



Zhenjun Zhao
@ericzzj.bsky.social
ericzzj1989.github.io
PhD from CUHK. 3D vision, SLAM, SfM, Image Matching (https://github.com/ericzzj1989/Awesome-Image-Matching).
PhD from CUHK. 3D vision, SLAM, SfM, Image Matching (https://github.com/ericzzj1989/Awesome-Image-Matching).
Pinned
Zhenjun Zhao
@ericzzj.bsky.social
· May 9
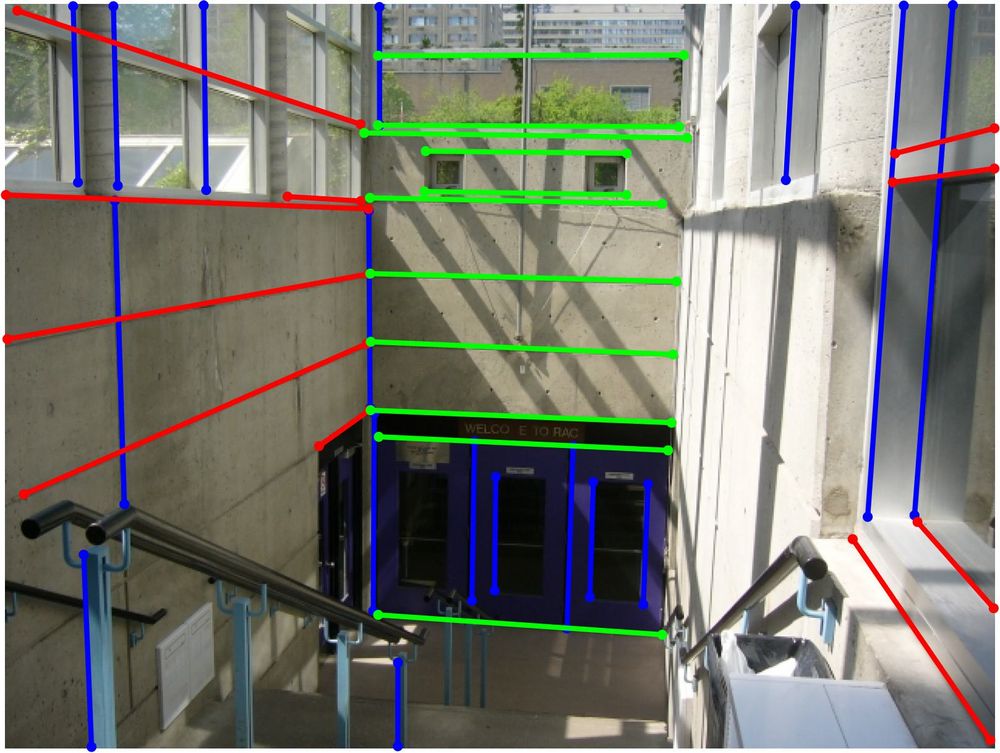
🎉 Thrilled to share our CVPR 2025 Award Candidate & Oral paper:
🔹 GlobustVP
Convex Relaxation for Robust Vanishing Point Estimation in Manhattan World
🧱 Global optimality
💥 Tolerates up to 70% outliers
⚡ Fast runtime
📄 Paper: arxiv.org/abs/2505.04788
💻 Code: github.com/WU-CVGL/GlobustVP
1/
🔹 GlobustVP
Convex Relaxation for Robust Vanishing Point Estimation in Manhattan World
🧱 Global optimality
💥 Tolerates up to 70% outliers
⚡ Fast runtime
📄 Paper: arxiv.org/abs/2505.04788
💻 Code: github.com/WU-CVGL/GlobustVP
1/
CLIDD: Cross-Layer Independent Deformable Description for Efficient and Discriminative Local Feature Representation
Haodi Yao, Fenghua He, Ning Hao, Yao Su
tl;dr: different feature scales->sampled offsets->sampled features->aggregated descriptor
arxiv.org/abs/2601.09230
Haodi Yao, Fenghua He, Ning Hao, Yao Su
tl;dr: different feature scales->sampled offsets->sampled features->aggregated descriptor
arxiv.org/abs/2601.09230




