




Reposted by Dimitri Meunier

Solenne Gaucher, la mathématicienne qui sort le genre de l’équation

Solenne Gaucher, la mathématicienne qui sort le genre de l’équation
« La Relève ». Chaque mois, « Le Monde Campus » rencontre un jeune qui bouscule les normes dans son domaine. A 31 ans, la docteure en mathématiques s’attaque aux biais algorithmiques de l’intelligence artificielle et a reçu en 2024 un prix pour ses travaux.
www.lemonde.fr
September 21, 2025 at 2:11 PM
Solenne Gaucher, la mathématicienne qui sort le genre de l’équation
Reposted by Dimitri Meunier

AISTATS 2026 will be in Morocco!
July 30, 2025 at 8:07 AM
AISTATS 2026 will be in Morocco!
Reposted by Dimitri Meunier

We've written a monograph on Gaussian processes and reproducing kernel methods (with @philipphennig.bsky.social, @sejdino.bsky.social and Bharath Sriperumbudur).
arxiv.org/abs/2506.17366
arxiv.org/abs/2506.17366

Gaussian Processes and Reproducing Kernels: Connections and Equivalences
This monograph studies the relations between two approaches using positive definite kernels: probabilistic methods using Gaussian processes, and non-probabilistic methods using reproducing kernel Hilb...
arxiv.org
June 24, 2025 at 8:35 AM
We've written a monograph on Gaussian processes and reproducing kernel methods (with @philipphennig.bsky.social, @sejdino.bsky.social and Bharath Sriperumbudur).
arxiv.org/abs/2506.17366
arxiv.org/abs/2506.17366
I have been looking at the draft for a while, I am surprised you had a hard time publishing it, it is a super cool work! Will it be included in the TorchDR package ?
June 27, 2025 at 10:17 AM
I have been looking at the draft for a while, I am surprised you had a hard time publishing it, it is a super cool work! Will it be included in the TorchDR package ?
Reposted by Dimitri Meunier

Distributional Reduction paper with H. Van Assel, @ncourty.bsky.social, T. Vayer , C. Vincent-Cuaz, and @pfrossard.bsky.social is accepted at TMLR. We show that both dimensionality reduction and clustering can be seen as minimizing an optimal transport loss 🧵1/5. openreview.net/forum?id=cll...

June 27, 2025 at 7:44 AM
Distributional Reduction paper with H. Van Assel, @ncourty.bsky.social, T. Vayer , C. Vincent-Cuaz, and @pfrossard.bsky.social is accepted at TMLR. We show that both dimensionality reduction and clustering can be seen as minimizing an optimal transport loss 🧵1/5. openreview.net/forum?id=cll...
Reposted by Dimitri Meunier

Dimitri Meunier, Antoine Moulin, Jakub Wornbard, Vladimir R. Kostic, Arthur Gretton
Demystifying Spectral Feature Learning for Instrumental Variable Regression
https://arxiv.org/abs/2506.10899
Demystifying Spectral Feature Learning for Instrumental Variable Regression
https://arxiv.org/abs/2506.10899
June 13, 2025 at 4:37 AM
Dimitri Meunier, Antoine Moulin, Jakub Wornbard, Vladimir R. Kostic, Arthur Gretton
Demystifying Spectral Feature Learning for Instrumental Variable Regression
https://arxiv.org/abs/2506.10899
Demystifying Spectral Feature Learning for Instrumental Variable Regression
https://arxiv.org/abs/2506.10899
Very much looking forward to this ! 🙌 Stellar line-up

Announcing : The 2nd International Summer School on Mathematical Aspects of Data Science
mathsdata2025.github.io
EPFL, Sept 1–5, 2025
Speakers:
Bach @bachfrancis.bsky.social
Bandeira
Mallat
Montanari
Peyré @gabrielpeyre.bsky.social
For PhD students & early-career researchers
Apply before May 15!
mathsdata2025.github.io
EPFL, Sept 1–5, 2025
Speakers:
Bach @bachfrancis.bsky.social
Bandeira
Mallat
Montanari
Peyré @gabrielpeyre.bsky.social
For PhD students & early-career researchers
Apply before May 15!
Mathematical Aspects of Data Science
Graduate Summer School - EPFL - Sept. 1-5, 2025
mathsdata2025.github.io
May 29, 2025 at 2:41 PM
Very much looking forward to this ! 🙌 Stellar line-up
Reposted by Dimitri Meunier

new preprint with the amazing @lviano.bsky.social and @neu-rips.bsky.social on offline imitation learning! learned a lot :)
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!


