




Harry Thasarathan
@hthasarathan.bsky.social
PhD student @YorkUniversity @LassondeSchool, I work on computer vision and interpretability.
🌌🛰️🔭Want to explore universal visual features? Check out our interactive demo of concepts learned from our #ICML2025 paper "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment".
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
July 15, 2025 at 2:36 AM
🌌🛰️🔭Want to explore universal visual features? Check out our interactive demo of concepts learned from our #ICML2025 paper "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment".
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Come see our poster at 4pm on Tuesday in East Exhibition hall A-B, E-1208!
Our work finding universal concepts in vision models is accepted at #ICML2025!!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
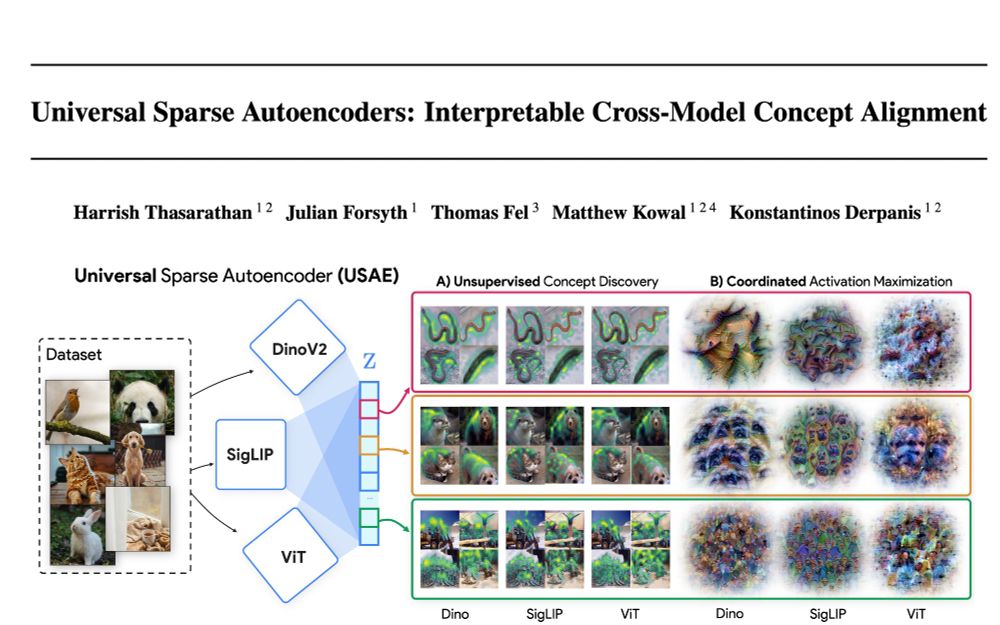
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
May 1, 2025 at 10:57 PM
Our work finding universal concepts in vision models is accepted at #ICML2025!!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
My first major conference paper with my wonderful collaborators and friends @matthewkowal.bsky.social @thomasfel.bsky.social
@Julian_Forsyth
@csprofkgd.bsky.social
Working with y'all is the best 🥹
Preprint ⬇️!!
Reposted by Harry Thasarathan

Accepted at #ICML2025! Check out the preprint.
HUGE shoutout to Harry (1st PhD paper, in 1st year), Julian (1st ever, done as an undergrad), Thomas and Matt!
@hthasarathan.bsky.social @thomasfel.bsky.social @matthewkowal.bsky.social
HUGE shoutout to Harry (1st PhD paper, in 1st year), Julian (1st ever, done as an undergrad), Thomas and Matt!
@hthasarathan.bsky.social @thomasfel.bsky.social @matthewkowal.bsky.social
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
May 1, 2025 at 3:03 PM
Accepted at #ICML2025! Check out the preprint.
HUGE shoutout to Harry (1st PhD paper, in 1st year), Julian (1st ever, done as an undergrad), Thomas and Matt!
@hthasarathan.bsky.social @thomasfel.bsky.social @matthewkowal.bsky.social
HUGE shoutout to Harry (1st PhD paper, in 1st year), Julian (1st ever, done as an undergrad), Thomas and Matt!
@hthasarathan.bsky.social @thomasfel.bsky.social @matthewkowal.bsky.social
Reposted by Harry Thasarathan

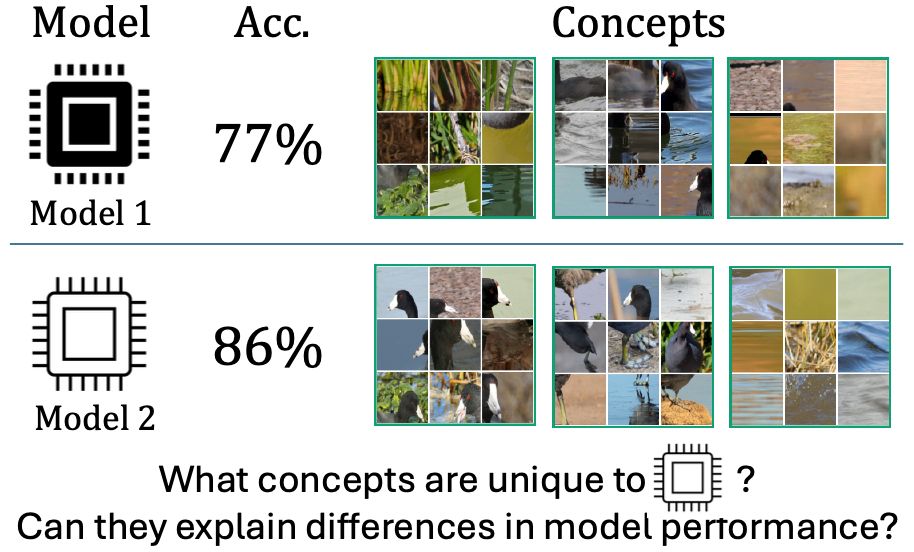
Check out Neehar Kondapaneni's upcoming ICLR 2025 work which proposes a new approach for understanding how two neural networks differ by discovering the shared and unique concepts learned by the networks.
Representational Similarity via Interpretable Visual Concepts
arxiv.org/abs/2503.15699
Representational Similarity via Interpretable Visual Concepts
arxiv.org/abs/2503.15699

Have you ever wondered what makes two models different?
We all know the ViT-Large performs better than the Resnet-50, but what visual concepts drive this difference? Our new ICLR 2025 paper addresses this question! nkondapa.github.io/rsvc-page/
We all know the ViT-Large performs better than the Resnet-50, but what visual concepts drive this difference? Our new ICLR 2025 paper addresses this question! nkondapa.github.io/rsvc-page/
April 12, 2025 at 7:58 AM
Check out Neehar Kondapaneni's upcoming ICLR 2025 work which proposes a new approach for understanding how two neural networks differ by discovering the shared and unique concepts learned by the networks.
Representational Similarity via Interpretable Visual Concepts
arxiv.org/abs/2503.15699
Representational Similarity via Interpretable Visual Concepts
arxiv.org/abs/2503.15699
Reposted by Harry Thasarathan

A very interesting work that explores the possibility of having a unified interpretation across multiple models
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
February 9, 2025 at 9:13 AM
A very interesting work that explores the possibility of having a unified interpretation across multiple models
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)
February 7, 2025 at 3:15 PM
🌌🛰️🔭Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"!
arxiv.org/abs/2502.03714
(1/9)
arxiv.org/abs/2502.03714
(1/9)