



Dayeon (Zoey) Ki
@dayeonki.bsky.social
Reposted by Dayeon (Zoey) Ki

December 2, 2024 at 8:39 AM
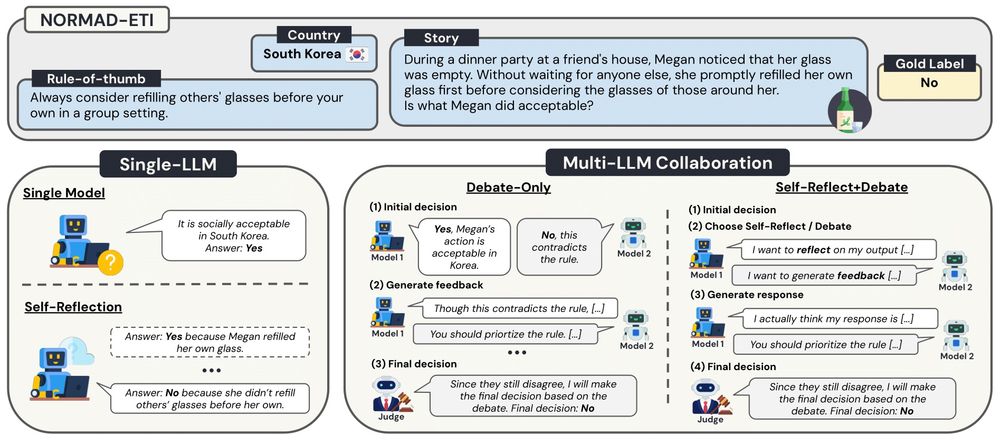
1/ How can a monolingual English speaker 🇺🇸 decide if an automatic French translation 🇫🇷 is good enough to be shared?
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
May 21, 2025 at 5:49 PM
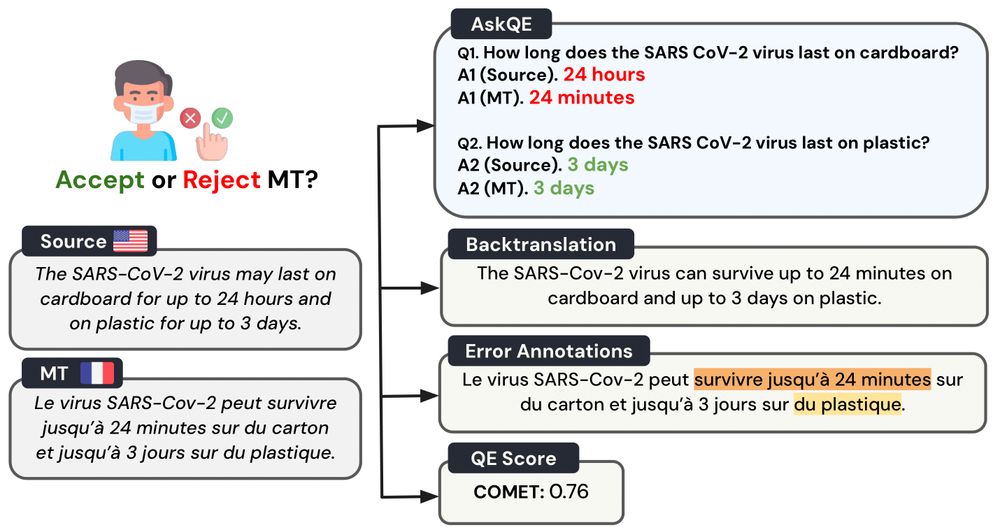
1/ How can a monolingual English speaker 🇺🇸 decide if an automatic French translation 🇫🇷 is good enough to be shared?
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
Introducing ❓AskQE❓, an #LLM-based Question Generation + Answering framework that detects critical MT errors and provides actionable feedback 🗣️
#ACL2025
Reposted by Dayeon (Zoey) Ki

How does the public conceptualize AI? Rather than self-reported measures, we use metaphors to understand the nuance and complexity of people’s mental models. In our #FAccT2025 paper, we analyzed 12,000 metaphors collected over 12 months to track shifts in public perceptions.

