




Vilém Zouhar @ EACL
@zouharvi.bsky.social
PhD @ ETH Zürich | working on (multilingual) evaluation of NLP | on the academic job market | go #vegan | https://vilda.net
How often is human evaluation skipped in papers/workflows just because it's too difficult to set up? Yet even small humeval can give so much more signal than automatic metrics.
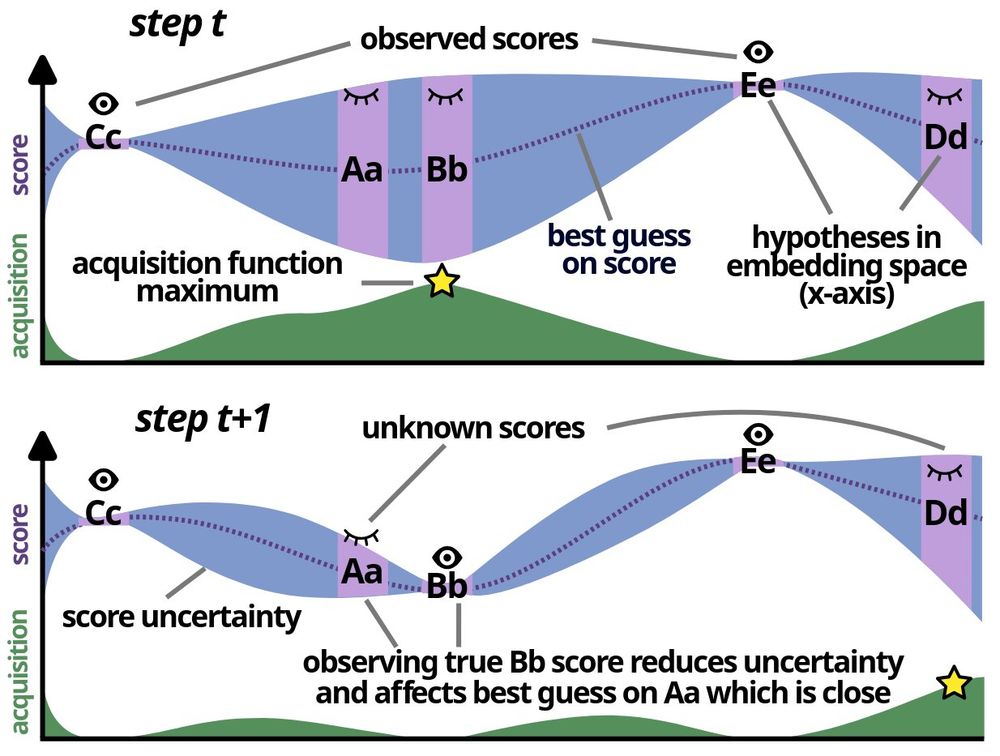
Introducing Pearmut, Human Evaluation of Translation Made Trivial🍐 arxiv.org/pdf/2601.02933
Introducing Pearmut, Human Evaluation of Translation Made Trivial🍐 arxiv.org/pdf/2601.02933

January 28, 2026 at 1:39 PM
How often is human evaluation skipped in papers/workflows just because it's too difficult to set up? Yet even small humeval can give so much more signal than automatic metrics.
Introducing Pearmut, Human Evaluation of Translation Made Trivial🍐 arxiv.org/pdf/2601.02933
Introducing Pearmut, Human Evaluation of Translation Made Trivial🍐 arxiv.org/pdf/2601.02933
Have you ever wondered how speech translation gets evaluated? Sadly, most speech evaluation downgrades to text-based metrics. Let’s do better!
At IWSLT 2026, we’re launching the first-ever ✨Speech Translation Metrics Shared Task ✨!
At IWSLT 2026, we’re launching the first-ever ✨Speech Translation Metrics Shared Task ✨!

