




Gina-Julia Westenberger
@gjwestenberger.bsky.social
Research on spatial inequality, social cleavages & political behavior I
Phd Candidate @University of Lausanne and @Centre_LIVES
Phd Candidate @University of Lausanne and @Centre_LIVES
Pinned
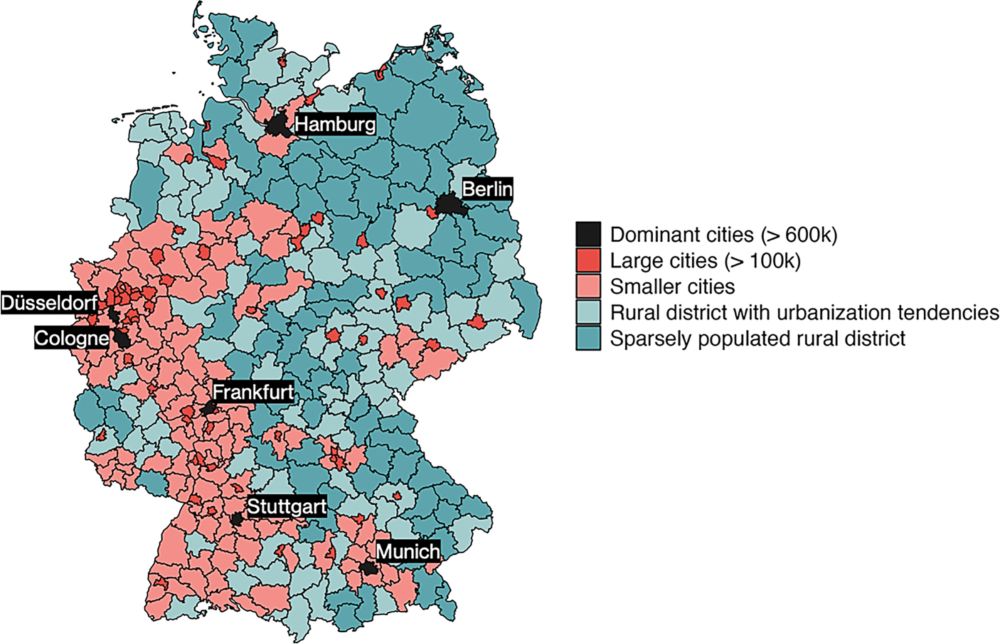
Beyond Thriving Cities and Declining Rural Areas: Mapping Geographic Divides in Germany’s Employment Structure, 1993–2019 - KZfSS Kölner Zeitschrift für Soziologie und Sozialpsychologie
This article assesses the popular thesis of growing regional inequality and urban–rural divides for Germany, focusing on the quality of employment opportunities. Drawing on a 2% sample of individuals ...
doi.org
How does employment change differ across German regions & is it all about the urban-rural divide? 🏙️ 🏡
Happy to see the first paper of my PhD now out in Kölner Zeitschrift für Soziologie and Sozialpsychologie!
Read the paper #OpenAccess here doi.org/10.1007/s115... and 🧵👇:
Happy to see the first paper of my PhD now out in Kölner Zeitschrift für Soziologie and Sozialpsychologie!
Read the paper #OpenAccess here doi.org/10.1007/s115... and 🧵👇:
Reposted by Gina-Julia Westenberger