May 2, 2025 at 1:19 AM
How does the public conceptualize AI? Rather than self-reported measures, we use metaphors to understand the nuance and complexity of people’s mental models. In our #FAccT2025 paper, we analyzed 12,000 metaphors collected over 12 months to track shifts in public perceptions.
Reposted by Dayeon (Zoey) Ki
Multilinguality is happening at #NAACL2025
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social

April 30, 2025 at 11:18 PM
Multilinguality is happening at #NAACL2025
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
Reposted by Dayeon (Zoey) Ki

Starting my journey on Bluesky with a topic that I care deeply about: AI tools can support creators in various ways, but disclosing AI use may risk devaluing creative work.
Check out our abstract here: angelhwang.github.io/doc/ic2s2_AI...
Inspired by our past work: arxiv.org/abs/2411.13032
Check out our abstract here: angelhwang.github.io/doc/ic2s2_AI...
Inspired by our past work: arxiv.org/abs/2411.13032

"It was 80% me, 20% AI": Seeking Authenticity in Co-Writing with Large Language Models
Given the rising proliferation and diversity of AI writing assistance tools, especially those powered by large language models (LLMs), both writers and readers may have concerns about the impact of th...
arxiv.org
April 18, 2025 at 9:38 PM
Starting my journey on Bluesky with a topic that I care deeply about: AI tools can support creators in various ways, but disclosing AI use may risk devaluing creative work.
Check out our abstract here: angelhwang.github.io/doc/ic2s2_AI...
Inspired by our past work: arxiv.org/abs/2411.13032
Check out our abstract here: angelhwang.github.io/doc/ic2s2_AI...
Inspired by our past work: arxiv.org/abs/2411.13032
🚨 New Paper 🚨
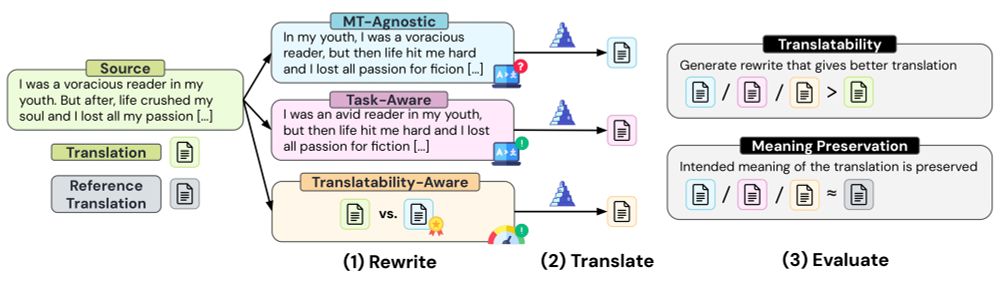
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
April 17, 2025 at 1:32 AM
🚨 New Paper 🚨
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
Reposted by Dayeon (Zoey) Ki

🚨 NEW WORKSHOP ALERT 🚨
We're thrilled to announce the first-ever Tokenization Workshop (TokShop) at #ICML2025 @icmlconf.bsky.social! 🎉
Submissions are open for work on tokenization across all areas of machine learning.
📅 Submission deadline: May 30, 2025
🔗 tokenization-workshop.github.io
We're thrilled to announce the first-ever Tokenization Workshop (TokShop) at #ICML2025 @icmlconf.bsky.social! 🎉
Submissions are open for work on tokenization across all areas of machine learning.
📅 Submission deadline: May 30, 2025
🔗 tokenization-workshop.github.io
Tokenization Workshop @ ICML 2025
tokenization-workshop.github.io
April 15, 2025 at 5:23 PM
🚨 NEW WORKSHOP ALERT 🚨
We're thrilled to announce the first-ever Tokenization Workshop (TokShop) at #ICML2025 @icmlconf.bsky.social! 🎉
Submissions are open for work on tokenization across all areas of machine learning.
📅 Submission deadline: May 30, 2025
🔗 tokenization-workshop.github.io
We're thrilled to announce the first-ever Tokenization Workshop (TokShop) at #ICML2025 @icmlconf.bsky.social! 🎉
Submissions are open for work on tokenization across all areas of machine learning.
📅 Submission deadline: May 30, 2025
🔗 tokenization-workshop.github.io
Reposted by Dayeon (Zoey) Ki