January 14, 2026 at 6:04 PM
Have you ever wondered how speech translation gets evaluated? Sadly, most speech evaluation downgrades to text-based metrics. Let’s do better!
At IWSLT 2026, we’re launching the first-ever ✨Speech Translation Metrics Shared Task ✨!
At IWSLT 2026, we’re launching the first-ever ✨Speech Translation Metrics Shared Task ✨!
Dissatisfied with EACL paper decisions? Fret not and submit your paper with ARR reviews to Multilingual Multicultural Evaluation workshop at EACL (both archival or nonarchival) until January 5th. 🔍🙂
multilingual-multicultural-evaluation.github.io
multilingual-multicultural-evaluation.github.io

January 3, 2026 at 12:53 PM
Dissatisfied with EACL paper decisions? Fret not and submit your paper with ARR reviews to Multilingual Multicultural Evaluation workshop at EACL (both archival or nonarchival) until January 5th. 🔍🙂
multilingual-multicultural-evaluation.github.io
multilingual-multicultural-evaluation.github.io
Reposted by Vilém Zouhar @ EACL

Now onwards to making language models transparent and trustworthy for everyone! 🚀
For those curious to know more about my thesis:
- Web-optimized version: gsarti.com/phd-thesis/
- PDF: research.rug.nl/en/publicati...
- Steal my Quarto template: github.com/gsarti/phd-t...
For those curious to know more about my thesis:
- Web-optimized version: gsarti.com/phd-thesis/
- PDF: research.rug.nl/en/publicati...
- Steal my Quarto template: github.com/gsarti/phd-t...
From Insights to Impact
Ph.D. Thesis, Center for Language and Cognition (CLCG), University of Groningen
gsarti.com
December 16, 2025 at 12:21 PM
Now onwards to making language models transparent and trustworthy for everyone! 🚀
For those curious to know more about my thesis:
- Web-optimized version: gsarti.com/phd-thesis/
- PDF: research.rug.nl/en/publicati...
- Steal my Quarto template: github.com/gsarti/phd-t...
For those curious to know more about my thesis:
- Web-optimized version: gsarti.com/phd-thesis/
- PDF: research.rug.nl/en/publicati...
- Steal my Quarto template: github.com/gsarti/phd-t...
Do you have work on resources, metrics & methodologies for evaluating multilingual systems?
Share it at the MME workshop 🕵️ co-located at EACL.
Direct submission deadline in 10 days (December 19th)!
multilingual-multicultural-evaluation.github.io
Share it at the MME workshop 🕵️ co-located at EACL.
Direct submission deadline in 10 days (December 19th)!
multilingual-multicultural-evaluation.github.io
Multilingual Multicultural Evaluation Workshop
LLMs in every language? Prove it. Showcase your work on rigorous, efficient, scalable, culture-aware multilingual benchmarking.
multilingual-multicultural-evaluation.github.io
December 10, 2025 at 9:42 AM
Do you have work on resources, metrics & methodologies for evaluating multilingual systems?
Share it at the MME workshop 🕵️ co-located at EACL.
Direct submission deadline in 10 days (December 19th)!
multilingual-multicultural-evaluation.github.io
Share it at the MME workshop 🕵️ co-located at EACL.
Direct submission deadline in 10 days (December 19th)!
multilingual-multicultural-evaluation.github.io
Let's talk about eval (automatic or human) and multilinguality at #EMNLP in Suzhou! 🇨🇳
- Efficient evaluation (Nov 5, 16:30, poster session 3)
- MT difficulty (Nov 7, 12:30, findings 3)
- COMET-poly (Nov 8, 11:00, WMT)
(DM to meet 🌿 )
- Efficient evaluation (Nov 5, 16:30, poster session 3)
- MT difficulty (Nov 7, 12:30, findings 3)
- COMET-poly (Nov 8, 11:00, WMT)
(DM to meet 🌿 )