January 15, 2026 at 2:23 PM
CLIDD: Cross-Layer Independent Deformable Description for Efficient and Discriminative Local Feature Representation
Haodi Yao, Fenghua He, Ning Hao, Yao Su
tl;dr: different feature scales->sampled offsets->sampled features->aggregated descriptor
arxiv.org/abs/2601.09230
Haodi Yao, Fenghua He, Ning Hao, Yao Su
tl;dr: different feature scales->sampled offsets->sampled features->aggregated descriptor
arxiv.org/abs/2601.09230
A2TG: Adaptive Anisotropic Textured Gaussians for Efficient 3D Scene Representation
Sheng-Chi Hsu, Ting-Yu Yen, Shih-Hsuan Hung, Hung-Kuo Chu
tl;dr: anisotropic texture->primitive; gradient-based adaptive texture control->resolution and aspect ratio
arxiv.org/abs/2601.09243
Sheng-Chi Hsu, Ting-Yu Yen, Shih-Hsuan Hung, Hung-Kuo Chu
tl;dr: anisotropic texture->primitive; gradient-based adaptive texture control->resolution and aspect ratio
arxiv.org/abs/2601.09243




January 15, 2026 at 2:22 PM
A2TG: Adaptive Anisotropic Textured Gaussians for Efficient 3D Scene Representation
Sheng-Chi Hsu, Ting-Yu Yen, Shih-Hsuan Hung, Hung-Kuo Chu
tl;dr: anisotropic texture->primitive; gradient-based adaptive texture control->resolution and aspect ratio
arxiv.org/abs/2601.09243
Sheng-Chi Hsu, Ting-Yu Yen, Shih-Hsuan Hung, Hung-Kuo Chu
tl;dr: anisotropic texture->primitive; gradient-based adaptive texture control->resolution and aspect ratio
arxiv.org/abs/2601.09243
TIDI-GS: Floater Suppression in 3D Gaussian Splatting for Enhanced Indoor Scene Fidelity
Sooyeun Yang, Cheyul Im, Jee Won Lee, Jongseong Brad Choi
tl;dr: evidence and contex->cleanup->3DGS; monocular depth regularizer
arxiv.org/abs/2601.09291
Sooyeun Yang, Cheyul Im, Jee Won Lee, Jongseong Brad Choi
tl;dr: evidence and contex->cleanup->3DGS; monocular depth regularizer
arxiv.org/abs/2601.09291



January 15, 2026 at 2:22 PM
TIDI-GS: Floater Suppression in 3D Gaussian Splatting for Enhanced Indoor Scene Fidelity
Sooyeun Yang, Cheyul Im, Jee Won Lee, Jongseong Brad Choi
tl;dr: evidence and contex->cleanup->3DGS; monocular depth regularizer
arxiv.org/abs/2601.09291
Sooyeun Yang, Cheyul Im, Jee Won Lee, Jongseong Brad Choi
tl;dr: evidence and contex->cleanup->3DGS; monocular depth regularizer
arxiv.org/abs/2601.09291
SCE-SLAM: Scale-Consistent Monocular SLAM via Scene Coordinate Embeddings
Yuchen Wu, Jiahe Li, Xiaohan Yu, Lina Yu, Jin Zheng, Xiao Bai
tl;dr: DPVO+flow/scene coordinate branches; spatially nearby historical patches->attention->scale; scene coordinate BA->pose+scale
arxiv.org/abs/2601.09665
Yuchen Wu, Jiahe Li, Xiaohan Yu, Lina Yu, Jin Zheng, Xiao Bai
tl;dr: DPVO+flow/scene coordinate branches; spatially nearby historical patches->attention->scale; scene coordinate BA->pose+scale
arxiv.org/abs/2601.09665