May 27, 2025 at 7:13 AM
new preprint with the amazing @lviano.bsky.social and @neu-rips.bsky.social on offline imitation learning! learned a lot :)
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!
when the expert is hard to represent but the environment is simple, estimating a Q-value rather than the expert directly may be beneficial. lots of open questions left though!
TL;DR:
✅ Theoretical guarantees for nonlinear meta-learning
✅ Explains when and how aggregation helps
✅ Connects RKHS regression, subspace estimation & meta-learning
Co-led with Zhu Li 🙌, with invaluable support from @arthurgretton.bsky.social, Samory Kpotufe.
✅ Theoretical guarantees for nonlinear meta-learning
✅ Explains when and how aggregation helps
✅ Connects RKHS regression, subspace estimation & meta-learning
Co-led with Zhu Li 🙌, with invaluable support from @arthurgretton.bsky.social, Samory Kpotufe.
May 26, 2025 at 4:50 PM
TL;DR:
✅ Theoretical guarantees for nonlinear meta-learning
✅ Explains when and how aggregation helps
✅ Connects RKHS regression, subspace estimation & meta-learning
Co-led with Zhu Li 🙌, with invaluable support from @arthurgretton.bsky.social, Samory Kpotufe.
✅ Theoretical guarantees for nonlinear meta-learning
✅ Explains when and how aggregation helps
✅ Connects RKHS regression, subspace estimation & meta-learning
Co-led with Zhu Li 🙌, with invaluable support from @arthurgretton.bsky.social, Samory Kpotufe.
Even with nonlinear representation you can estimate the shared structure at a rate improving in both N (tasks) and n (samples per task). This leads to parametric rates on the target task!⚡
Bonus: for linear kernels, our results recover known linear meta-learning rates.
Bonus: for linear kernels, our results recover known linear meta-learning rates.
May 26, 2025 at 4:50 PM
Even with nonlinear representation you can estimate the shared structure at a rate improving in both N (tasks) and n (samples per task). This leads to parametric rates on the target task!⚡
Bonus: for linear kernels, our results recover known linear meta-learning rates.
Bonus: for linear kernels, our results recover known linear meta-learning rates.
Short answer: Yes ✅
Key idea💡: Instead of learning each task well, under-regularise per-task estimators to better estimate the shared subspace in the RKHS.
Even though each task is noisy, their span reveals the structure we care about.
Bias-variance tradeoff in action.
Key idea💡: Instead of learning each task well, under-regularise per-task estimators to better estimate the shared subspace in the RKHS.
Even though each task is noisy, their span reveals the structure we care about.
Bias-variance tradeoff in action.
May 26, 2025 at 4:50 PM
Short answer: Yes ✅
Key idea💡: Instead of learning each task well, under-regularise per-task estimators to better estimate the shared subspace in the RKHS.
Even though each task is noisy, their span reveals the structure we care about.
Bias-variance tradeoff in action.
Key idea💡: Instead of learning each task well, under-regularise per-task estimators to better estimate the shared subspace in the RKHS.
Even though each task is noisy, their span reveals the structure we care about.
Bias-variance tradeoff in action.
Our paper analyses a meta-learning setting where tasks share a finite dimensional subspace of a Reproducing Kernel Hilbert Space.
Can we still estimate this shared representation efficiently — and learn new tasks fast?
Can we still estimate this shared representation efficiently — and learn new tasks fast?
May 26, 2025 at 4:50 PM
Our paper analyses a meta-learning setting where tasks share a finite dimensional subspace of a Reproducing Kernel Hilbert Space.
Can we still estimate this shared representation efficiently — and learn new tasks fast?
Can we still estimate this shared representation efficiently — and learn new tasks fast?
Most prior theory assumes linear structure: All tasks share a linear representation, and task-specific parts are also linear.
Then: we can show improved learning rates as the number of tasks increases.
But reality is nonlinear. What then?
Then: we can show improved learning rates as the number of tasks increases.
But reality is nonlinear. What then?
May 26, 2025 at 4:50 PM
Most prior theory assumes linear structure: All tasks share a linear representation, and task-specific parts are also linear.
Then: we can show improved learning rates as the number of tasks increases.
But reality is nonlinear. What then?
Then: we can show improved learning rates as the number of tasks increases.
But reality is nonlinear. What then?
Meta-learning = using many related tasks to help learn new ones faster.
In practice (e.g. with neural nets), this usually means learning a shared representation across tasks — so we can train quickly on unseen ones.
But: what’s the theory behind this? 🤔
In practice (e.g. with neural nets), this usually means learning a shared representation across tasks — so we can train quickly on unseen ones.
But: what’s the theory behind this? 🤔
May 26, 2025 at 4:50 PM
Meta-learning = using many related tasks to help learn new ones faster.
In practice (e.g. with neural nets), this usually means learning a shared representation across tasks — so we can train quickly on unseen ones.
But: what’s the theory behind this? 🤔
In practice (e.g. with neural nets), this usually means learning a shared representation across tasks — so we can train quickly on unseen ones.
But: what’s the theory behind this? 🤔
🚨 New paper accepted at SIMODS! 🚨
“Nonlinear Meta-learning Can Guarantee Faster Rates”
arxiv.org/abs/2307.10870
When does meta learning work? Spoiler: generalise to new tasks by overfitting on your training tasks!
Here is why:
🧵👇
“Nonlinear Meta-learning Can Guarantee Faster Rates”
arxiv.org/abs/2307.10870
When does meta learning work? Spoiler: generalise to new tasks by overfitting on your training tasks!
Here is why:
🧵👇

