



Eugene Berta
@eberta.bsky.social
PhD student at INRIA Paris. Working on calibration of machine learning classifiers.
Pinned
Eugene Berta
@eberta.bsky.social
· Nov 13



Still using temperature scaling?
With @dholzmueller.bsky.social, Michael I. Jordan and @bachfrancis.bsky.social we argue that with well designed regularization, more expressive models like matrix scaling can outperform simpler ones across calibration set sizes, data dimensions, and applications.
With @dholzmueller.bsky.social, Michael I. Jordan and @bachfrancis.bsky.social we argue that with well designed regularization, more expressive models like matrix scaling can outperform simpler ones across calibration set sizes, data dimensions, and applications.
Still using temperature scaling?
With @dholzmueller.bsky.social, Michael I. Jordan and @bachfrancis.bsky.social we argue that with well designed regularization, more expressive models like matrix scaling can outperform simpler ones across calibration set sizes, data dimensions, and applications.
With @dholzmueller.bsky.social, Michael I. Jordan and @bachfrancis.bsky.social we argue that with well designed regularization, more expressive models like matrix scaling can outperform simpler ones across calibration set sizes, data dimensions, and applications.
November 13, 2025 at 12:27 PM
Still using temperature scaling?
With @dholzmueller.bsky.social, Michael I. Jordan and @bachfrancis.bsky.social we argue that with well designed regularization, more expressive models like matrix scaling can outperform simpler ones across calibration set sizes, data dimensions, and applications.
With @dholzmueller.bsky.social, Michael I. Jordan and @bachfrancis.bsky.social we argue that with well designed regularization, more expressive models like matrix scaling can outperform simpler ones across calibration set sizes, data dimensions, and applications.
Reposted by Eugene Berta

COLT Workshop on Predictions and Uncertainty was a banger!
I was lucky to present our paper "Minimum Volume Conformal Sets for Multivariate Regression", alongside my colleague @eberta.bsky.social and his awsome work on calibration.
Big thanks to the organizers!
#ConformalPrediction #MarcoPolo
I was lucky to present our paper "Minimum Volume Conformal Sets for Multivariate Regression", alongside my colleague @eberta.bsky.social and his awsome work on calibration.
Big thanks to the organizers!
#ConformalPrediction #MarcoPolo
July 9, 2025 at 4:58 PM
COLT Workshop on Predictions and Uncertainty was a banger!
I was lucky to present our paper "Minimum Volume Conformal Sets for Multivariate Regression", alongside my colleague @eberta.bsky.social and his awsome work on calibration.
Big thanks to the organizers!
#ConformalPrediction #MarcoPolo
I was lucky to present our paper "Minimum Volume Conformal Sets for Multivariate Regression", alongside my colleague @eberta.bsky.social and his awsome work on calibration.
Big thanks to the organizers!
#ConformalPrediction #MarcoPolo
Reposted by Eugene Berta