January 15, 2026 at 2:21 PM
SCE-SLAM: Scale-Consistent Monocular SLAM via Scene Coordinate Embeddings
Yuchen Wu, Jiahe Li, Xiaohan Yu, Lina Yu, Jin Zheng, Xiao Bai
tl;dr: DPVO+flow/scene coordinate branches; spatially nearby historical patches->attention->scale; scene coordinate BA->pose+scale
arxiv.org/abs/2601.09665
Yuchen Wu, Jiahe Li, Xiaohan Yu, Lina Yu, Jin Zheng, Xiao Bai
tl;dr: DPVO+flow/scene coordinate branches; spatially nearby historical patches->attention->scale; scene coordinate BA->pose+scale
arxiv.org/abs/2601.09665
FeatureSLAM: Feature-enriched 3D gaussian splatting SLAM in real time
Christopher Thirgood, Oscar Mendez, Erin Ling, Jon Storey, Simon Hadfield
tl;dr: SAM2+GS SLAM
arxiv.org/abs/2601.05738
Christopher Thirgood, Oscar Mendez, Erin Ling, Jon Storey, Simon Hadfield
tl;dr: SAM2+GS SLAM
arxiv.org/abs/2601.05738




January 15, 2026 at 2:21 PM
FeatureSLAM: Feature-enriched 3D gaussian splatting SLAM in real time
Christopher Thirgood, Oscar Mendez, Erin Ling, Jon Storey, Simon Hadfield
tl;dr: SAM2+GS SLAM
arxiv.org/abs/2601.05738
Christopher Thirgood, Oscar Mendez, Erin Ling, Jon Storey, Simon Hadfield
tl;dr: SAM2+GS SLAM
arxiv.org/abs/2601.05738
V-DPM: 4D Video Reconstruction with Dynamic Point Maps
Edgar Sucar, Eldar Insafutdinov, Zihang Lai, Andrea Vedaldi
tl;dr: VGGT+ time-variant/invariant point maps
arxiv.org/abs/2601.09499
Edgar Sucar, Eldar Insafutdinov, Zihang Lai, Andrea Vedaldi
tl;dr: VGGT+ time-variant/invariant point maps
arxiv.org/abs/2601.09499




January 15, 2026 at 2:20 PM
V-DPM: 4D Video Reconstruction with Dynamic Point Maps
Edgar Sucar, Eldar Insafutdinov, Zihang Lai, Andrea Vedaldi
tl;dr: VGGT+ time-variant/invariant point maps
arxiv.org/abs/2601.09499
Edgar Sucar, Eldar Insafutdinov, Zihang Lai, Andrea Vedaldi
tl;dr: VGGT+ time-variant/invariant point maps
arxiv.org/abs/2601.09499
From Rays to Projections: Better Inputs for Feed-Forward View Synthesis
Zirui Wu, Zeren Jiang, @martin-r-oswald.bsky.social, Jie Song
tl;dr: context views->MapAnything->depth maps->rasterizing->point cloud projection image->fine-tuning
arxiv.org/abs/2601.05116
Zirui Wu, Zeren Jiang, @martin-r-oswald.bsky.social, Jie Song
tl;dr: context views->MapAnything->depth maps->rasterizing->point cloud projection image->fine-tuning
arxiv.org/abs/2601.05116




January 9, 2026 at 8:13 PM
From Rays to Projections: Better Inputs for Feed-Forward View Synthesis
Zirui Wu, Zeren Jiang, @martin-r-oswald.bsky.social, Jie Song
tl;dr: context views->MapAnything->depth maps->rasterizing->point cloud projection image->fine-tuning
arxiv.org/abs/2601.05116
Zirui Wu, Zeren Jiang, @martin-r-oswald.bsky.social, Jie Song
tl;dr: context views->MapAnything->depth maps->rasterizing->point cloud projection image->fine-tuning
arxiv.org/abs/2601.05116
MoE3D: A Mixture-of-Experts Module for 3D Reconstruction
Zichen Wang, Ang Cao, Liam J. Wang, Jeong Joon Park
tl;dr: multiple depth predictions and weights->softmax weighting-based fusion->depth estimation
arxiv.org/abs/2601.05208
Zichen Wang, Ang Cao, Liam J. Wang, Jeong Joon Park
tl;dr: multiple depth predictions and weights->softmax weighting-based fusion->depth estimation
arxiv.org/abs/2601.05208