Nonlinear Meta-Learning Can Guarantee Faster Rates
Many recent theoretical works on \emph{meta-learning} aim to achieve guarantees in leveraging similar representational structures from related tasks towards simplifying a target task. The main aim of ...
arxiv.org
May 26, 2025 at 4:50 PM
🚨 New paper accepted at SIMODS! 🚨
“Nonlinear Meta-learning Can Guarantee Faster Rates”
arxiv.org/abs/2307.10870
When does meta learning work? Spoiler: generalise to new tasks by overfitting on your training tasks!
Here is why:
🧵👇
“Nonlinear Meta-learning Can Guarantee Faster Rates”
arxiv.org/abs/2307.10870
When does meta learning work? Spoiler: generalise to new tasks by overfitting on your training tasks!
Here is why:
🧵👇
Reposted by Dimitri Meunier
Dimitri Meunier, Zikai Shen, Mattes Mollenhauer, Arthur Gretton, Zhu Li
Optimal Rates for Vector-Valued Spectral Regularization Learning Algorithms
https://arxiv.org/abs/2405.14778
Optimal Rates for Vector-Valued Spectral Regularization Learning Algorithms
https://arxiv.org/abs/2405.14778
May 24, 2024 at 4:06 AM
Dimitri Meunier, Zikai Shen, Mattes Mollenhauer, Arthur Gretton, Zhu Li
Optimal Rates for Vector-Valued Spectral Regularization Learning Algorithms
https://arxiv.org/abs/2405.14778
Optimal Rates for Vector-Valued Spectral Regularization Learning Algorithms
https://arxiv.org/abs/2405.14778
Reposted by Dimitri Meunier

Mattes Mollenhauer, Nicole M\"ucke, Dimitri Meunier, Arthur Gretton: Regularized least squares learning with heavy-tailed noise is minimax optimal https://arxiv.org/abs/2505.14214 https://arxiv.org/pdf/2505.14214 https://arxiv.org/html/2505.14214
May 21, 2025 at 6:14 AM
Mattes Mollenhauer, Nicole M\"ucke, Dimitri Meunier, Arthur Gretton: Regularized least squares learning with heavy-tailed noise is minimax optimal https://arxiv.org/abs/2505.14214 https://arxiv.org/pdf/2505.14214 https://arxiv.org/html/2505.14214
Reposted by Dimitri Meunier