October 28, 2025 at 9:45 AM
Let's talk about eval (automatic or human) and multilinguality at #EMNLP in Suzhou! 🇨🇳
- Efficient evaluation (Nov 5, 16:30, poster session 3)
- MT difficulty (Nov 7, 12:30, findings 3)
- COMET-poly (Nov 8, 11:00, WMT)
(DM to meet 🌿 )
- Efficient evaluation (Nov 5, 16:30, poster session 3)
- MT difficulty (Nov 7, 12:30, findings 3)
- COMET-poly (Nov 8, 11:00, WMT)
(DM to meet 🌿 )
Grateful to receive the Google PhD Fellowship in NLP! 🙂
I am not secretive about having applied to 4 similar fellowships during my PhD before and not succeeding. Still, refining my research statement (part of the application) helped me tremendously in finding out the...
inf.ethz.ch/news-and-eve...
I am not secretive about having applied to 4 similar fellowships during my PhD before and not succeeding. Still, refining my research statement (part of the application) helped me tremendously in finding out the...
inf.ethz.ch/news-and-eve...

Google PhD Fellowships 2025
Yutong Chen, Benedict Schlüter and Vilém Zouhar, all three of them doctoral students at the Department of Computer Science, have been awarded the Google PhD Fellowship. The programme was created to re...
inf.ethz.ch
October 24, 2025 at 12:32 PM
Grateful to receive the Google PhD Fellowship in NLP! 🙂
I am not secretive about having applied to 4 similar fellowships during my PhD before and not succeeding. Still, refining my research statement (part of the application) helped me tremendously in finding out the...
inf.ethz.ch/news-and-eve...
I am not secretive about having applied to 4 similar fellowships during my PhD before and not succeeding. Still, refining my research statement (part of the application) helped me tremendously in finding out the...
inf.ethz.ch/news-and-eve...
📢 Announcing the First Workshop on Multilingual and Multicultural Evaluation (MME) at #EACL2026 🇲🇦
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025

October 20, 2025 at 10:37 AM
📢 Announcing the First Workshop on Multilingual and Multicultural Evaluation (MME) at #EACL2026 🇲🇦
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
MME focuses on resources, metrics & methodologies for evaluating multilingual systems! multilingual-multicultural-evaluation.github.io
📅 Workshop Mar 24–29, 2026
🗓️ Submit by Dec 19, 2025
My two biggest take-aways are:
- Standard testsets are too easy (Figure 1).
- We can make testsets that are not easy (Figure 2). 😎
- Standard testsets are too easy (Figure 1).
- We can make testsets that are not easy (Figure 2). 😎


September 16, 2025 at 8:49 AM
My two biggest take-aways are:
- Standard testsets are too easy (Figure 1).
- We can make testsets that are not easy (Figure 2). 😎
- Standard testsets are too easy (Figure 1).
- We can make testsets that are not easy (Figure 2). 😎
Reposted by Vilém Zouhar @ EACL

We saw increased momentum in participation growth this year: 36 unique teams competing to improve the performance of MT. Furthermore, we added collected outputs of 24 popular LLMs and online systems. Reaching 50 evaluated systems in our annual benchmark.
August 23, 2025 at 9:28 AM
We saw increased momentum in participation growth this year: 36 unique teams competing to improve the performance of MT. Furthermore, we added collected outputs of 24 popular LLMs and online systems. Reaching 50 evaluated systems in our annual benchmark.
The 2025 MT Evaluation shared task brings together the strengths of the previous Metrics and Quality Estimation tasks under a single, unified evaluation framework.
The following tasks are now open for participants (deadline July 31st but participation has never been easier 🙂 ):
The following tasks are now open for participants (deadline July 31st but participation has never been easier 🙂 ):
July 25, 2025 at 4:59 PM
The 2025 MT Evaluation shared task brings together the strengths of the previous Metrics and Quality Estimation tasks under a single, unified evaluation framework.
The following tasks are now open for participants (deadline July 31st but participation has never been easier 🙂 ):
The following tasks are now open for participants (deadline July 31st but participation has never been easier 🙂 ):
You have a budget to human-evaluate 100 inputs to your models, but your dataset is 10,000 inputs. Do not just pick 100 randomly!🙅
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)