January 9, 2026 at 8:12 PM
MoE3D: A Mixture-of-Experts Module for 3D Reconstruction
Zichen Wang, Ang Cao, Liam J. Wang, Jeong Joon Park
tl;dr: multiple depth predictions and weights->softmax weighting-based fusion->depth estimation
arxiv.org/abs/2601.05208
Zichen Wang, Ang Cao, Liam J. Wang, Jeong Joon Park
tl;dr: multiple depth predictions and weights->softmax weighting-based fusion->depth estimation
arxiv.org/abs/2601.05208
IDESplat: Iterative Depth Probability Estimation for Generalizable 3D Gaussian Splatting
Wei Long, Haifeng Wu, Shiyin Jiang, Jinhua Zhang, Xinchun Ji, Shuhang Gu
tl;dr: iterative warp->multiple epipolar attention maps->refined depth map->Gaussian means
arxiv.org/abs/2601.03824
Wei Long, Haifeng Wu, Shiyin Jiang, Jinhua Zhang, Xinchun Ji, Shuhang Gu
tl;dr: iterative warp->multiple epipolar attention maps->refined depth map->Gaussian means
arxiv.org/abs/2601.03824




January 8, 2026 at 2:23 PM
IDESplat: Iterative Depth Probability Estimation for Generalizable 3D Gaussian Splatting
Wei Long, Haifeng Wu, Shiyin Jiang, Jinhua Zhang, Xinchun Ji, Shuhang Gu
tl;dr: iterative warp->multiple epipolar attention maps->refined depth map->Gaussian means
arxiv.org/abs/2601.03824
Wei Long, Haifeng Wu, Shiyin Jiang, Jinhua Zhang, Xinchun Ji, Shuhang Gu
tl;dr: iterative warp->multiple epipolar attention maps->refined depth map->Gaussian means
arxiv.org/abs/2601.03824
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
Jiaxin Huang, Yuanbo Yang, Bangbang Yang, Lin Ma, Yuewen Ma, @yiyiliao.bsky.social
tl;dr: geometric latents from VGGT as VAE + appearance latents from video diffusion
arxiv.org/abs/2601.04090
Jiaxin Huang, Yuanbo Yang, Bangbang Yang, Lin Ma, Yuewen Ma, @yiyiliao.bsky.social
tl;dr: geometric latents from VGGT as VAE + appearance latents from video diffusion
arxiv.org/abs/2601.04090




January 8, 2026 at 2:23 PM
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
Jiaxin Huang, Yuanbo Yang, Bangbang Yang, Lin Ma, Yuewen Ma, @yiyiliao.bsky.social
tl;dr: geometric latents from VGGT as VAE + appearance latents from video diffusion
arxiv.org/abs/2601.04090
Jiaxin Huang, Yuanbo Yang, Bangbang Yang, Lin Ma, Yuewen Ma, @yiyiliao.bsky.social
tl;dr: geometric latents from VGGT as VAE + appearance latents from video diffusion
arxiv.org/abs/2601.04090
ImLoc: Revisiting Visual Localization with Image-based Representation
@xudongjiang.bsky.social, @fangjinhuawang.bsky.social, Silvano Galliani, Christoph Vogel, @marcpollefeys.bsky.social
arxiv.org/abs/2601.04185
@xudongjiang.bsky.social, @fangjinhuawang.bsky.social, Silvano Galliani, Christoph Vogel, @marcpollefeys.bsky.social
arxiv.org/abs/2601.04185




