



Christoph Minixhofer
@cdminix.bsky.social
Post-doc @ University of Edinburgh. Working on Synthetic Speech Evaluation at the moment.
🇳🇴 Oslo 🏴 Edinburgh 🇦🇹 Graz
🇳🇴 Oslo 🏴 Edinburgh 🇦🇹 Graz
Pinned

Quantifying the Distributional Distance between Synthetic and Real Speech (Pre-Viva Talk)
YouTube video by Christoph Minixhofer
youtu.be
Passed my viva yesterday 🥳
Here's the pre-viva talk if anyone's interested, my work was/is about quantifying the distributional distance between real and synthetic speech.
youtu.be/Ii-6buwAoCg
Here's the pre-viva talk if anyone's interested, my work was/is about quantifying the distributional distance between real and synthetic speech.
youtu.be/Ii-6buwAoCg
Reposted by Christoph Minixhofer

www.technomoralfutures.uk/news-databas...
Happy Monday! Here's me thinking about speech tech, voices, and death thanks to the lovely @technomoralfutures.bsky.social
content notes: discussion of death, grief, online abuse
Happy Monday! Here's me thinking about speech tech, voices, and death thanks to the lovely @technomoralfutures.bsky.social
content notes: discussion of death, grief, online abuse

Text-to-speech voices as human remains — Centre for Technomoral Futures
Speech technology researchers worldwide are working on improving the smoothness and fidelity of text-to-speech towards the goal of accessible communication for all. However, TTS models are also being ...
www.technomoralfutures.uk
November 24, 2025 at 12:24 PM
www.technomoralfutures.uk/news-databas...
Happy Monday! Here's me thinking about speech tech, voices, and death thanks to the lovely @technomoralfutures.bsky.social
content notes: discussion of death, grief, online abuse
Happy Monday! Here's me thinking about speech tech, voices, and death thanks to the lovely @technomoralfutures.bsky.social
content notes: discussion of death, grief, online abuse
Passed my viva yesterday 🥳
Here's the pre-viva talk if anyone's interested, my work was/is about quantifying the distributional distance between real and synthetic speech.
youtu.be/Ii-6buwAoCg
Here's the pre-viva talk if anyone's interested, my work was/is about quantifying the distributional distance between real and synthetic speech.
youtu.be/Ii-6buwAoCg
Quantifying the Distributional Distance between Synthetic and Real Speech (Pre-Viva Talk)
YouTube video by Christoph Minixhofer
youtu.be
November 19, 2025 at 11:18 AM
Passed my viva yesterday 🥳
Here's the pre-viva talk if anyone's interested, my work was/is about quantifying the distributional distance between real and synthetic speech.
youtu.be/Ii-6buwAoCg
Here's the pre-viva talk if anyone's interested, my work was/is about quantifying the distributional distance between real and synthetic speech.
youtu.be/Ii-6buwAoCg
First time going to a big gym in the UK, and somehow the practice of saying a little “sorry” as you go past someone cracks me up in that setting.
November 11, 2025 at 10:23 AM
First time going to a big gym in the UK, and somehow the practice of saying a little “sorry” as you go past someone cracks me up in that setting.
Reposted by Christoph Minixhofer

Fill in the blank:
"My p-value is smaller than 0.05, so..."
Wrong answers only.
"My p-value is smaller than 0.05, so..."
Wrong answers only.

November 4, 2025 at 12:24 PM
Fill in the blank:
"My p-value is smaller than 0.05, so..."
Wrong answers only.
"My p-value is smaller than 0.05, so..."
Wrong answers only.
I don't download new HF models often, but when I do, it's during the 0.008% of downtime :(

October 20, 2025 at 9:04 AM
I don't download new HF models often, but when I do, it's during the 0.008% of downtime :(
TTSDS2 is one of the papers accepted by the @neuripsconf.bsky.social area chairs but but rejected by the senior area chairs with no explanation as to why. A bit frustrating after the long review process.
September 20, 2025 at 8:28 AM
TTSDS2 is one of the papers accepted by the @neuripsconf.bsky.social area chairs but but rejected by the senior area chairs with no explanation as to why. A bit frustrating after the long review process.
Accents are also best seen as a distribution, not a group of labels imo. We tried to incorporate some proxy of accent in TTSDS2, but a simple phone distribution did not work all that well, probably because it’s hard to disentangle from lexical content…

in honour of interspeech this week, i’d like to issue a reminder that everyone has an accent, and that’s beautiful, actually: www.isca-archive.org/interspeech_...
www.isca-archive.org/interspeech_...
www.isca-archive.org/interspeech_...
August 24, 2025 at 4:41 PM
Accents are also best seen as a distribution, not a group of labels imo. We tried to incorporate some proxy of accent in TTSDS2, but a simple phone distribution did not work all that well, probably because it’s hard to disentangle from lexical content…
It's been a great #interspeech2025!
I presented a TTS-for-ASR paper:
www.isca-archive.org/interspeech_...
And one on prosody reps: www.isca-archive.org/interspeech_...
There were many interesting questions & comments - if you have more and didn't get the chance feel free to send me a message.
I presented a TTS-for-ASR paper:
www.isca-archive.org/interspeech_...
And one on prosody reps: www.isca-archive.org/interspeech_...
There were many interesting questions & comments - if you have more and didn't get the chance feel free to send me a message.