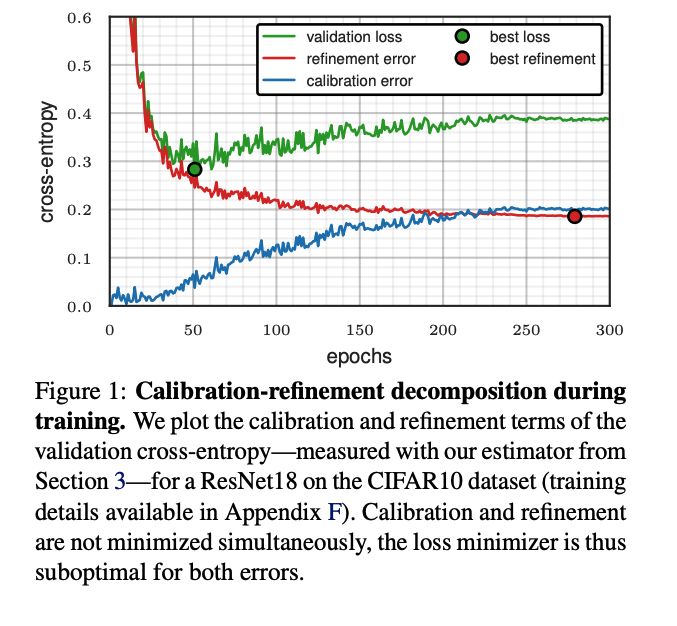
What if we have been doing early stopping wrong all along?
When you break the validation loss into two terms, calibration and refinement
you can make the simplest (efficient) trick to stop training in a smarter position
When you break the validation loss into two terms, calibration and refinement
you can make the simplest (efficient) trick to stop training in a smarter position
April 8, 2025 at 3:22 PM
What if we have been doing early stopping wrong all along?
When you break the validation loss into two terms, calibration and refinement
you can make the simplest (efficient) trick to stop training in a smarter position
When you break the validation loss into two terms, calibration and refinement
you can make the simplest (efficient) trick to stop training in a smarter position
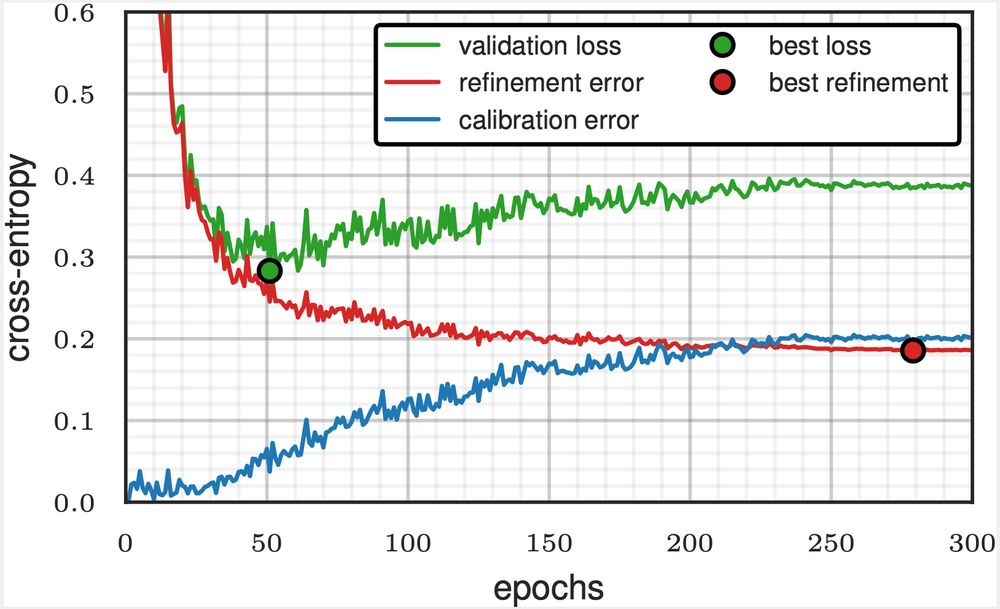
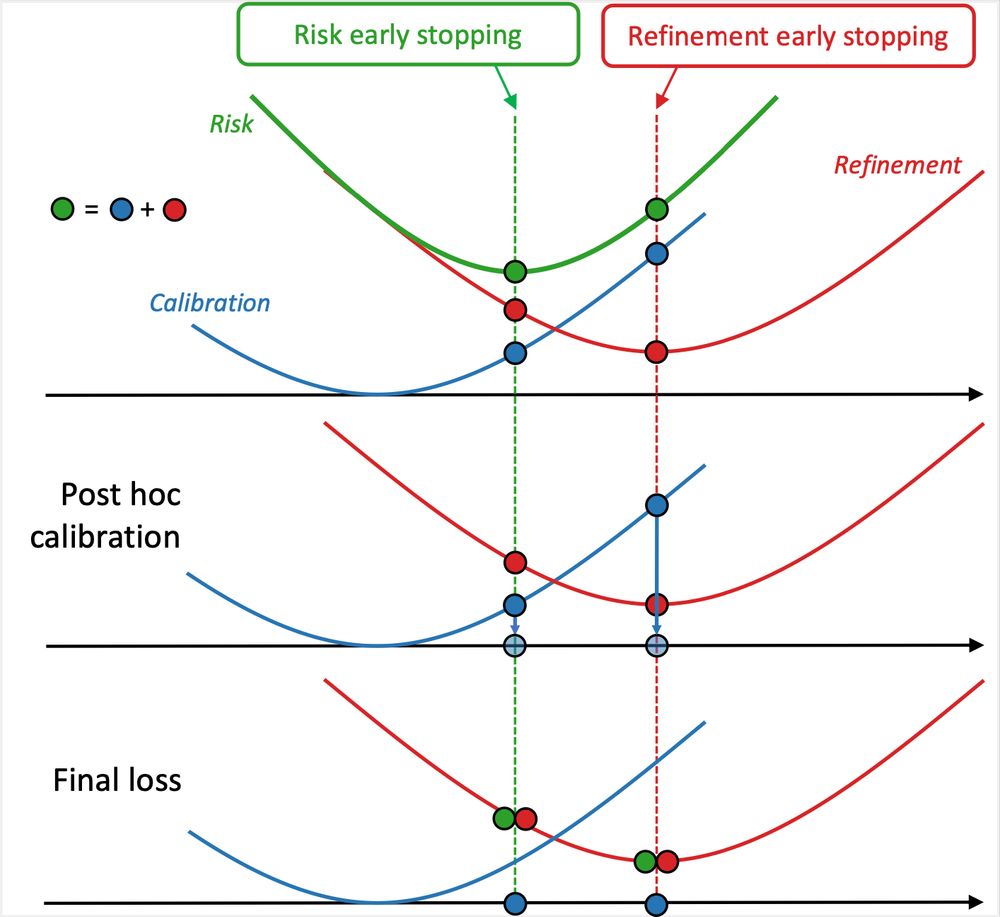
Early stopping on validation loss? This leads to suboptimal calibration and refinement errors—but you can do better!
With @dholzmueller.bsky.social, Michael I. Jordan, and @bachfrancis.bsky.social, we propose a method that integrates with any model and boosts classification performance across tasks.
With @dholzmueller.bsky.social, Michael I. Jordan, and @bachfrancis.bsky.social, we propose a method that integrates with any model and boosts classification performance across tasks.
February 3, 2025 at 1:03 PM
Early stopping on validation loss? This leads to suboptimal calibration and refinement errors—but you can do better!
With @dholzmueller.bsky.social, Michael I. Jordan, and @bachfrancis.bsky.social, we propose a method that integrates with any model and boosts classification performance across tasks.
With @dholzmueller.bsky.social, Michael I. Jordan, and @bachfrancis.bsky.social, we propose a method that integrates with any model and boosts classification performance across tasks.