January 8, 2026 at 2:21 PM
ImLoc: Revisiting Visual Localization with Image-based Representation
@xudongjiang.bsky.social, @fangjinhuawang.bsky.social, Silvano Galliani, Christoph Vogel, @marcpollefeys.bsky.social
arxiv.org/abs/2601.04185
@xudongjiang.bsky.social, @fangjinhuawang.bsky.social, Silvano Galliani, Christoph Vogel, @marcpollefeys.bsky.social
arxiv.org/abs/2601.04185
XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
Zunhai Su, Weihao Ye, Hansen Feng, Keyu Fan, Jing Zhang, Dahai Yu, Zhengwu Liu, Ngai Wong
tl;dr: token importance->pruning->KV quantization
arxiv.org/abs/2601.01204
Zunhai Su, Weihao Ye, Hansen Feng, Keyu Fan, Jing Zhang, Dahai Yu, Zhengwu Liu, Ngai Wong
tl;dr: token importance->pruning->KV quantization
arxiv.org/abs/2601.01204




January 6, 2026 at 12:06 PM
XStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
Zunhai Su, Weihao Ye, Hansen Feng, Keyu Fan, Jing Zhang, Dahai Yu, Zhengwu Liu, Ngai Wong
tl;dr: token importance->pruning->KV quantization
arxiv.org/abs/2601.01204
Zunhai Su, Weihao Ye, Hansen Feng, Keyu Fan, Jing Zhang, Dahai Yu, Zhengwu Liu, Ngai Wong
tl;dr: token importance->pruning->KV quantization
arxiv.org/abs/2601.01204
InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
Shuai Yuan, Yantai Yang, Xiaotian Yang, Xupeng Zhang, Zhonghao Zhao, Lingming Zhang, Zhipeng Zhang
tl;dr: key cosine similarity->attention-independen proxy for token importance
arxiv.org/abs/2601.02281
Shuai Yuan, Yantai Yang, Xiaotian Yang, Xupeng Zhang, Zhonghao Zhao, Lingming Zhang, Zhipeng Zhang
tl;dr: key cosine similarity->attention-independen proxy for token importance
arxiv.org/abs/2601.02281




January 6, 2026 at 12:06 PM
InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
Shuai Yuan, Yantai Yang, Xiaotian Yang, Xupeng Zhang, Zhonghao Zhao, Lingming Zhang, Zhipeng Zhang
tl;dr: key cosine similarity->attention-independen proxy for token importance
arxiv.org/abs/2601.02281
Shuai Yuan, Yantai Yang, Xiaotian Yang, Xupeng Zhang, Zhonghao Zhao, Lingming Zhang, Zhipeng Zhang
tl;dr: key cosine similarity->attention-independen proxy for token importance
arxiv.org/abs/2601.02281
UniSH: Unifying Scene and Human Reconstruction in a Feed-Forward Pass
Mengfei Li, Peng Li, Zheng Zhang, Jiahao Lu, Chengfeng Zhao, Wei Xue, Qifeng Liu, Sida Peng, Wenxiao Zhang, Wenhan Luo, Yuan Liu, Yike Guo
arxiv.org/abs/2601.01222
Mengfei Li, Peng Li, Zheng Zhang, Jiahao Lu, Chengfeng Zhao, Wei Xue, Qifeng Liu, Sida Peng, Wenxiao Zhang, Wenhan Luo, Yuan Liu, Yike Guo
arxiv.org/abs/2601.01222




January 6, 2026 at 12:05 PM
UniSH: Unifying Scene and Human Reconstruction in a Feed-Forward Pass
Mengfei Li, Peng Li, Zheng Zhang, Jiahao Lu, Chengfeng Zhao, Wei Xue, Qifeng Liu, Sida Peng, Wenxiao Zhang, Wenhan Luo, Yuan Liu, Yike Guo
arxiv.org/abs/2601.01222
Mengfei Li, Peng Li, Zheng Zhang, Jiahao Lu, Chengfeng Zhao, Wei Xue, Qifeng Liu, Sida Peng, Wenxiao Zhang, Wenhan Luo, Yuan Liu, Yike Guo
arxiv.org/abs/2601.01222
360DVO: Deep Visual Odometry for Monocular 360-Degree Camera
Xiaopeng Guo, Yinzhe Xu, Huajian Huang, Sai-Kit Yeung
tl;dr: SphereNet+residual blocks->features from omnidirectional image->DPVO->omnidirectional BA
arxiv.org/abs/2601.02309
Xiaopeng Guo, Yinzhe Xu, Huajian Huang, Sai-Kit Yeung
tl;dr: SphereNet+residual blocks->features from omnidirectional image->DPVO->omnidirectional BA
arxiv.org/abs/2601.02309




