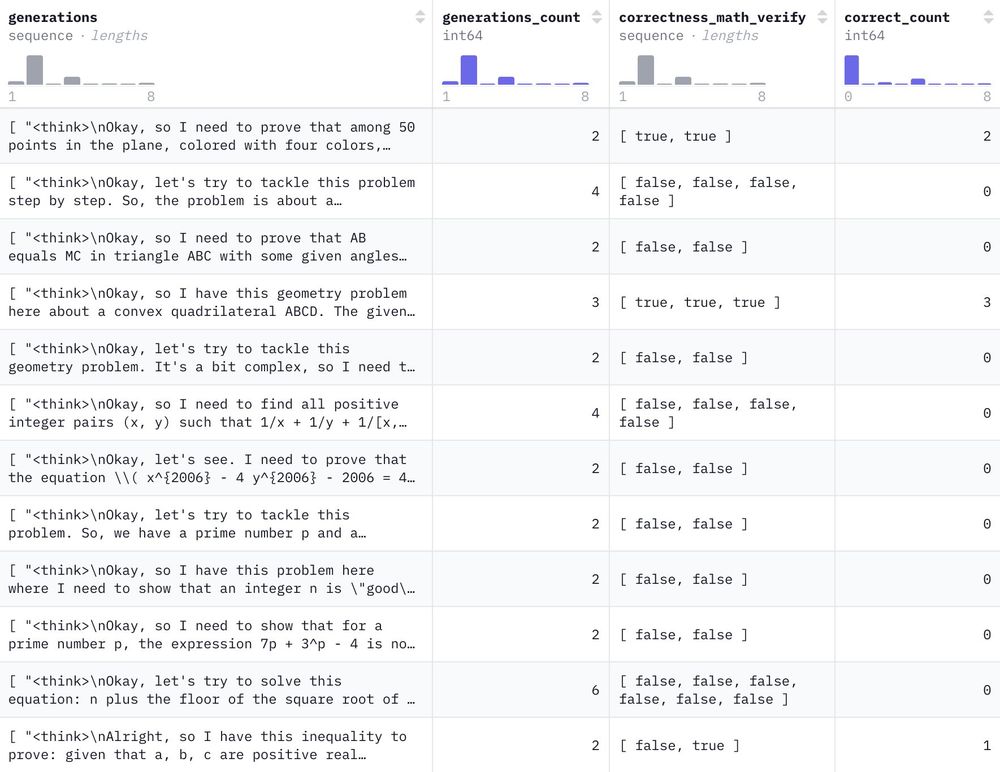
February 12, 2025 at 3:23 PM
Awesome!!!
Reposted by Jonathan Balloch

An appeaser is one who feeds a crocodile—hoping it will eat him last.
—Winston Churchill
—Winston Churchill
February 12, 2025 at 3:10 PM
An appeaser is one who feeds a crocodile—hoping it will eat him last.
—Winston Churchill
—Winston Churchill
I try to avoid political topics but this is important. Trump NIH and FDA nominees debut new science journal "increasing transparency" of peer review, but more importantly giving a platform for science that can't pass traditional peer review www.foxnews.com/politics/tru...
Stay skeptical my friends
Stay skeptical my friends
February 12, 2025 at 3:20 PM
I try to avoid political topics but this is important. Trump NIH and FDA nominees debut new science journal "increasing transparency" of peer review, but more importantly giving a platform for science that can't pass traditional peer review www.foxnews.com/politics/tru...
Stay skeptical my friends
Stay skeptical my friends
Really interesting work from Nvidia, UW, and AI2
Its called SAM2Act—a multi-view robotic transformer-based policy that integrates a visual foundation model with a memory architecture for robotic manipulation.
Project page: sam2act.github.io
Open code: github.com/sam2act/SAM2...
Its called SAM2Act—a multi-view robotic transformer-based policy that integrates a visual foundation model with a memory architecture for robotic manipulation.
Project page: sam2act.github.io
Open code: github.com/sam2act/SAM2...

GitHub - sam2act/SAM2Act: Official Repository for the code of SAM2Act
Official Repository for the code of SAM2Act. Contribute to sam2act/SAM2Act development by creating an account on GitHub.
github.com
February 11, 2025 at 8:16 PM
Really interesting work from Nvidia, UW, and AI2
Its called SAM2Act—a multi-view robotic transformer-based policy that integrates a visual foundation model with a memory architecture for robotic manipulation.
Project page: sam2act.github.io
Open code: github.com/sam2act/SAM2...
Its called SAM2Act—a multi-view robotic transformer-based policy that integrates a visual foundation model with a memory architecture for robotic manipulation.
Project page: sam2act.github.io
Open code: github.com/sam2act/SAM2...
incredible resource

Excited to share that today our paper recommender platform www.scholar-inbox.com has reached 20k users! We hope to reach 100k by the end of the year.. Lots of new features are being worked on currently and rolled out soon.

January 31, 2025 at 8:59 PM
incredible resource
Reposted by Jonathan Balloch

This review paper by @guillaume-garrigos.com on SGD-related algorithms is a fantastic resource, offering elegant, self-contained, and concise proofs in a single, accessible reference. arxiv.org/pdf/2301.11235

January 29, 2025 at 4:15 PM
This review paper by @guillaume-garrigos.com on SGD-related algorithms is a fantastic resource, offering elegant, self-contained, and concise proofs in a single, accessible reference. arxiv.org/pdf/2301.11235
Reposted by Jonathan Balloch

As someone who has reported on AI for 7 years and covered China tech as well, I think the biggest lesson to be drawn from DeepSeek is the huge cracks it illustrates with the current dominant paradigm of AI development. A long thread. 1/
January 27, 2025 at 2:12 PM
As someone who has reported on AI for 7 years and covered China tech as well, I think the biggest lesson to be drawn from DeepSeek is the huge cracks it illustrates with the current dominant paradigm of AI development. A long thread. 1/
Its a bad time

Hard to do any planning whatsoever in a highly uncertain environment, but I am glad for the reversal.
Not out of the woods, freezes and pulled-back grants are still in the works once they get their act together.
apnews.com/article/dona...
Not out of the woods, freezes and pulled-back grants are still in the works once they get their act together.
apnews.com/article/dona...

Trump White House rescinds order freezing federal grants after widespread confusion
President Donald Trump’s budget office rescinded an order freezing spending on federal grants, less than two days after it sparked widespread confusion and legal challenges across the country, accordi...
apnews.com
January 29, 2025 at 10:33 PM
Its a bad time
Reposted by Jonathan Balloch