July 15, 2025 at 1:03 PM
You have a budget to human-evaluate 100 inputs to your models, but your dataset is 10,000 inputs. Do not just pick 100 randomly!🙅
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
We can do better. "How to Select Datapoints for Efficient Human Evaluation of NLG Models?" shows how.🕵️
(random is still a devilishly good baseline)
TIL that since python3.4 there's default `statistics` module with things like mean, mode, quantiles, variance, covariance, correlations, zscore, and more!. No more needless numpy imports!

July 9, 2025 at 12:49 AM
TIL that since python3.4 there's default `statistics` module with things like mean, mode, quantiles, variance, covariance, correlations, zscore, and more!. No more needless numpy imports!
Past iterations of the Terminology Shared Task don't come anywhere near the data quality and evaluation scrutiny of this one. In the era of LLM-as-MTs, participation has never been easier!

📣Take part in 3rd Terminology shared task @WMT!📣
This year:
👉5 language pairs: EN->{ES, RU, DE, ZH},
👉2 tracks - sentence-level and doc-level translation,
👉authentic data from 2 domains: finance and IT!
www2.statmt.org/wmt25/termin...
Don't miss an opportunity - we only do it once in two years😏
This year:
👉5 language pairs: EN->{ES, RU, DE, ZH},
👉2 tracks - sentence-level and doc-level translation,
👉authentic data from 2 domains: finance and IT!
www2.statmt.org/wmt25/termin...
Don't miss an opportunity - we only do it once in two years😏
Terminology Translation Task
www2.statmt.org
July 7, 2025 at 2:34 PM
Past iterations of the Terminology Shared Task don't come anywhere near the data quality and evaluation scrutiny of this one. In the era of LLM-as-MTs, participation has never been easier!
Thank you for your response. I will keep my score.
July 3, 2025 at 6:50 PM
Thank you for your response. I will keep my score.
For the longest time I've been using Google Translate as a gateway to explain machine translation concepts to people as it's a tool that everyone knows. Now I get to contribute over the summer. 🌞
If you're near Mountain View, let's talk evaluation. 📏
If you're near Mountain View, let's talk evaluation. 📏

July 3, 2025 at 4:15 AM
For the longest time I've been using Google Translate as a gateway to explain machine translation concepts to people as it's a tool that everyone knows. Now I get to contribute over the summer. 🌞
If you're near Mountain View, let's talk evaluation. 📏
If you're near Mountain View, let's talk evaluation. 📏
arxiv submission process got an update!
(still requires a manual bbl)
(still requires a manual bbl)

May 31, 2025 at 9:56 AM
arxiv submission process got an update!
(still requires a manual bbl)
(still requires a manual bbl)
Reposted by Vilém Zouhar @ EACL
XCOMETs underperform because they do not match translators' subjective error annotation propensity. Using the granular p(error) value from XCOMET significantly boost their performance when calibration is possible → desirable for a fair evaluation 6/

May 30, 2025 at 2:28 PM
XCOMETs underperform because they do not match translators' subjective error annotation propensity. Using the granular p(error) value from XCOMET significantly boost their performance when calibration is possible → desirable for a fair evaluation 6/
Reposted by Vilém Zouhar @ EACL
Key takeaways for WQE evals:
1️⃣ Unsup. WQE shows promise (esp. uncertainty-based ones), interp approaches under-explored for MT
2️⃣ Calibration sets can help to ensure fair evaluations.
3️⃣ Use multiple annotators for robust rakings.
More info ➡️ arxiv.org/abs/2505.23183 8/8
1️⃣ Unsup. WQE shows promise (esp. uncertainty-based ones), interp approaches under-explored for MT
2️⃣ Calibration sets can help to ensure fair evaluations.
3️⃣ Use multiple annotators for robust rakings.
More info ➡️ arxiv.org/abs/2505.23183 8/8