January 6, 2026 at 12:04 PM
360DVO: Deep Visual Odometry for Monocular 360-Degree Camera
Xiaopeng Guo, Yinzhe Xu, Huajian Huang, Sai-Kit Yeung
tl;dr: SphereNet+residual blocks->features from omnidirectional image->DPVO->omnidirectional BA
arxiv.org/abs/2601.02309
Xiaopeng Guo, Yinzhe Xu, Huajian Huang, Sai-Kit Yeung
tl;dr: SphereNet+residual blocks->features from omnidirectional image->DPVO->omnidirectional BA
arxiv.org/abs/2601.02309
AdaGaR: Adaptive Gabor Representation for Dynamic Scene Reconstruction
Jiewen Chan, @ericzzj.bsky.social, Yu-Lun Liu
tl;dr: extend Gaussians to frequency domain->hybrid Gabor & Gaussian->novel video representation->adaptive high & low-frequency balance
arxiv.org/abs/2601.00796
Jiewen Chan, @ericzzj.bsky.social, Yu-Lun Liu
tl;dr: extend Gaussians to frequency domain->hybrid Gabor & Gaussian->novel video representation->adaptive high & low-frequency balance
arxiv.org/abs/2601.00796




January 5, 2026 at 11:12 AM
AdaGaR: Adaptive Gabor Representation for Dynamic Scene Reconstruction
Jiewen Chan, @ericzzj.bsky.social, Yu-Lun Liu
tl;dr: extend Gaussians to frequency domain->hybrid Gabor & Gaussian->novel video representation->adaptive high & low-frequency balance
arxiv.org/abs/2601.00796
Jiewen Chan, @ericzzj.bsky.social, Yu-Lun Liu
tl;dr: extend Gaussians to frequency domain->hybrid Gabor & Gaussian->novel video representation->adaptive high & low-frequency balance
arxiv.org/abs/2601.00796
RGS-SLAM: Robust Gaussian Splatting SLAM with One-Shot Dense Initialization
Wei-Tse Cheng, Yen-Jen Chiou, Yuan-Fu Yang
tl;dr: keyframe->DINOv3->dense matching->triangulation->one-shot initialization->Gaussian seed prior
arxiv.org/abs/2601.00705
Wei-Tse Cheng, Yen-Jen Chiou, Yuan-Fu Yang
tl;dr: keyframe->DINOv3->dense matching->triangulation->one-shot initialization->Gaussian seed prior
arxiv.org/abs/2601.00705




January 5, 2026 at 11:11 AM
RGS-SLAM: Robust Gaussian Splatting SLAM with One-Shot Dense Initialization
Wei-Tse Cheng, Yen-Jen Chiou, Yuan-Fu Yang
tl;dr: keyframe->DINOv3->dense matching->triangulation->one-shot initialization->Gaussian seed prior
arxiv.org/abs/2601.00705
Wei-Tse Cheng, Yen-Jen Chiou, Yuan-Fu Yang
tl;dr: keyframe->DINOv3->dense matching->triangulation->one-shot initialization->Gaussian seed prior
arxiv.org/abs/2601.00705
DefVINS: Visual-Inertial Odometry for Deformable Scenes
Samuel Cerezo, @jcivera.bsky.social
tl;dr: embedded deformation graph->non–rigid warp; decouple rigid & non-rigid; observability analysis->visual–inertial deformable odometry
arxiv.org/abs/2601.00702
Samuel Cerezo, @jcivera.bsky.social
tl;dr: embedded deformation graph->non–rigid warp; decouple rigid & non-rigid; observability analysis->visual–inertial deformable odometry
arxiv.org/abs/2601.00702