I have updated my slides on the maths of AI by an optimal pairing between AI and maths researchers ... speakerdeck.com/gpeyre/the-m...
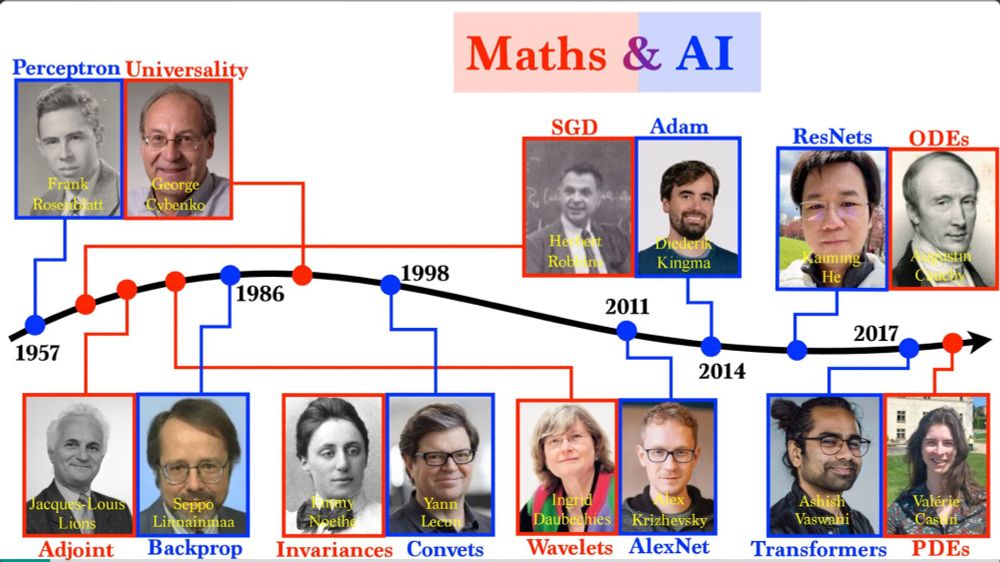
May 20, 2025 at 11:21 AM
I have updated my slides on the maths of AI by an optimal pairing between AI and maths researchers ... speakerdeck.com/gpeyre/the-m...
Reposted by Dimitri Meunier
I have cleaned a bit my lecture notes on Optimal Transport for Machine Learners arxiv.org/abs/2505.06589

Optimal Transport for Machine Learners
Optimal Transport is a foundational mathematical theory that connects optimization, partial differential equations, and probability. It offers a powerful framework for comparing probability distributi...
arxiv.org
May 13, 2025 at 5:18 AM
I have cleaned a bit my lecture notes on Optimal Transport for Machine Learners arxiv.org/abs/2505.06589
Reposted by Dimitri Meunier
May 13, 2025 at 6:48 AM
Reposted by Dimitri Meunier

New ICML 2025 paper: Nested expectations with kernel quadrature.
We propose an algorithm to estimate nested expectations which provides orders of magnitude improvements in low-to-mid dimensional smooth nested expectations using kernel ridge regression/kernel quadrature.
arxiv.org/abs/2502.18284
We propose an algorithm to estimate nested expectations which provides orders of magnitude improvements in low-to-mid dimensional smooth nested expectations using kernel ridge regression/kernel quadrature.
arxiv.org/abs/2502.18284

May 8, 2025 at 4:29 AM
New ICML 2025 paper: Nested expectations with kernel quadrature.
We propose an algorithm to estimate nested expectations which provides orders of magnitude improvements in low-to-mid dimensional smooth nested expectations using kernel ridge regression/kernel quadrature.
arxiv.org/abs/2502.18284
We propose an algorithm to estimate nested expectations which provides orders of magnitude improvements in low-to-mid dimensional smooth nested expectations using kernel ridge regression/kernel quadrature.
arxiv.org/abs/2502.18284
Great talk by Aapo Hyvärinen on non linear ICA at AISTATS 25’!

May 4, 2025 at 2:57 AM
Great talk by Aapo Hyvärinen on non linear ICA at AISTATS 25’!
Reposted by Dimitri Meunier
Density Ratio-based Proxy Causal Learning Without Density Ratios 🤔
at #AISTATS2025
An alternative bridge function for proxy causal learning with hidden confounders.
arxiv.org/abs/2503.08371
Bozkurt, Deaner, @dimitrimeunier.bsky.social, Xu
at #AISTATS2025
An alternative bridge function for proxy causal learning with hidden confounders.
arxiv.org/abs/2503.08371
Bozkurt, Deaner, @dimitrimeunier.bsky.social, Xu

May 2, 2025 at 11:29 AM
Density Ratio-based Proxy Causal Learning Without Density Ratios 🤔
at #AISTATS2025
An alternative bridge function for proxy causal learning with hidden confounders.
arxiv.org/abs/2503.08371
Bozkurt, Deaner, @dimitrimeunier.bsky.social, Xu
at #AISTATS2025
An alternative bridge function for proxy causal learning with hidden confounders.
arxiv.org/abs/2503.08371
Bozkurt, Deaner, @dimitrimeunier.bsky.social, Xu
Reposted by Dimitri Meunier

Link to the video: youtu.be/nLGBTMfTvr8?...

Interview of Statistics and ML Expert - Pierre Alquier
YouTube video by ML New Papers
youtu.be
April 28, 2025 at 11:01 AM
Link to the video: youtu.be/nLGBTMfTvr8?...