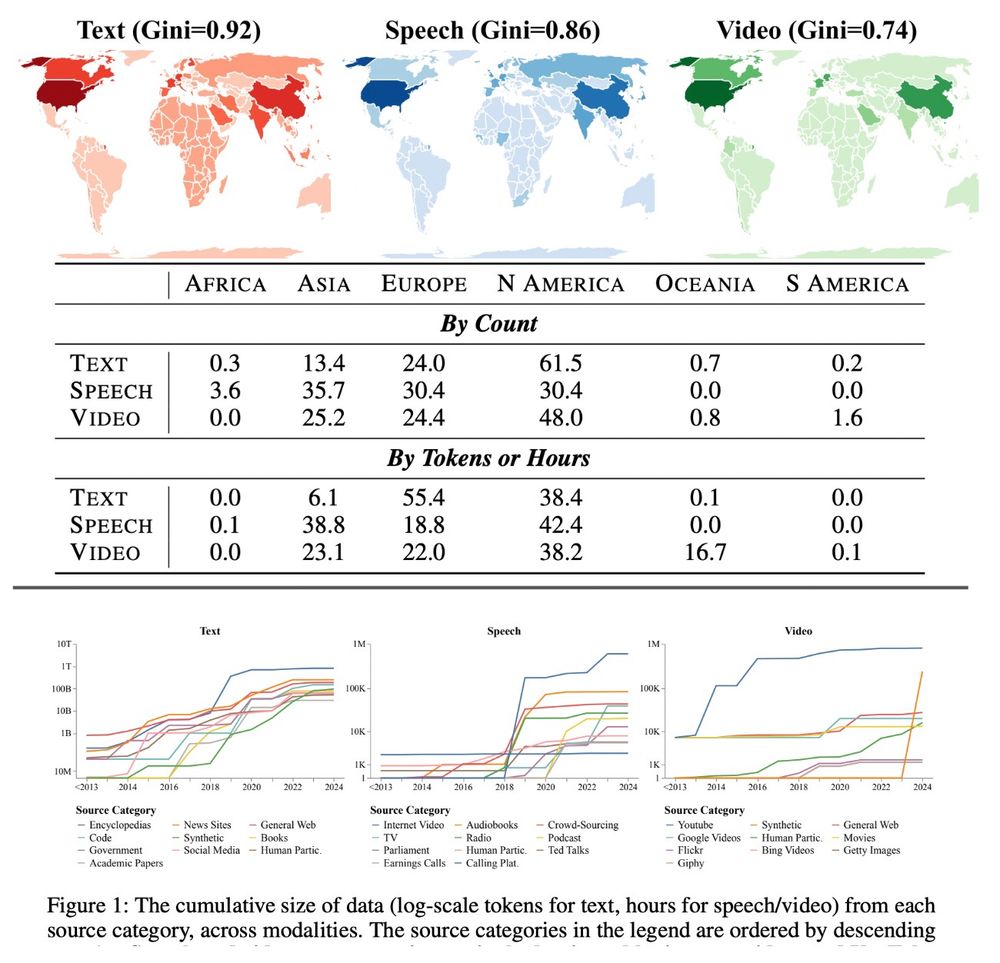
Thrilled our global data ecosystem audit was accepted to #ICLR2025!
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
April 14, 2025 at 3:28 PM
Thrilled our global data ecosystem audit was accepted to #ICLR2025!
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
Empirically, it shows:
1️⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2️⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3️⃣ <0.2% of data from Africa/South America.
1/
Reposted by Dayeon (Zoey) Ki

How do LLMs compare to human crowdworkers in annotating text spans? 🧑🤖
And how can span annotation help us with evaluating texts?
Find out in our new paper: llm-span-annotators.github.io
Arxiv: arxiv.org/abs/2504.08697
And how can span annotation help us with evaluating texts?
Find out in our new paper: llm-span-annotators.github.io
Arxiv: arxiv.org/abs/2504.08697

Large Language Models as Span Annotators
Website for the paper Large Language Models as Span Annotators
llm-span-annotators.github.io
April 15, 2025 at 11:10 AM
How do LLMs compare to human crowdworkers in annotating text spans? 🧑🤖
And how can span annotation help us with evaluating texts?
Find out in our new paper: llm-span-annotators.github.io
Arxiv: arxiv.org/abs/2504.08697
And how can span annotation help us with evaluating texts?
Find out in our new paper: llm-span-annotators.github.io
Arxiv: arxiv.org/abs/2504.08697
Reposted by Dayeon (Zoey) Ki