January 5, 2026 at 11:10 AM
DefVINS: Visual-Inertial Odometry for Deformable Scenes
Samuel Cerezo, @jcivera.bsky.social
tl;dr: embedded deformation graph->non–rigid warp; decouple rigid & non-rigid; observability analysis->visual–inertial deformable odometry
arxiv.org/abs/2601.00702
Samuel Cerezo, @jcivera.bsky.social
tl;dr: embedded deformation graph->non–rigid warp; decouple rigid & non-rigid; observability analysis->visual–inertial deformable odometry
arxiv.org/abs/2601.00702
FoundationSLAM: Unleashing the Power of Depth Foundation Models for End-to-End Dense Visual SLAM
Yuchen Wu, Jiahe Li, Fabio Tosi, Matteo Poggi, Jin Zheng, Xiao Bai
tl;dr: foundation depth models->flow matching
arxiv.org/abs/2512.25008
Yuchen Wu, Jiahe Li, Fabio Tosi, Matteo Poggi, Jin Zheng, Xiao Bai
tl;dr: foundation depth models->flow matching
arxiv.org/abs/2512.25008




January 1, 2026 at 3:47 PM
FoundationSLAM: Unleashing the Power of Depth Foundation Models for End-to-End Dense Visual SLAM
Yuchen Wu, Jiahe Li, Fabio Tosi, Matteo Poggi, Jin Zheng, Xiao Bai
tl;dr: foundation depth models->flow matching
arxiv.org/abs/2512.25008
Yuchen Wu, Jiahe Li, Fabio Tosi, Matteo Poggi, Jin Zheng, Xiao Bai
tl;dr: foundation depth models->flow matching
arxiv.org/abs/2512.25008
GaMO: Geometry-aware Multi-view Diffusion Outpainting for Sparse-View 3D Reconstruction
Yi-Chuan Huang, Hao-Jen Chien, Chin-Yang Lin, Ying-Huan Chen, Yu-Lun Liu
tl;dr: multi-view outpainting->sparse-view reconstruction
arxiv.org/abs/2512.25073
Yi-Chuan Huang, Hao-Jen Chien, Chin-Yang Lin, Ying-Huan Chen, Yu-Lun Liu
tl;dr: multi-view outpainting->sparse-view reconstruction
arxiv.org/abs/2512.25073




January 1, 2026 at 3:47 PM
GaMO: Geometry-aware Multi-view Diffusion Outpainting for Sparse-View 3D Reconstruction
Yi-Chuan Huang, Hao-Jen Chien, Chin-Yang Lin, Ying-Huan Chen, Yu-Lun Liu
tl;dr: multi-view outpainting->sparse-view reconstruction
arxiv.org/abs/2512.25073
Yi-Chuan Huang, Hao-Jen Chien, Chin-Yang Lin, Ying-Huan Chen, Yu-Lun Liu
tl;dr: multi-view outpainting->sparse-view reconstruction
arxiv.org/abs/2512.25073
KV-Tracker: Real-Time Pose Tracking with Transformers
@marwantaher.bsky.social, Ignacio Alzugaray, @makezur.bsky.social, Xin Kong, @ajdavison.bsky.social
tl;dr: KV-cache is underlying implicit scene representation
arxiv.org/abs/2512.22581
@marwantaher.bsky.social, Ignacio Alzugaray, @makezur.bsky.social, Xin Kong, @ajdavison.bsky.social
tl;dr: KV-cache is underlying implicit scene representation
arxiv.org/abs/2512.22581




