




Kimon Fountoulakis
@kfountou.bsky.social
Associate Professor at CS UWaterloo
Machine Learning
Lab: opallab.ca
Machine Learning
Lab: opallab.ca
On the Statistical Query Complexity of Learning Semiautomata: a Random Walk Approach
Link to the paper: arxiv.org/abs/2510.04115
Link to the paper: arxiv.org/abs/2510.04115

October 18, 2025 at 9:38 PM
On the Statistical Query Complexity of Learning Semiautomata: a Random Walk Approach
Link to the paper: arxiv.org/abs/2510.04115
Link to the paper: arxiv.org/abs/2510.04115

May 27, 2025 at 6:36 PM
New paper: Learning to Add, Multiply, and Execute Algorithmic Instructions Exactly with Neural Networks

May 26, 2025 at 3:21 AM
New paper: Learning to Add, Multiply, and Execute Algorithmic Instructions Exactly with Neural Networks
Update, 14 empirical papers added!
Computational Capability and Efficiency of Neural Networks: A Repository of Papers
I compiled a list of theoretical papers related to the computational capabilities of Transformers, recurrent networks, feedforward networks, and graph neural networks.
Link: github.com/opallab/neur...
I compiled a list of theoretical papers related to the computational capabilities of Transformers, recurrent networks, feedforward networks, and graph neural networks.
Link: github.com/opallab/neur...

May 16, 2025 at 5:26 PM
Update, 14 empirical papers added!
The SIAM Conference on Optimization 2026 will be in Edinburgh! I don’t really work on optimization anymore (at least not directly), but it’s cool to see a major optimization conference taking place where I did my PhD.

May 15, 2025 at 1:32 PM
The SIAM Conference on Optimization 2026 will be in Edinburgh! I don’t really work on optimization anymore (at least not directly), but it’s cool to see a major optimization conference taking place where I did my PhD.
Currently NeurIPS has 21390 submissions. The final number last year was 15671.
Observation made by my student George Giapitzakis.
Observation made by my student George Giapitzakis.
May 11, 2025 at 2:31 PM
Currently NeurIPS has 21390 submissions. The final number last year was 15671.
Observation made by my student George Giapitzakis.
Observation made by my student George Giapitzakis.


May 7, 2025 at 3:23 AM
Reposted by Kimon Fountoulakis

Our new work on scaling laws that includes compute, model size, and number of samples. The analysis involves an extremely fine-grained analysis of online sgd built up over the last 8 years of understanding sgd on simple toy models (tensors, single index models, multi index model)

Excited to announce a new paper with Yunwei Ren, Denny Wu,
@jasondeanlee.bsky.social!
We prove a neural scaling law in the SGD learning of extensive width two-layer neural networks.
arxiv.org/abs/2504.19983
🧵below (1/10)
@jasondeanlee.bsky.social!
We prove a neural scaling law in the SGD learning of extensive width two-layer neural networks.
arxiv.org/abs/2504.19983
🧵below (1/10)

