




Ivana Balazevic
@ibalazevic.bsky.social
Senior Research Scientist at Google DeepMind, working on Gemini.
PhD from University of Edinburgh.
ibalazevic.github.io
PhD from University of Edinburgh.
ibalazevic.github.io
Disentanglement is an intriguing phenomenon that arises in generative latent variable models for reasons that are not fully understood.
If you’re interested in learning why, I highly recommend giving Carl’s blog a read!
If you’re interested in learning why, I highly recommend giving Carl’s blog a read!
Machine learning has made incredible breakthroughs, but our theoretical understanding lags behind.
We take a step towards unravelling its mystery by explaining why the phenomenon of disentanglement arises in generative latent variable models.
Blog post: carl-allen.github.io/theory/2024/...
We take a step towards unravelling its mystery by explaining why the phenomenon of disentanglement arises in generative latent variable models.
Blog post: carl-allen.github.io/theory/2024/...

December 18, 2024 at 5:08 PM
Disentanglement is an intriguing phenomenon that arises in generative latent variable models for reasons that are not fully understood.
If you’re interested in learning why, I highly recommend giving Carl’s blog a read!
If you’re interested in learning why, I highly recommend giving Carl’s blog a read!
Reposted by Ivana Balazevic

I am hiring for RS/RE positions! If you are interested in language-flavored multimodal learning, evaluation, or post-training apply here 🦎 boards.greenhouse.io/deepmind/job...
I will also be #NeurIPS2024 so come say hi! (Please email me to find time to chat)
I will also be #NeurIPS2024 so come say hi! (Please email me to find time to chat)

Research Scientist, Language
London, UK
boards.greenhouse.io
December 6, 2024 at 11:07 PM
I am hiring for RS/RE positions! If you are interested in language-flavored multimodal learning, evaluation, or post-training apply here 🦎 boards.greenhouse.io/deepmind/job...
I will also be #NeurIPS2024 so come say hi! (Please email me to find time to chat)
I will also be #NeurIPS2024 so come say hi! (Please email me to find time to chat)
Reposted by Ivana Balazevic

Our big_vision codebase is really good! And it's *the* reference for ViT, SigLIP, PaliGemma, JetFormer, ... including fine-tuning them.
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html

December 3, 2024 at 12:18 AM
Our big_vision codebase is really good! And it's *the* reference for ViT, SigLIP, PaliGemma, JetFormer, ... including fine-tuning them.
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html
However, it's criminally undocumented. I tried using it outside Google to fine-tune PaliGemma and SigLIP on GPUs, and wrote a tutorial: lb.eyer.be/a/bv_tuto.html
Reposted by Ivana Balazevic

I think this comes down to the model behind p(x,y). If features of x cause y, e.g. aspects of a website (x) -> clicks (y); age/health -> disease, then p(y|x) is a (regression) fn of x. But if x|y is a distrib'n of different y's (e.g. cats) then p(y|x) is given by Bayes rule (squint at softmax).
December 2, 2024 at 8:20 AM
I think this comes down to the model behind p(x,y). If features of x cause y, e.g. aspects of a website (x) -> clicks (y); age/health -> disease, then p(y|x) is a (regression) fn of x. But if x|y is a distrib'n of different y's (e.g. cats) then p(y|x) is given by Bayes rule (squint at softmax).
Reposted by Ivana Balazevic

Read our paper:
Context-Aware Multimodal Pretraining
Now on ArXiv
Can you turn vision-language models into strong any-shot models?
Go beyond zero-shot performance in SigLixP (x for context)
Read @confusezius.bsky.social thread below…
And follow Karsten … a rising star!
Context-Aware Multimodal Pretraining
Now on ArXiv
Can you turn vision-language models into strong any-shot models?
Go beyond zero-shot performance in SigLixP (x for context)
Read @confusezius.bsky.social thread below…
And follow Karsten … a rising star!

🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 5:03 PM
Read our paper:
Context-Aware Multimodal Pretraining
Now on ArXiv
Can you turn vision-language models into strong any-shot models?
Go beyond zero-shot performance in SigLixP (x for context)
Read @confusezius.bsky.social thread below…
And follow Karsten … a rising star!
Context-Aware Multimodal Pretraining
Now on ArXiv
Can you turn vision-language models into strong any-shot models?
Go beyond zero-shot performance in SigLixP (x for context)
Read @confusezius.bsky.social thread below…
And follow Karsten … a rising star!
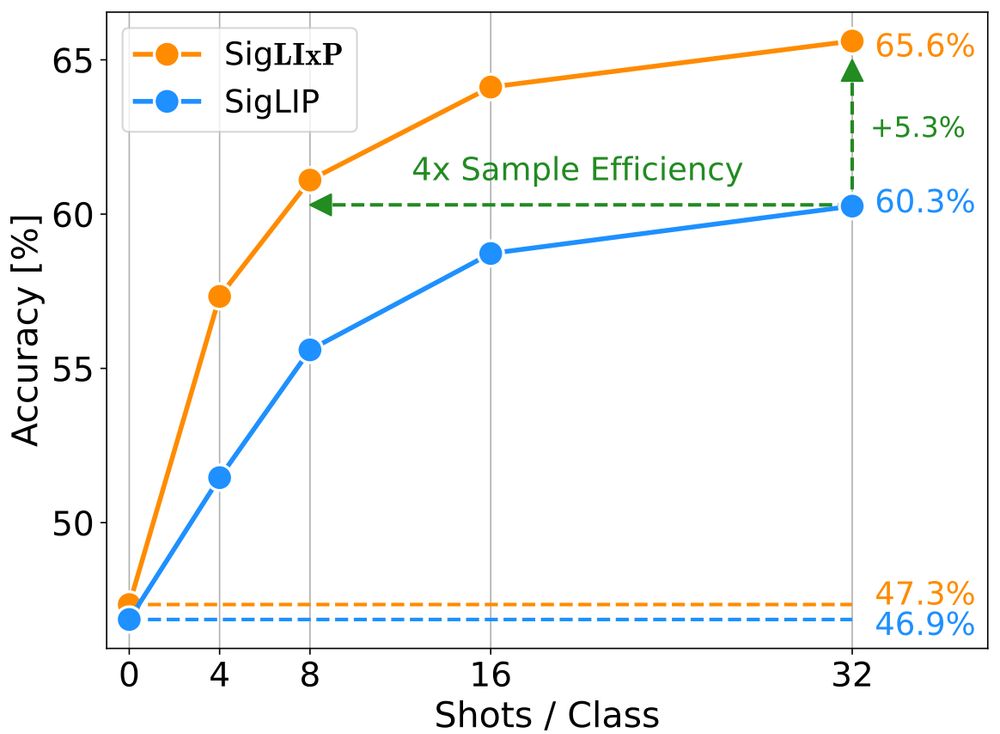
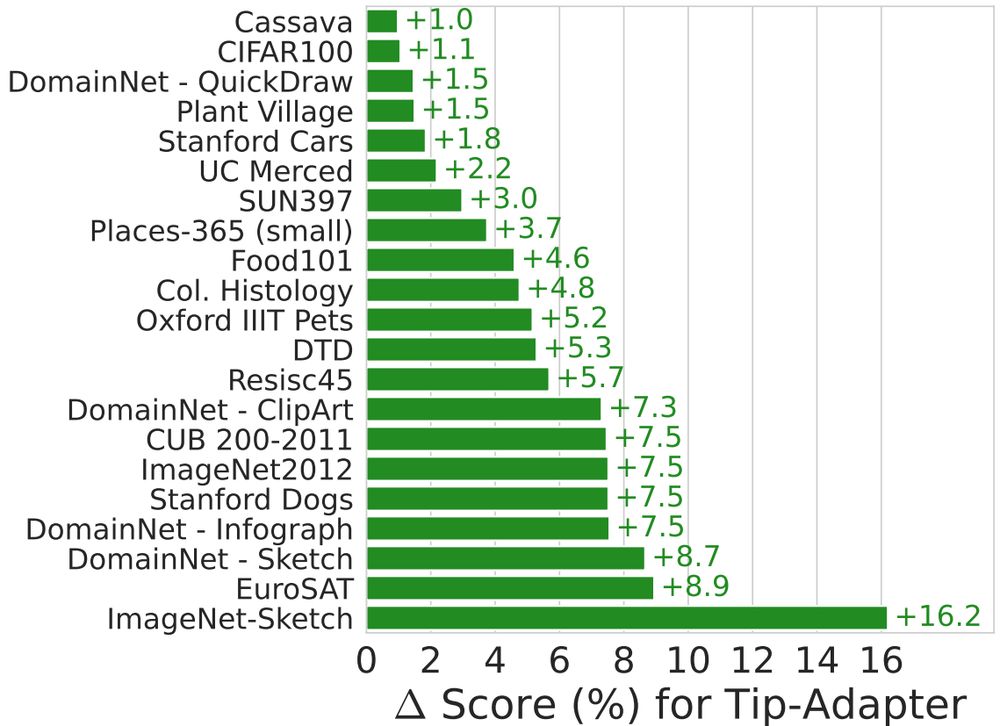
We maintain strong zero-shot transfer of CLIP / SigLIP across model size and data scale, while achieving up to 4x few-shot sample efficiency and up to +16% performance gains!
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
November 28, 2024 at 2:43 PM
We maintain strong zero-shot transfer of CLIP / SigLIP across model size and data scale, while achieving up to 4x few-shot sample efficiency and up to +16% performance gains!
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.
Reposted by Ivana Balazevic

Just a heads up to everyone: @deep-mind.bsky.social is unfortunately a fake account and has been reported. Please do not follow it nor repost anything from it.
November 25, 2024 at 11:24 PM
Just a heads up to everyone: @deep-mind.bsky.social is unfortunately a fake account and has been reported. Please do not follow it nor repost anything from it.
Could you add me please? :)
November 24, 2024 at 8:33 PM
Could you add me please? :)
Me too please :)
November 22, 2024 at 12:30 AM
Me too please :)