August 21, 2025 at 4:47 PM
It's been a great #interspeech2025!
I presented a TTS-for-ASR paper:
www.isca-archive.org/interspeech_...
And one on prosody reps: www.isca-archive.org/interspeech_...
There were many interesting questions & comments - if you have more and didn't get the chance feel free to send me a message.
I presented a TTS-for-ASR paper:
www.isca-archive.org/interspeech_...
And one on prosody reps: www.isca-archive.org/interspeech_...
There were many interesting questions & comments - if you have more and didn't get the chance feel free to send me a message.
I’ll will be presenting this tomorrow at 8.50 at #interspeech2025, come by if you’re interested in prosodic representations!
🧪 SSL (self-supervised learning) models can produce very useful speech representations, but what if we limit their input to prosodic correlates (Pitch, Energy, Voice Activity)? Sarenne Wallbridge and I explored what these representations do (and don’t) encode: arxiv.org/abs/2506.02584 1/2

Prosodic Structure Beyond Lexical Content: A Study of Self-Supervised Learning
People exploit the predictability of lexical structures during text comprehension. Though predictable structure is also present in speech, the degree to which prosody, e.g. intonation, tempo, and loud...
arxiv.org
August 20, 2025 at 8:48 PM
I’ll will be presenting this tomorrow at 8.50 at #interspeech2025, come by if you’re interested in prosodic representations!
In other news — if you’re an early bird and at #interspeech, feel free to drop by my poster presentation on scaling synthetic data tomorrow - who doesn’t want to chat about neural scaling laws early in the morning!
App: interspeech.app.link?event=687602...
Paper: www.isca-archive.org/interspeech_...
App: interspeech.app.link?event=687602...
Paper: www.isca-archive.org/interspeech_...
August 19, 2025 at 9:24 PM
In other news — if you’re an early bird and at #interspeech, feel free to drop by my poster presentation on scaling synthetic data tomorrow - who doesn’t want to chat about neural scaling laws early in the morning!
App: interspeech.app.link?event=687602...
Paper: www.isca-archive.org/interspeech_...
App: interspeech.app.link?event=687602...
Paper: www.isca-archive.org/interspeech_...
A highlight at #interspeech so far: the “hear me out” show&tell in which you can check how the spoken language model Moshi responds based on if it’s your voice or a voice converted version to the opposite gender.
Check it out here shreeharsha-bs.github.io/Hear-Me-Out/
1/2
Check it out here shreeharsha-bs.github.io/Hear-Me-Out/
1/2
Hear Me Out
Interactive evaluation and bias discovery platform for speech-to-speech conversational AI
shreeharsha-bs.github.io
August 19, 2025 at 9:14 PM
A highlight at #interspeech so far: the “hear me out” show&tell in which you can check how the spoken language model Moshi responds based on if it’s your voice or a voice converted version to the opposite gender.
Check it out here shreeharsha-bs.github.io/Hear-Me-Out/
1/2
Check it out here shreeharsha-bs.github.io/Hear-Me-Out/
1/2
If you’re interested in ASR for low resource languages, come by at 14.30 in Poster Area 09 at #interspeech today! I’ll be presenting this paper by Ondrej Klejch et al. arxiv.org/abs/2506.04915
A Practitioner's Guide to Building ASR Models for Low-Resource Languages: A Case Study on Scottish Gaelic
An effective approach to the development of ASR systems for low-resource languages is to fine-tune an existing multilingual end-to-end model. When the original model has been trained on large quantiti...
arxiv.org
August 18, 2025 at 9:59 AM
If you’re interested in ASR for low resource languages, come by at 14.30 in Poster Area 09 at #interspeech today! I’ll be presenting this paper by Ondrej Klejch et al. arxiv.org/abs/2506.04915
Looking forward to present a bunch of things at #INTERSPEECH and #SSW - will put the details here once my thesis final draft is done, which will probably be on the plane to Rotterdam.
August 11, 2025 at 9:34 PM
Looking forward to present a bunch of things at #INTERSPEECH and #SSW - will put the details here once my thesis final draft is done, which will probably be on the plane to Rotterdam.
One day until the Q2 ttsdsbenchmark.com update. We‘ll see which TTS system tops the leaderboard this time - some new ones have been added that could shake things up.

