



Donatella Genovese
@donatellag.bsky.social
PhD Student | Works on Explainable AI | https://donatellagenovese.github.io/
Reposted by Donatella Genovese

Please share it within your circles! edin.ac/3DDQK1o

March 13, 2025 at 11:59 AM
Please share it within your circles! edin.ac/3DDQK1o
Really cool paper by @kayoyin.bsky.social about interpretability of In Context Learning, they found that Function Vectors (FV) heads are crucial for few-shot ICL.
www.arxiv.org/abs/2502.14010
www.arxiv.org/abs/2502.14010

February 28, 2025 at 4:52 PM
Really cool paper by @kayoyin.bsky.social about interpretability of In Context Learning, they found that Function Vectors (FV) heads are crucial for few-shot ICL.
www.arxiv.org/abs/2502.14010
www.arxiv.org/abs/2502.14010
A really nice resource for understanding how to parallelize LLM training.

After 6+ months in the making and over a year of GPU compute, we're excited to release the "Ultra-Scale Playbook": hf.co/spaces/nanot...
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!
A book to learn all about 5D parallelism, ZeRO, CUDA kernels, how/why overlap compute & coms with theory, motivation, interactive plots and 4000+ experiments!

The Ultra-Scale Playbook - a Hugging Face Space by nanotron
The ultimate guide to training LLM on large GPU Clusters
hf.co
February 21, 2025 at 11:12 AM
A really nice resource for understanding how to parallelize LLM training.
🚀 Meta’s new LLM pretraining framework predicts concepts and integrates them into its hidden state to enhance next-token prediction. 🚀
It achieves the same performance with 21.5% fewer tokens and better generalization! 🎯
📝: arxiv.org/abs/2502.08524
It achieves the same performance with 21.5% fewer tokens and better generalization! 🎯
📝: arxiv.org/abs/2502.08524

February 14, 2025 at 1:07 PM
🚀 Meta’s new LLM pretraining framework predicts concepts and integrates them into its hidden state to enhance next-token prediction. 🚀
It achieves the same performance with 21.5% fewer tokens and better generalization! 🎯
📝: arxiv.org/abs/2502.08524
It achieves the same performance with 21.5% fewer tokens and better generalization! 🎯
📝: arxiv.org/abs/2502.08524
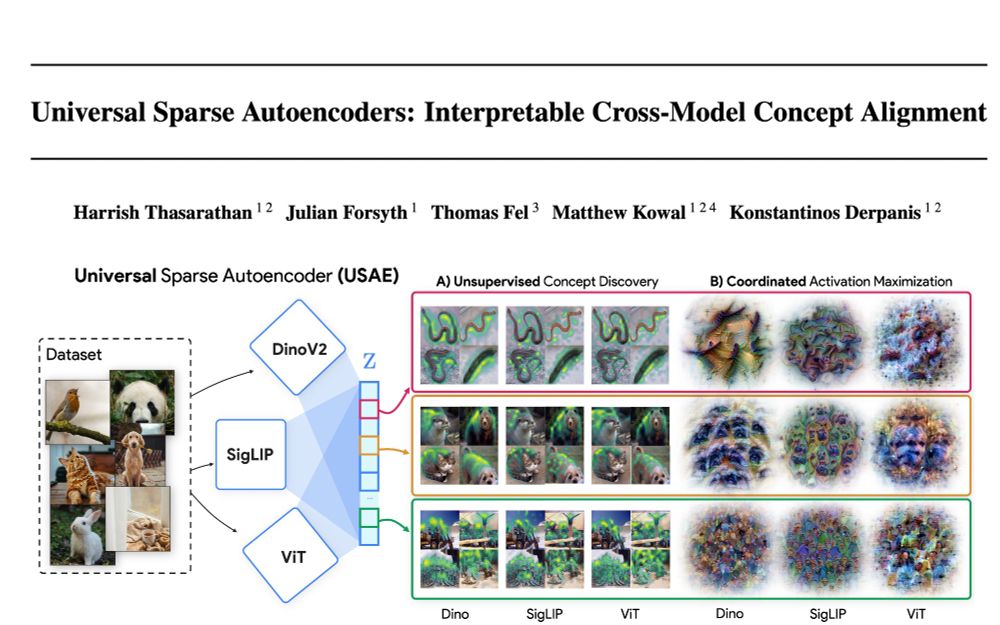
A very interesting work that explores the possibility of having a unified interpretation across multiple models

🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
February 9, 2025 at 9:13 AM
A very interesting work that explores the possibility of having a unified interpretation across multiple models
Reposted by Donatella Genovese

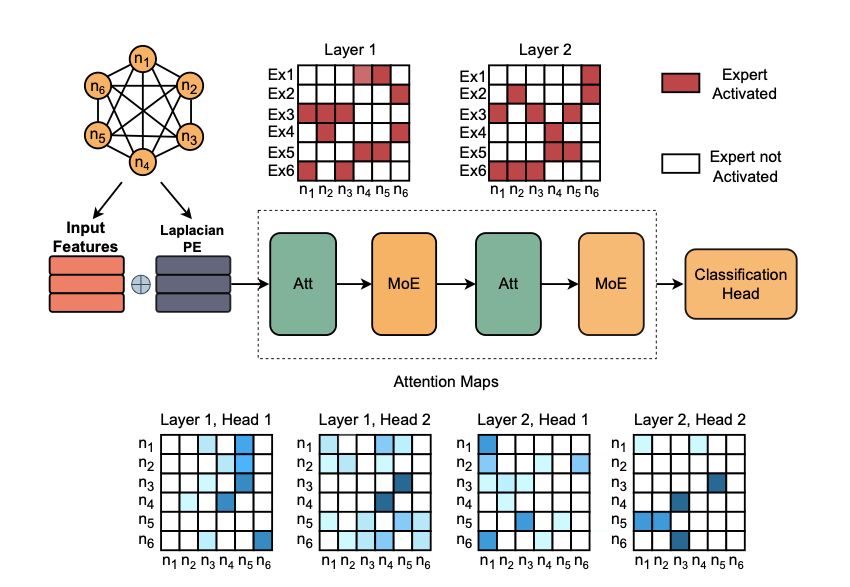
*MoE Graph Transformers for Interpretable Particle Collision Detection*
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
January 10, 2025 at 2:12 PM
*MoE Graph Transformers for Interpretable Particle Collision Detection*
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432