May 5, 2025 at 5:08 PM
Our new work on scaling laws that includes compute, model size, and number of samples. The analysis involves an extremely fine-grained analysis of online sgd built up over the last 8 years of understanding sgd on simple toy models (tensors, single index models, multi index model)
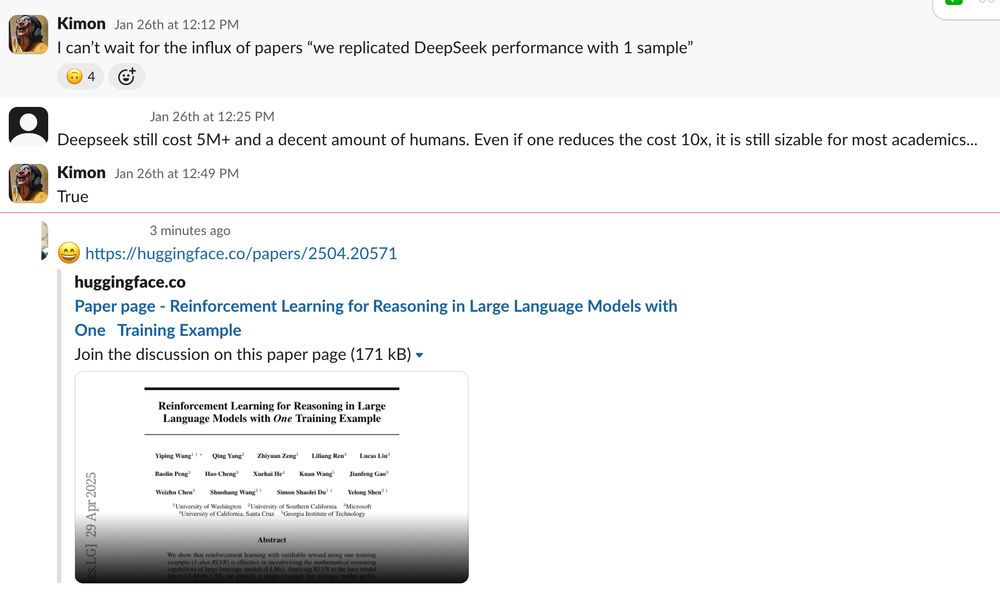
Hey, I definitely predicted this correctly.
May 1, 2025 at 8:42 PM
Hey, I definitely predicted this correctly.
ChatGPT gives me the ability to expand my search capabilities on topics that I can only roughly describe, or even illustrate with a figure, when I don’t know the exact keywords to use in a Google search.
May 1, 2025 at 5:58 PM
ChatGPT gives me the ability to expand my search capabilities on topics that I can only roughly describe, or even illustrate with a figure, when I don’t know the exact keywords to use in a Google search.
Positional Attention is accepted at ICML 2025! Thanks to all co-authors for the hard work (64 pages). If you’d like to read the paper, check the quoted post.
May 1, 2025 at 1:22 PM
Positional Attention is accepted at ICML 2025! Thanks to all co-authors for the hard work (64 pages). If you’d like to read the paper, check the quoted post.
NeurIPS 2026 in the Cyclades. Just saying.
April 29, 2025 at 6:12 PM
NeurIPS 2026 in the Cyclades. Just saying.
I enjoyed reading the paper "A Generalized Neural Tangent Kernel for Surrogate Gradient Learning" (Spotlight, NeurIPS 2024).
They extend the NTK framework to activation functions that have finitely many jumps.
They extend the NTK framework to activation functions that have finitely many jumps.


April 27, 2025 at 12:03 AM
I enjoyed reading the paper "A Generalized Neural Tangent Kernel for Surrogate Gradient Learning" (Spotlight, NeurIPS 2024).
They extend the NTK framework to activation functions that have finitely many jumps.
They extend the NTK framework to activation functions that have finitely many jumps.
Reposted by Kimon Fountoulakis