Call for participation: We just opened the registration for this year's MT Marathon in August in Helsinki, Finland: blogs.helsinki.fi/language-tec..., featuring:
- Ayodele Awokoya
- Wilker Aziz
- Marta Costa-Jussa
- Barry Haddow
- Amit Moryosse
- Sara Papi
- Jörg Tiedemann
- Marco Turchi
- Ayodele Awokoya
- Wilker Aziz
- Marta Costa-Jussa
- Barry Haddow
- Amit Moryosse
- Sara Papi
- Jörg Tiedemann
- Marco Turchi
blogs.helsinki.fi
March 18, 2025 at 12:57 PM
Call for participation: We just opened the registration for this year's MT Marathon in August in Helsinki, Finland: blogs.helsinki.fi/language-tec..., featuring:
- Ayodele Awokoya
- Wilker Aziz
- Marta Costa-Jussa
- Barry Haddow
- Amit Moryosse
- Sara Papi
- Jörg Tiedemann
- Marco Turchi
- Ayodele Awokoya
- Wilker Aziz
- Marta Costa-Jussa
- Barry Haddow
- Amit Moryosse
- Sara Papi
- Jörg Tiedemann
- Marco Turchi
Reposted by Dayeon (Zoey) Ki

Come to Helsinki for the 18th MT Marathon! Sponsored by EAMT @ufal-cuni.bsky.social

March 18, 2025 at 1:10 PM
Come to Helsinki for the 18th MT Marathon! Sponsored by EAMT @ufal-cuni.bsky.social
Reposted by Dayeon (Zoey) Ki

** New parallel data set ** . We've just released HPLT v2.0, a parallel data set of 50 languages paired with English, 380M sentence pairs in total. Extracted from the Internet Archive and Common Crawl hplt-project.org/datasets/v2.0
HPLT - High Performance Language Technologies
A space that combines petabytes of natural language data with large-scale model training
hplt-project.org
February 28, 2025 at 1:34 PM
** New parallel data set ** . We've just released HPLT v2.0, a parallel data set of 50 languages paired with English, 380M sentence pairs in total. Extracted from the Internet Archive and Common Crawl hplt-project.org/datasets/v2.0
Reposted by Dayeon (Zoey) Ki

Brilliant and necessary work by Pombal et al. about metric interference in MT system development and evaluation: arxiv.org/abs/2503.08327
Are we developing better systems or are we just gaming the metrics? And how do we address this?
Super (m)interesting! 👀
Are we developing better systems or are we just gaming the metrics? And how do we address this?
Super (m)interesting! 👀

Adding Chocolate to Mint: Mitigating Metric Interference in Machine Translation
As automatic metrics become increasingly stronger and widely adopted, the risk of unintentionally "gaming the metric" during model development rises. This issue is caused by metric interference (Mint)...
arxiv.org
March 19, 2025 at 3:25 PM
Brilliant and necessary work by Pombal et al. about metric interference in MT system development and evaluation: arxiv.org/abs/2503.08327
Are we developing better systems or are we just gaming the metrics? And how do we address this?
Super (m)interesting! 👀
Are we developing better systems or are we just gaming the metrics? And how do we address this?
Super (m)interesting! 👀
Reposted by Dayeon (Zoey) Ki

Introducing 🐻 BEARCUBS 🐻, a “small but mighty” dataset of 111 QA pairs designed to assess computer-using web agents in multimodal interactions on the live web!
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%

March 12, 2025 at 2:00 PM
Introducing 🐻 BEARCUBS 🐻, a “small but mighty” dataset of 111 QA pairs designed to assess computer-using web agents in multimodal interactions on the live web!
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%
Reposted by Dayeon (Zoey) Ki