July 4, 2025 at 6:29 AM
One day until the Q2 ttsdsbenchmark.com update. We‘ll see which TTS system tops the leaderboard this time - some new ones have been added that could shake things up.
Followed your advice and can confirm “Ughaaaghaghaa” was my reaction as well.

You ever watch a film and just know it’s a seminal medium-defining work of peak interdisciplinary storytelling all you can say in the moment is “Ughaaaghaghaa” and then cry?
So yeah everyone watch K-Pop Demon Hunters.
So yeah everyone watch K-Pop Demon Hunters.
July 2, 2025 at 11:29 AM
Followed your advice and can confirm “Ughaaaghaghaa” was my reaction as well.
This figure motivated a lot of my PhD (or at least nudged me into a direction) -- check out arxiv.org/abs/2110.11479 (Hu et al.) if you haven't come across it before, it really frames the problem of synthetic/real speech distributions well.

June 30, 2025 at 6:40 PM
This figure motivated a lot of my PhD (or at least nudged me into a direction) -- check out arxiv.org/abs/2110.11479 (Hu et al.) if you haven't come across it before, it really frames the problem of synthetic/real speech distributions well.
Spotted a Norwegian flag across the Firth of Forth, didn’t know Norwegians had hytte on this side of the North Sea as well!

June 29, 2025 at 12:42 PM
Spotted a Norwegian flag across the Firth of Forth, didn’t know Norwegians had hytte on this side of the North Sea as well!
More details on this soon! Also this weekend is the last chance to submit your TTS system for the next round of evaluation (Q2 2025) by either messaging me at [email protected] or requesting a model here: huggingface.co/spaces/ttsds...

Christoph Minixhofer, Ondrej Klejch, Peter Bell: TTSDS2: Resources and Benchmark for Evaluating Human-Quality Text to Speech Systems https://arxiv.org/abs/2506.19441 https://arxiv.org/pdf/2506.19441 https://arxiv.org/html/2506.19441
June 27, 2025 at 8:09 AM
More details on this soon! Also this weekend is the last chance to submit your TTS system for the next round of evaluation (Q2 2025) by either messaging me at [email protected] or requesting a model here: huggingface.co/spaces/ttsds...
It’s amazing how a days work can stretch out over a fortnight, and a week of work can be compressed into 24 hours sometimes…
June 27, 2025 at 2:53 AM
It’s amazing how a days work can stretch out over a fortnight, and a week of work can be compressed into 24 hours sometimes…
I wonder if there are naturally left-curling and right-curling cats, or if all cats curl both ways.

Not Japan-related, but since we all need a distraction from The Horrors, Takaya Suzuki points out a study that examined 408 sleeping cats and found the majority (65%) curl leftwards.
I'm not sure how useful this information is, but...it's yours now.
I'm not sure how useful this information is, but...it's yours now.
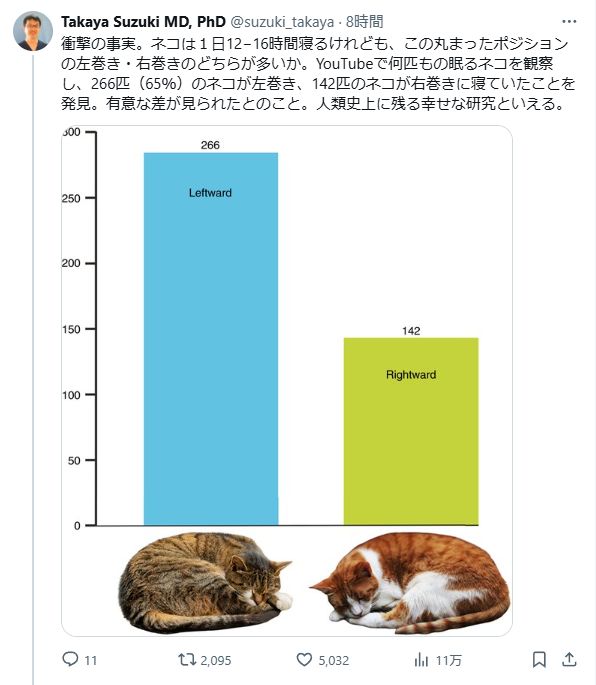
June 25, 2025 at 11:57 PM
I wonder if there are naturally left-curling and right-curling cats, or if all cats curl both ways.
I’ve only really encountered people trying to avoid sounding like AI… but it makes sense that it would alter how people speak if they interact with it a lot. Makes me sad though since it pushes people towards the mean, which is always the most boring.