A little food for thought (and an army of straw men) #AcademicChatter

Quantitative political science shouldn’t favour tools over theory - Impact of Social Sciences
estimated reading time: 6 min Publication in highly ranked political science journals has increasingly become defined by the use of complex quantitative methods. Silje Synnøve Lyder Hermansen argues the fetishization of quantitative tools has obscured the wider context and meaning of research in the field. Political science isn’t short on new methods. But too often, our publishing culture is a slot machine: pull the lever enough times and someone will hit the jackpot. That’s how we end up mistaking noise for knowledge. We live in an age of data abundance: easy access, cheap software, and a generation skilled enough to “let the data speak”. Out of this, two academic fads emerge. The p-hacking boom. Ten researchers sample from the same population and test whether X is correlated with Y. The rule: publish if p < 0.1, quit if not. Inevitably, someone gets “lucky”. A tidy theory is retrofitted, a few anecdotes sprinkled in, maybe even a citation. To look more comprehensive, we frame it as settling a debate between theories A and B. Let’s be honest: political science has argued in all directions before. Both theories are compelling and internally coherent. Voilà: new “truth” established. The “correction” race. The community has learned. Data access, software, and training have all expanded. Now twice as many researchers sample from the same population. The rule: publish only if the result is significant in the opposite direction. Replications are boring, non-significant results inconclusive. Surprise is the only currency. Inevitably—with the same probability as before—someone gets “lucky.” Voilà: new, opposite “truth” established. But the underlying reality never changed: the true correlation is zero. We’ve built orthodoxy on statistical fluke. So what have we learned? Less than nothing. We’re wrong, and we’ve grown confident about being wrong. Worse yet, we’ve done it eyes wide shut; armed with the very statistical training that tells us the game is rigged. That’s the danger of one-correlation papers in a publishing culture that fetishizes originality. Now, let me be clear: I’m not sneering from the sidelines. I’m a compulsive scraper; I get my kicks from the three-star slot machine of regression analysis. I love reading new research, and I want to publish too. How do we fix this? We can always demand stricter p-values before we’re impressed. But the core problem doesn’t go away. At best, we reset the slot machine odds to where they used to be: bigger data, stricter cutoffs – same game. As our scraped datasets balloon, the machine continues to spit jackpots. Can causal inference fix the problem? In some ways, yes: it pins down where an effect occurs, and it feels rigorous. But theory is too often left by the wayside, reduced to claims about ‘real-life data’ and the absence of obvious confounders – precisely where alternative theories tend to live. The toolkit is fantastic for public policy questions. What was the effect of our latest reform? Data is available, and the question is bounded. But external validity becomes the stumbling block. Can we reproduce those conditions in the future? Can we resolve bigger societal problems with another reform? Without theory that specifies fairly general scope conditions, the answers don’t travel. But what are we actually measuring? If all we do is describe ourselves, how does that teach us why we behave as we do? We could go all in on the experimental ideal: pre-registration, conjoint survey experiments, lab-in-field. These methods double down on falsifiability. Pre-registration forces us to commit before pulling the lever. They require careful planning and let us test competing theories head-to-head. There’s a real boldness in this turn: no more hand-waving; the question is framed, the die is cast. But bold is still bounded. Conjoints show how people trade off attributes in a survey, but the selection effect looms large. How much do we rely on convenience samples – MTurk, YouGov, undergrads? And even if we limit our claims to that group, we may still construct trade-offs our respondents would never perceive in the real world. Then there’s the newest darling: text analysis and prediction. Data science masquerades as political method. We scrape massive corpora of speeches, manifestos, TikTok feeds, or laws, run them through embeddings, topic models, or large language models (LLMs). They’re magical at approximating meaning. They mirror us back to ourselves – endlessly. But what are we actually measuring? If all we do is describe ourselves, how does that teach us why we behave as we do? Then we move on to prediction. If we can forecast 80% of coups or measure “policy distance” to six decimals, who wouldn’t be impressed? Out-of-sample accuracy shows a model describes our data, but rarely why. Prediction is not explanation, unless the model maps onto a data-generating process we can actually theorise. I don’t snark at these advances. I admire them! I’m often baffled at how cleverly confounders can be designed away. I’m in absolute awe at the ballsiness of preregistration and prediction. My stupor is endless when text models make intuitive sense. I might be a jaded millennial, but I recognise progress. But these are tools – powerful tools – not methods. And certainly not theory. There is no such thing as a perfect paper, but we can make them better. One way is to measure the same thing in different ways. That boosts construct validity and rules out obvious p-hacking, but still doesn’t test theory itself. For that, we need imagination: to nerd out on the data-generating process. If what we claim is true, what else would we observe? What other empirical implications follow from our theoretical models? It’s an old trick, but it still works with the flashiest of tools. In my opening parable, a false finding struck once in ten attempts. If the true correlation is zero, one out of ten researchers still gets a significant result by chance. If we demand two distinct tests of the same theory, then the odds of a false positive drop to one in a hundred. Every extra implication strengthens the test exponentially. The tools we employ and the research designs we devise have multiplied. We truly live in exciting times. But they don’t replace our human brains. And here’s the bigger point. We’re often asked to justify our “lush” life on taxpayers’ dime by proving “societal impact”. Somehow this has come to mean media outreach. Fine. But we’re not the engineers. We’re knowledge providers for decision makers: the people (taxable or not) and their representatives. What we need is a research agenda that carefully dissects – paper by paper – how democracy fails, what behaviors our institutions induce, how opinions are formed, and how they translate into policies. This begins with research and ends with teaching. Political science isn’t in the business of theorising about Life, the Universe, and Everything. Our task is no less urgent: to study power – how it’s won, wielded, constrained, and lost. Too often we debate whether 42 was correctly estimated, rather than carefully specifying the question up front. That’s the jackpot worth chasing. 📨Enjoying this blogpost? Sign up to our mailing list and receive all the latest LSE Impact Blog news direct to your inbox 📨 The content generated on this blog is for information purposes only. This Article gives the views and opinions of the authors and does not reflect the views and opinions of the Impact of Social Science blog (the blog), nor of the London School of Economics and Political Science. Please review our comments policy if you have any concerns on posting a comment below. Image Credit: mihalec on Shutterstock.
blogs.lse.ac.uk
November 18, 2025 at 9:10 PM
A little food for thought (and an army of straw men) #AcademicChatter
Very happy to spend this term at @nuffieldcollege.bsky.social! Thanks to UK weather, cosy library vibes are already 10/10 📚🍂. If you're around Oxford and would like to chat about labour markets, regional divides, or voting, let me know ☕!