New preprint w/ @jennhu.bsky.social @kmahowald.bsky.social : Can LLMs introspect about their knowledge of language?
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
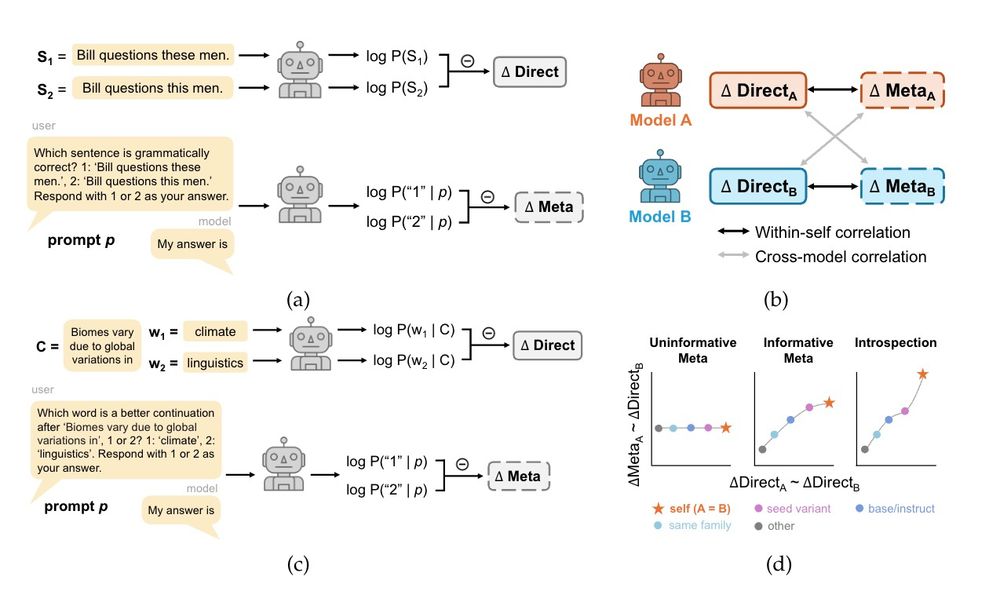
March 12, 2025 at 2:31 PM
New preprint w/ @jennhu.bsky.social @kmahowald.bsky.social : Can LLMs introspect about their knowledge of language?
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
Across models and domains, we did not find evidence that LLMs have privileged access to their own predictions. 🧵(1/8)
Reposted by Dayeon (Zoey) Ki

OK, every year I try to explain to my students how LLMs work, and every year I have to do a big trawl for good resources and activities. Here's this year's haul of *introductory* materials. (In-class activities + visualizations, not so much readings.)
March 6, 2025 at 6:42 PM
OK, every year I try to explain to my students how LLMs work, and every year I have to do a big trawl for good resources and activities. Here's this year's haul of *introductory* materials. (In-class activities + visualizations, not so much readings.)
Reposted by Dayeon (Zoey) Ki

Big news from WMT! 🎉 We are expanding beyond MT and launching a new multilingual instruction shared task. Our goal is to foster truly multilingual LLM evaluation and best practices in automatic and human evaluation. Join us and build the winning multilingual system!
www2.statmt.org/wmt25/multil...
www2.statmt.org/wmt25/multil...
Multilingual Instruction Shared Task
www2.statmt.org
March 11, 2025 at 6:26 PM
Big news from WMT! 🎉 We are expanding beyond MT and launching a new multilingual instruction shared task. Our goal is to foster truly multilingual LLM evaluation and best practices in automatic and human evaluation. Join us and build the winning multilingual system!
www2.statmt.org/wmt25/multil...
www2.statmt.org/wmt25/multil...
Reposted by Dayeon (Zoey) Ki

self-insert, but if you are looking for something multilingual and public domain, we have PoeTree: a collection of poetry corpora with Python & R access points (can get data directly into your jupyter notebook) : versologie.cz/poetree/

PoeTree. Poetry Treebanks in 10 languages
PoeTree is a standardized collection of poetry corpora comprising over 330,000 poems in ten languages (Czech, English, French, German, Hungarian, Italian, Portuguese, Russian, Slovenian, Spanish).
versologie.cz
March 11, 2025 at 3:48 PM
self-insert, but if you are looking for something multilingual and public domain, we have PoeTree: a collection of poetry corpora with Python & R access points (can get data directly into your jupyter notebook) : versologie.cz/poetree/
Reposted by Dayeon (Zoey) Ki