It’s funny that “nuance” is one of the words LLMs tend to avoid www.theverge.com/openai/68674...

You sound like ChatGPT
AI isn’t just impacting how we write — it’s changing how we speak and interact with others. And there’s only more to come.
www.theverge.com
June 23, 2025 at 9:22 PM
I’ve only really encountered people trying to avoid sounding like AI… but it makes sense that it would alter how people speak if they interact with it a lot. Makes me sad though since it pushes people towards the mean, which is always the most boring.
Pro tip #1: don’t use a poster tube when travelling to and a from conferences, people might come up to you and ask about your research. Pro tip #2: get a poster tube if you don’t want to talk about your research anymore once you’re done with the conference.
June 18, 2025 at 11:36 AM
Pro tip #1: don’t use a poster tube when travelling to and a from conferences, people might come up to you and ask about your research. Pro tip #2: get a poster tube if you don’t want to talk about your research anymore once you’re done with the conference.
Taylor 2009:
„Sometimes the question is raised as to whether we really want a TTS system to sound like a human at all.“
me: I wonder where this is going
later:
„no matter how good a system is, it will rarely be mistaken for a real person, and we believe this concern can be ignored.“
me: oh no
„Sometimes the question is raised as to whether we really want a TTS system to sound like a human at all.“
me: I wonder where this is going
later:
„no matter how good a system is, it will rarely be mistaken for a real person, and we believe this concern can be ignored.“
me: oh no
June 17, 2025 at 3:16 AM
Taylor 2009:
„Sometimes the question is raised as to whether we really want a TTS system to sound like a human at all.“
me: I wonder where this is going
later:
„no matter how good a system is, it will rarely be mistaken for a real person, and we believe this concern can be ignored.“
me: oh no
„Sometimes the question is raised as to whether we really want a TTS system to sound like a human at all.“
me: I wonder where this is going
later:
„no matter how good a system is, it will rarely be mistaken for a real person, and we believe this concern can be ignored.“
me: oh no
Didn’t think I’d see myself on Bluesky today! Has been a fun conference so far, anyone interested in what I have in the works make sure to come by my poster tomorrow ;)

2-Day UK and Ireland annual speech workshop (UKIS) well underway at York University sites.google.com/york.ac.uk/u...

June 16, 2025 at 10:29 PM
Didn’t think I’d see myself on Bluesky today! Has been a fun conference so far, anyone interested in what I have in the works make sure to come by my poster tomorrow ;)
Can’t wait for the whale IPA chart.

Whale vocalizations not only resemble human vowels, but also behave like ones!
We previously discovered that sperm whales have analogues to human vowels.
In a new preprint, we analyze linguistic behavior of whale vowels.
We previously discovered that sperm whales have analogues to human vowels.
In a new preprint, we analyze linguistic behavior of whale vowels.
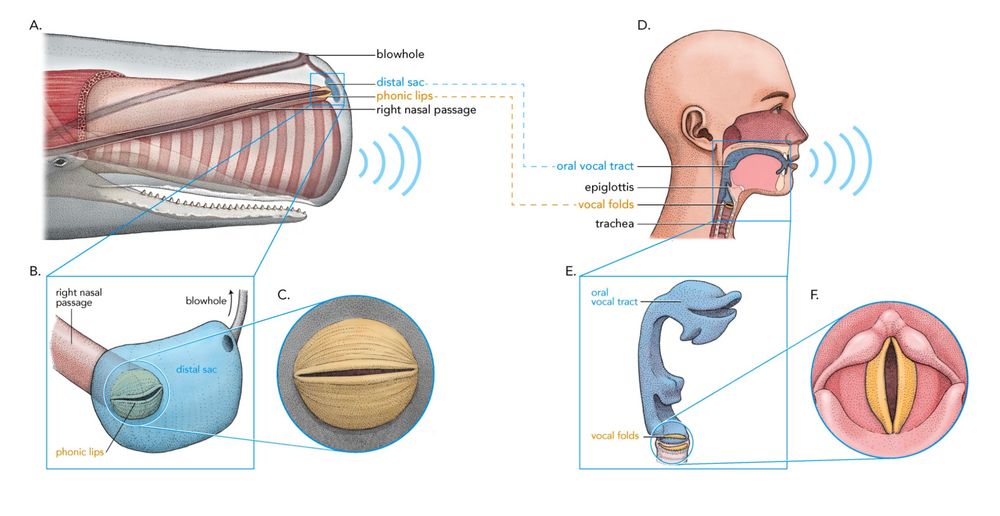
June 12, 2025 at 5:49 AM
Can’t wait for the whale IPA chart.