✍️ Code Shaping, an AI-powered software, allows users to edit their code through sketches like diagrams and graphs 📈
🏆 This game-changing platform won the Best Paper Award at #CHI2025.
🔗Read more: uwaterloo.ca/computer-sci...
#UWaterloo #AI
🏆 This game-changing platform won the Best Paper Award at #CHI2025.
🔗Read more: uwaterloo.ca/computer-sci...
#UWaterloo #AI
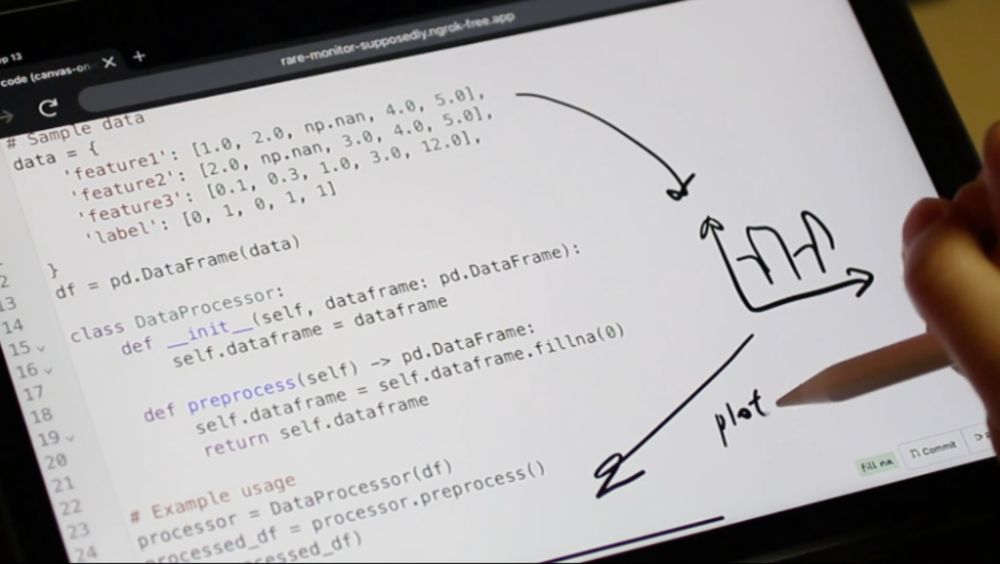
New AI model turns sketches into code | Cheriton School of Computer Science | University of Waterloo
Co-developed by alum Ryan Yen, Code Shaping can transform coding beyond the keyboard.
uwaterloo.ca
April 24, 2025 at 4:03 PM
✍️ Code Shaping, an AI-powered software, allows users to edit their code through sketches like diagrams and graphs 📈
🏆 This game-changing platform won the Best Paper Award at #CHI2025.
🔗Read more: uwaterloo.ca/computer-sci...
#UWaterloo #AI
🏆 This game-changing platform won the Best Paper Award at #CHI2025.
🔗Read more: uwaterloo.ca/computer-sci...
#UWaterloo #AI
Reposted by Kimon Fountoulakis

With my first Bluesky post, I am very pleased to share that my last PhD paper "Deterministic complexity analysis of Hermitian eigenproblems" has been accepted in ICALP 2025. A preprint is available on Arxiv:
arxiv.org/abs/2410.21550
A bit more info on linkedin: www.linkedin.com/posts/aleksa...
arxiv.org/abs/2410.21550
A bit more info on linkedin: www.linkedin.com/posts/aleksa...

Deterministic complexity analysis of Hermitian eigenproblems
In this work we revisit the arithmetic and bit complexity of Hermitian eigenproblems. We first provide an analysis for the divide-and-conquer tridiagonal eigensolver of Gu and Eisenstat [GE95] in the ...
arxiv.org
April 14, 2025 at 5:25 PM
With my first Bluesky post, I am very pleased to share that my last PhD paper "Deterministic complexity analysis of Hermitian eigenproblems" has been accepted in ICALP 2025. A preprint is available on Arxiv:
arxiv.org/abs/2410.21550
A bit more info on linkedin: www.linkedin.com/posts/aleksa...
arxiv.org/abs/2410.21550
A bit more info on linkedin: www.linkedin.com/posts/aleksa...
Update
"Memory Augmented Large Language Models are Computationally Universal", Dale Schuurmans
link: arxiv.org/abs/2301.04589
"Memory Augmented Large Language Models are Computationally Universal", Dale Schuurmans
link: arxiv.org/abs/2301.04589
April 13, 2025 at 3:05 PM
Update
"Memory Augmented Large Language Models are Computationally Universal", Dale Schuurmans
link: arxiv.org/abs/2301.04589
"Memory Augmented Large Language Models are Computationally Universal", Dale Schuurmans
link: arxiv.org/abs/2301.04589
Reposted by Kimon Fountoulakis

Excited to be part of Greeksin.ai

Confirmed keynote speakers for the Greeks 🇬🇷 in #AI 2025 Symposium in Athens, Greece 🤗
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
@alexdimakis.bsky.social @manoliskellis.bsky.social
www.greeksin.ai
April 13, 2025 at 7:30 AM
Excited to be part of Greeksin.ai
Shenghao's Ph.D Thesis "Perspectives of Graph Diffusion: Computation, Local Partitioning, Statistical Recovery, and Applications" is now available.
Link: dspacemainprd01.lib.uwaterloo.ca/server/api/c...
Relevant papers:
1) Local Graph Clustering with Noisy Labels (ICLR 2024)
Link: dspacemainprd01.lib.uwaterloo.ca/server/api/c...
Relevant papers:
1) Local Graph Clustering with Noisy Labels (ICLR 2024)