Lots of work coming soon to @iclr-conf.bsky.social and @naaclmeeting.bsky.social in April/May! Come chat with us about new methods for interpreting and editing LLMs, multilingual concept representations, sentence processing mechanisms, and arithmetic reasoning. 🧵
March 11, 2025 at 2:30 PM
Lots of work coming soon to @iclr-conf.bsky.social and @naaclmeeting.bsky.social in April/May! Come chat with us about new methods for interpreting and editing LLMs, multilingual concept representations, sentence processing mechanisms, and arithmetic reasoning. 🧵
Reposted by Dayeon (Zoey) Ki

🚨 Our team at UMD is looking for participants to study how #LLM agent plans can help you answer complex questions
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
March 11, 2025 at 2:30 PM
🚨 Our team at UMD is looking for participants to study how #LLM agent plans can help you answer complex questions
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
Reposted by Dayeon (Zoey) Ki

Happy to say that our paper "Beyond Literal Token Overlap: Token Alignability for Multilinguality" will be presented at #NAACL2025!
This is work with @tomlim.bsky.social, @jlibovicky.bsky.social, and Alex Fraser.
arxiv.org/abs/2502.06468
#newpaper #NLP #NLProc
This is work with @tomlim.bsky.social, @jlibovicky.bsky.social, and Alex Fraser.
arxiv.org/abs/2502.06468
#newpaper #NLP #NLProc

Beyond Literal Token Overlap: Token Alignability for Multilinguality
Previous work has considered token overlap, or even similarity of token distributions, as predictors for multilinguality and cross-lingual knowledge transfer in language models. However, these very li...
arxiv.org
March 3, 2025 at 5:04 PM
Happy to say that our paper "Beyond Literal Token Overlap: Token Alignability for Multilinguality" will be presented at #NAACL2025!
This is work with @tomlim.bsky.social, @jlibovicky.bsky.social, and Alex Fraser.
arxiv.org/abs/2502.06468
#newpaper #NLP #NLProc
This is work with @tomlim.bsky.social, @jlibovicky.bsky.social, and Alex Fraser.
arxiv.org/abs/2502.06468
#newpaper #NLP #NLProc
Reposted by Dayeon (Zoey) Ki

✨New pre-print✨ Crosslingual transfer allows models to leverage their representations for one language to improve performance on another language. We characterize the acquisition of shared representations in order to better understand how and when crosslingual transfer happens.

March 7, 2025 at 4:34 PM
✨New pre-print✨ Crosslingual transfer allows models to leverage their representations for one language to improve performance on another language. We characterize the acquisition of shared representations in order to better understand how and when crosslingual transfer happens.
Reposted by Dayeon (Zoey) Ki

This is a really neat use case for AI—checking whether claims are actually supported by the given citations.

Misinterpreting Cited Work
"The decline in citation fidelity among senior researchers...[may indicate they] rely more on their established reputations or heuristics, potentially leading to less detailed engagement with individual citations."
Preprint: doi.org/10.48550/arX...
#AcademicSky 🧪
"The decline in citation fidelity among senior researchers...[may indicate they] rely more on their established reputations or heuristics, potentially leading to less detailed engagement with individual citations."
Preprint: doi.org/10.48550/arX...
#AcademicSky 🧪

March 7, 2025 at 8:56 AM
This is a really neat use case for AI—checking whether claims are actually supported by the given citations.
Reposted by Dayeon (Zoey) Ki

📢New Paper Alert!🚀
Human alignment balances social expectations, economic incentives, and legal frameworks. What if LLM alignment worked the same way?🤔
Our latest work explores how social, economic, and contractual alignment can address incomplete contracts in LLM alignment🧵
Human alignment balances social expectations, economic incentives, and legal frameworks. What if LLM alignment worked the same way?🤔
Our latest work explores how social, economic, and contractual alignment can address incomplete contracts in LLM alignment🧵

March 4, 2025 at 4:08 PM
📢New Paper Alert!🚀
Human alignment balances social expectations, economic incentives, and legal frameworks. What if LLM alignment worked the same way?🤔
Our latest work explores how social, economic, and contractual alignment can address incomplete contracts in LLM alignment🧵
Human alignment balances social expectations, economic incentives, and legal frameworks. What if LLM alignment worked the same way?🤔
Our latest work explores how social, economic, and contractual alignment can address incomplete contracts in LLM alignment🧵