Unsupervised Word-level Quality Estimation for Machine Translation Through the Lens of Annotators (Dis)agreement
Word-level quality estimation (WQE) aims to automatically identify fine-grained error spans in machine-translated outputs and has found many uses, including assisting translators during post-editing. ...
arxiv.org
May 30, 2025 at 2:28 PM
Key takeaways for WQE evals:
1️⃣ Unsup. WQE shows promise (esp. uncertainty-based ones), interp approaches under-explored for MT
2️⃣ Calibration sets can help to ensure fair evaluations.
3️⃣ Use multiple annotators for robust rakings.
More info ➡️ arxiv.org/abs/2505.23183 8/8
1️⃣ Unsup. WQE shows promise (esp. uncertainty-based ones), interp approaches under-explored for MT
2️⃣ Calibration sets can help to ensure fair evaluations.
3️⃣ Use multiple annotators for robust rakings.
More info ➡️ arxiv.org/abs/2505.23183 8/8
Reposted by Vilém Zouhar @ EACL
📢 New paper: Can unsupervised metrics extracted from MT models detect their translation errors reliably? Do annotators even *agree* on what constitutes an error? 🧐
We compare uncertainty- and interp-based WQE metrics across 12 directions, with some surprising findings!
🧵 1/
We compare uncertainty- and interp-based WQE metrics across 12 directions, with some surprising findings!
🧵 1/

May 30, 2025 at 2:28 PM
📢 New paper: Can unsupervised metrics extracted from MT models detect their translation errors reliably? Do annotators even *agree* on what constitutes an error? 🧐
We compare uncertainty- and interp-based WQE metrics across 12 directions, with some surprising findings!
🧵 1/
We compare uncertainty- and interp-based WQE metrics across 12 directions, with some surprising findings!
🧵 1/
incredible monetization opportunity
(this is a joke)
(this is a joke)

May 14, 2025 at 8:52 AM
incredible monetization opportunity
(this is a joke)
(this is a joke)
Ever looked down from a hot air balloon and despaired at how expensive it is to run thorough human evaluation of machine translation?
Fret no more and come tomorrow at 11:00 to Hall 3 #NAACL2025.
Fret no more and come tomorrow at 11:00 to Hall 3 #NAACL2025.


May 2, 2025 at 12:30 AM
Ever looked down from a hot air balloon and despaired at how expensive it is to run thorough human evaluation of machine translation?
Fret no more and come tomorrow at 11:00 to Hall 3 #NAACL2025.
Fret no more and come tomorrow at 11:00 to Hall 3 #NAACL2025.
Being in a hot air balloon in Albuquerque really makes one ponder *how to efficiently pick the best translation candidate without running expensive evaluation metrics on all of them.*
See you tomorrow at 9:00 in Hall 3 #NAACL2025.
See you tomorrow at 9:00 in Hall 3 #NAACL2025.

May 2, 2025 at 12:26 AM
Being in a hot air balloon in Albuquerque really makes one ponder *how to efficiently pick the best translation candidate without running expensive evaluation metrics on all of them.*
See you tomorrow at 9:00 in Hall 3 #NAACL2025.
See you tomorrow at 9:00 in Hall 3 #NAACL2025.
Multilinguality is happening at #NAACL2025
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social

April 30, 2025 at 11:18 PM
Multilinguality is happening at #NAACL2025
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
@crystinaz.bsky.social
@oxxoskeets.bsky.social
@dayeonki.bsky.social @onadegibert.bsky.social
Let's chat at #NAACL2025 about evaluation et al! ⚗️


April 22, 2025 at 7:35 AM
Let's chat at #NAACL2025 about evaluation et al! ⚗️