April 12, 2025 at 10:10 PM
Shenghao's Ph.D Thesis "Perspectives of Graph Diffusion: Computation, Local Partitioning, Statistical Recovery, and Applications" is now available.
Link: dspacemainprd01.lib.uwaterloo.ca/server/api/c...
Relevant papers:
1) Local Graph Clustering with Noisy Labels (ICLR 2024)
Link: dspacemainprd01.lib.uwaterloo.ca/server/api/c...
Relevant papers:
1) Local Graph Clustering with Noisy Labels (ICLR 2024)
I am still surprised by how difficult it is to train a 2-layer MLP to simply learn to copy or permute the input exactly. If k is the input length, the result below provides a (seemingly tight) upper bound of O(k²) training trials.
Can neural networks learn to copy or permute an input exactly with high probability? We study this basic and fundamental question in "Exact Learning of Permutations for Nonzero Binary Inputs with Logarithmic Training Size and Quadratic Ensemble Complexity"
Link: arxiv.org/abs/2502.16763
Link: arxiv.org/abs/2502.16763


April 1, 2025 at 12:55 PM
I am still surprised by how difficult it is to train a 2-layer MLP to simply learn to copy or permute the input exactly. If k is the input length, the result below provides a (seemingly tight) upper bound of O(k²) training trials.
New additions
1. Graph neural networks extrapolate out-of-distribution for shortest paths. arxiv.org/abs/2503.19173
2. Round and Round We Go! What makes Rotary Positional Encodings useful?. ICLR 2025. openreview.net/forum?id=Gtv...
1. Graph neural networks extrapolate out-of-distribution for shortest paths. arxiv.org/abs/2503.19173
2. Round and Round We Go! What makes Rotary Positional Encodings useful?. ICLR 2025. openreview.net/forum?id=Gtv...
March 31, 2025 at 5:34 PM
New additions
1. Graph neural networks extrapolate out-of-distribution for shortest paths. arxiv.org/abs/2503.19173
2. Round and Round We Go! What makes Rotary Positional Encodings useful?. ICLR 2025. openreview.net/forum?id=Gtv...
1. Graph neural networks extrapolate out-of-distribution for shortest paths. arxiv.org/abs/2503.19173
2. Round and Round We Go! What makes Rotary Positional Encodings useful?. ICLR 2025. openreview.net/forum?id=Gtv...
Our second kid arrived!
March 23, 2025 at 10:17 AM
Our second kid arrived!
Reposted by Kimon Fountoulakis

GLOW is returning on 𝗠𝗮𝗿𝗰𝗵 𝟮𝟲𝘁𝗵, 𝟱𝗽𝗺 𝗖𝗘𝗧 with a special guest: @petar-v.bsky.social 🌟
He will lecture on LLMs as GNNs – a topic which received quite some attention at our last session.
Specifically, we will learn how Graph ML tools can help understand LLM generalisation
He will lecture on LLMs as GNNs – a topic which received quite some attention at our last session.
Specifically, we will learn how Graph ML tools can help understand LLM generalisation
March 20, 2025 at 7:39 PM
GLOW is returning on 𝗠𝗮𝗿𝗰𝗵 𝟮𝟲𝘁𝗵, 𝟱𝗽𝗺 𝗖𝗘𝗧 with a special guest: @petar-v.bsky.social 🌟
He will lecture on LLMs as GNNs – a topic which received quite some attention at our last session.
Specifically, we will learn how Graph ML tools can help understand LLM generalisation
He will lecture on LLMs as GNNs – a topic which received quite some attention at our last session.
Specifically, we will learn how Graph ML tools can help understand LLM generalisation
1 out of 12 papers in my batch at ICML has a score above 3 (weak acceptance). Each paper has at least 3 reviews.
March 17, 2025 at 9:57 PM
1 out of 12 papers in my batch at ICML has a score above 3 (weak acceptance). Each paper has at least 3 reviews.