December 30, 2025 at 3:30 PM
KV-Tracker: Real-Time Pose Tracking with Transformers
@marwantaher.bsky.social, Ignacio Alzugaray, @makezur.bsky.social, Xin Kong, @ajdavison.bsky.social
tl;dr: KV-cache is underlying implicit scene representation
arxiv.org/abs/2512.22581
@marwantaher.bsky.social, Ignacio Alzugaray, @makezur.bsky.social, Xin Kong, @ajdavison.bsky.social
tl;dr: KV-cache is underlying implicit scene representation
arxiv.org/abs/2512.22581
A Minimal Solver for Relative Pose Estimation with Unknown Focal Length from Two Affine Correspondences
Zhenbao Yu, Shirong Ye, Ronghe Jin, Shunkun Liang, Zibin Liu, Huiyun Zhang, Banglei Guan
tl;dr: 2 AC+vertical direction->relative pose+focal length
arxiv.org/abs/2512.22833
Zhenbao Yu, Shirong Ye, Ronghe Jin, Shunkun Liang, Zibin Liu, Huiyun Zhang, Banglei Guan
tl;dr: 2 AC+vertical direction->relative pose+focal length
arxiv.org/abs/2512.22833




December 30, 2025 at 3:28 PM
A Minimal Solver for Relative Pose Estimation with Unknown Focal Length from Two Affine Correspondences
Zhenbao Yu, Shirong Ye, Ronghe Jin, Shunkun Liang, Zibin Liu, Huiyun Zhang, Banglei Guan
tl;dr: 2 AC+vertical direction->relative pose+focal length
arxiv.org/abs/2512.22833
Zhenbao Yu, Shirong Ye, Ronghe Jin, Shunkun Liang, Zibin Liu, Huiyun Zhang, Banglei Guan
tl;dr: 2 AC+vertical direction->relative pose+focal length
arxiv.org/abs/2512.22833
Embodied Robot Manipulation in the Era of Foundation Models: Planning and Learning Perspectives
tl;dr: survey in title
arxiv.org/abs/2512.22983
tl;dr: survey in title
arxiv.org/abs/2512.22983



December 30, 2025 at 3:28 PM
Embodied Robot Manipulation in the Era of Foundation Models: Planning and Learning Perspectives
tl;dr: survey in title
arxiv.org/abs/2512.22983
tl;dr: survey in title
arxiv.org/abs/2512.22983
Analyzing the Mechanism of Attention Collapse in VGGT from a Dynamics Perspective
Huan Li, Longjun Luo, Yuling Shi, Xiaodong Gu
tl;dr: in title
arxiv.org/abs/2512.21691
Huan Li, Longjun Luo, Yuling Shi, Xiaodong Gu
tl;dr: in title
arxiv.org/abs/2512.21691




December 29, 2025 at 1:16 PM
Analyzing the Mechanism of Attention Collapse in VGGT from a Dynamics Perspective
Huan Li, Longjun Luo, Yuling Shi, Xiaodong Gu
tl;dr: in title
arxiv.org/abs/2512.21691
Huan Li, Longjun Luo, Yuling Shi, Xiaodong Gu
tl;dr: in title
arxiv.org/abs/2512.21691
Reloc-VGGT: Visual Re-localization with Geometry Grounded Transformer
Tianchen Deng, Wenhua Wu, Kunzhen Wu, Guangming Wang, Siting Zhu, Shenghai Yuan, Xun Chen, Guole Shen, Zhe Liu, Hesheng Wang
tl;dr: multi-frame relocalization using VGGT
arxiv.org/abs/2512.21883
Tianchen Deng, Wenhua Wu, Kunzhen Wu, Guangming Wang, Siting Zhu, Shenghai Yuan, Xun Chen, Guole Shen, Zhe Liu, Hesheng Wang
tl;dr: multi-frame relocalization using VGGT
arxiv.org/abs/2512.21883




December 29, 2025 at 1:15 PM
Reloc-VGGT: Visual Re-localization with Geometry Grounded Transformer
Tianchen Deng, Wenhua Wu, Kunzhen Wu, Guangming Wang, Siting Zhu, Shenghai Yuan, Xun Chen, Guole Shen, Zhe Liu, Hesheng Wang
tl;dr: multi-frame relocalization using VGGT
arxiv.org/abs/2512.21883
Tianchen Deng, Wenhua Wu, Kunzhen Wu, Guangming Wang, Siting Zhu, Shenghai Yuan, Xun Chen, Guole Shen, Zhe Liu, Hesheng Wang
tl;dr: multi-frame relocalization using VGGT
arxiv.org/abs/2512.21883