October 17, 2025 at 11:09 AM
Very happy to spend this term at @nuffieldcollege.bsky.social! Thanks to UK weather, cosy library vibes are already 10/10 📚🍂. If you're around Oxford and would like to chat about labour markets, regional divides, or voting, let me know ☕!
So grateful for meeting all these great women in political economy! Also big shout-out to the organizers @palmapolyak.bsky.social & @dustinvoss.bsky.social and everyone who made this inspiring week happen 🫶

Thank you to all who joined us in Cologne this week for the 2nd Max Planck Summer School for Women in Political Economy! A fantastic line-up of speakers and participants, thoughtful discussions and global perspectives. Huge thanks to organizers @palmapolyak.bsky.social and @dustinvoss.bsky.social!




September 26, 2025 at 2:09 PM
So grateful for meeting all these great women in political economy! Also big shout-out to the organizers @palmapolyak.bsky.social & @dustinvoss.bsky.social and everyone who made this inspiring week happen 🫶
Happy to be in lovely Madrid for #EPSA2025 🇪🇸 If you‘re interested in how long-term occupational upgrading maps onto voting across German districts, grab a sandwich & come to our panel on the „Geographies of discontent“, tomorrow 13:10-14:50!
June 26, 2025 at 2:38 PM
Happy to be in lovely Madrid for #EPSA2025 🇪🇸 If you‘re interested in how long-term occupational upgrading maps onto voting across German districts, grab a sandwich & come to our panel on the „Geographies of discontent“, tomorrow 13:10-14:50!
Reposted by Gina-Julia Westenberger

Joint work with Daniel Oesch @unil.bsky.social now beautifully formatted in first open access issue of @europeansocieties.bsky.social
We ask: have European regions followed similar or divergent trajectories in terms of occupational change over time?
We ask: have European regions followed similar or divergent trajectories in terms of occupational change over time?

Uneven shifts: the geography of occupational change in France, Italy, Spain and the United Kingdom, 1992–2018
ABSTRACT. Amid renewed interest in geographical inequalities in life chances and an ongoing debate about occupational upgrading versus polarisation, we investigate how the occupational structure chang...
direct.mit.edu
May 13, 2025 at 8:44 AM
Joint work with Daniel Oesch @unil.bsky.social now beautifully formatted in first open access issue of @europeansocieties.bsky.social
We ask: have European regions followed similar or divergent trajectories in terms of occupational change over time?
We ask: have European regions followed similar or divergent trajectories in terms of occupational change over time?
How does employment change differ across German regions & is it all about the urban-rural divide? 🏙️ 🏡
Happy to see the first paper of my PhD now out in Kölner Zeitschrift für Soziologie and Sozialpsychologie!
Read the paper #OpenAccess here doi.org/10.1007/s115... and 🧵👇:
Happy to see the first paper of my PhD now out in Kölner Zeitschrift für Soziologie and Sozialpsychologie!
Read the paper #OpenAccess here doi.org/10.1007/s115... and 🧵👇:
Beyond Thriving Cities and Declining Rural Areas: Mapping Geographic Divides in Germany’s Employment Structure, 1993–2019 - KZfSS Kölner Zeitschrift für Soziologie und Sozialpsychologie
This article assesses the popular thesis of growing regional inequality and urban–rural divides for Germany, focusing on the quality of employment opportunities. Drawing on a 2% sample of individuals ...
doi.org
March 31, 2025 at 1:18 PM
How does employment change differ across German regions & is it all about the urban-rural divide? 🏙️ 🏡
Happy to see the first paper of my PhD now out in Kölner Zeitschrift für Soziologie and Sozialpsychologie!
Read the paper #OpenAccess here doi.org/10.1007/s115... and 🧵👇:
Happy to see the first paper of my PhD now out in Kölner Zeitschrift für Soziologie and Sozialpsychologie!
Read the paper #OpenAccess here doi.org/10.1007/s115... and 🧵👇:
Reposted by Gina-Julia Westenberger

Für Zeit Online analysieren @juliustroeger.bsky.social, @benjazehr.ch, Michael Schlieben und ich die Wahlkreisergebnisse aller Bundestagswahlen seit 1949. Besonders spannend finde ich insbesondere das interaktive Tool & Karte zu den historischen Hochburgen der Parteien.
www.zeit.de/politik/deut...
www.zeit.de/politik/deut...

Historische Bundestagswahlergebnisse: So hat Ihr Wahlkreis seit 1949 gewählt
Wo hat die CDU noch nie verloren? Welche Region wählt immer wie Deutschland? Unsere interaktiven Karten zeigen erstmals alle Ergebnisse seit 1949 in heutigen Wahlkreisen.
www.zeit.de
February 12, 2025 at 11:29 AM
Für Zeit Online analysieren @juliustroeger.bsky.social, @benjazehr.ch, Michael Schlieben und ich die Wahlkreisergebnisse aller Bundestagswahlen seit 1949. Besonders spannend finde ich insbesondere das interaktive Tool & Karte zu den historischen Hochburgen der Parteien.
www.zeit.de/politik/deut...
www.zeit.de/politik/deut...