




Karim Farid ✈️ EURIPS 2025
@kifarid.bsky.social
PhD. Student @ELLIS.eu @UniFreiburg with Thomas Brox and Cordelia Schmid
Understanding intelligence and cultivating its societal benefits
https://kifarid.github.io
Understanding intelligence and cultivating its societal benefits
https://kifarid.github.io
There are similarities between JEPAs and PFNs. In JEPAs, synthetic data is generated through learning. Notably, random weights can already perform well on downstream tasks, suggesting that the learning process induces useful operations on which you can do predictive coding.
October 17, 2025 at 7:38 AM
There are similarities between JEPAs and PFNs. In JEPAs, synthetic data is generated through learning. Notably, random weights can already perform well on downstream tasks, suggesting that the learning process induces useful operations on which you can do predictive coding.
I really hope someone can revive continuous models for language. They’ve taken over the visual domain by far, but getting them to work in language still feels like pure alchemy.
October 12, 2025 at 7:31 PM
I really hope someone can revive continuous models for language. They’ve taken over the visual domain by far, but getting them to work in language still feels like pure alchemy.
Reposted by Karim Farid ✈️ EURIPS 2025

Excited to release our models and preprint: "Using Knowledge Graphs to harvest datasets for efficient CLIP model training"
We propose a dataset collection method using knowledge graphs and web image search, and create EntityNet-33M: a dataset of 33M images paired with 46M texts.
We propose a dataset collection method using knowledge graphs and web image search, and create EntityNet-33M: a dataset of 33M images paired with 46M texts.

Using Knowledge Graphs to harvest datasets for efficient CLIP model training
Training high-quality CLIP models typically requires enormous datasets, which limits the development of domain-specific models -- especially in areas that even the largest CLIP models do not cover wel...
arxiv.org
May 8, 2025 at 12:58 PM
Excited to release our models and preprint: "Using Knowledge Graphs to harvest datasets for efficient CLIP model training"
We propose a dataset collection method using knowledge graphs and web image search, and create EntityNet-33M: a dataset of 33M images paired with 46M texts.
We propose a dataset collection method using knowledge graphs and web image search, and create EntityNet-33M: a dataset of 33M images paired with 46M texts.
Reposted by Karim Farid ✈️ EURIPS 2025

Over the past year, my lab has been working on fleshing out theory + applications of the Platonic Representation Hypothesis.
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
October 10, 2025 at 10:13 PM
Over the past year, my lab has been working on fleshing out theory + applications of the Platonic Representation Hypothesis.
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
Our work Orbis goes to #NeurIPS2025!
A continuous autoregressive driving world model that outperforms Cosmos, Vista, and GEM with far less compute.
469M parameters
Trained on ~280h of driving videos
📄 arxiv.org/pdf/2507.13162
🎬 lmb-freiburg.github.io/orbis.github...
💻 github.com/lmb-freiburg...
A continuous autoregressive driving world model that outperforms Cosmos, Vista, and GEM with far less compute.
469M parameters
Trained on ~280h of driving videos
📄 arxiv.org/pdf/2507.13162
🎬 lmb-freiburg.github.io/orbis.github...
💻 github.com/lmb-freiburg...

October 12, 2025 at 2:39 PM
Our work Orbis goes to #NeurIPS2025!
A continuous autoregressive driving world model that outperforms Cosmos, Vista, and GEM with far less compute.
469M parameters
Trained on ~280h of driving videos
📄 arxiv.org/pdf/2507.13162
🎬 lmb-freiburg.github.io/orbis.github...
💻 github.com/lmb-freiburg...
A continuous autoregressive driving world model that outperforms Cosmos, Vista, and GEM with far less compute.
469M parameters
Trained on ~280h of driving videos
📄 arxiv.org/pdf/2507.13162
🎬 lmb-freiburg.github.io/orbis.github...
💻 github.com/lmb-freiburg...
The TRM works because it has an optimization algorithm as an inductive bias to find the answer. Can't say anything about this work but brilliant.
October 12, 2025 at 1:50 PM
The TRM works because it has an optimization algorithm as an inductive bias to find the answer. Can't say anything about this work but brilliant.
We should normalize having the ‘Ideas That Failed’ section. It would save enormous amounts of compute and time otherwise spent rediscovering stuff that doesn’t work.
October 12, 2025 at 1:49 PM
We should normalize having the ‘Ideas That Failed’ section. It would save enormous amounts of compute and time otherwise spent rediscovering stuff that doesn’t work.
Reposted by Karim Farid ✈️ EURIPS 2025

I stumbled on @eugenevinitsky.bsky.social 's blog and his "Personal Rules of Productive Research" is very good. I now do a lot of things in the post, & wish I had done them when I was younger.
I share my "mini-paper" w ppl I hope will be co-authors.
www.eugenevinitsky.com/posts/person...
I share my "mini-paper" w ppl I hope will be co-authors.
www.eugenevinitsky.com/posts/person...
Eugene Vinitsky
www.eugenevinitsky.com
December 16, 2024 at 3:14 PM
I stumbled on @eugenevinitsky.bsky.social 's blog and his "Personal Rules of Productive Research" is very good. I now do a lot of things in the post, & wish I had done them when I was younger.
I share my "mini-paper" w ppl I hope will be co-authors.
www.eugenevinitsky.com/posts/person...
I share my "mini-paper" w ppl I hope will be co-authors.
www.eugenevinitsky.com/posts/person...
Reposted by Karim Farid ✈️ EURIPS 2025


Reposted by Karim Farid ✈️ EURIPS 2025

My major realization of the past year of teaching is that a lot is forgiven if students believe you genuinely care about them and the topic
December 5, 2024 at 8:50 PM
My major realization of the past year of teaching is that a lot is forgiven if students believe you genuinely care about them and the topic
Reposted by Karim Farid ✈️ EURIPS 2025
Possible challenge: getting a model of {X,Y,Z,...} that is much better than independent models of each individual modality {X}, {Y}, {Z}, ... i.e. where the whole is greater than the sum of the parts.
December 4, 2024 at 8:24 PM
Possible challenge: getting a model of {X,Y,Z,...} that is much better than independent models of each individual modality {X}, {Y}, {Z}, ... i.e. where the whole is greater than the sum of the parts.
Reposted by Karim Farid ✈️ EURIPS 2025

I'm excited about scaling up robot learning! We’ve been scaling up data gen with RL in realistic sims generated from crowdsourced videos. Enables data collection far more cheaply than real world teleop. Importantly, data becomes *cheaper* with more environments and transfers to real robots! 🧵 (1/N)
December 5, 2024 at 2:13 AM
I'm excited about scaling up robot learning! We’ve been scaling up data gen with RL in realistic sims generated from crowdsourced videos. Enables data collection far more cheaply than real world teleop. Importantly, data becomes *cheaper* with more environments and transfers to real robots! 🧵 (1/N)
Reposted by Karim Farid ✈️ EURIPS 2025


Super! Can’t wait for the release of the technical report and see what is ditched and what is kept from v1.

Introducing 🧞Genie 2 🧞 - our most capable large-scale foundation world model, which can generate a diverse array of consistent worlds, playable for up to a minute. We believe Genie 2 could unlock the next wave of capabilities for embodied agents 🧠.
December 4, 2024 at 4:42 PM
Super! Can’t wait for the release of the technical report and see what is ditched and what is kept from v1.
Very insightful

A common question nowadays: Which is better, diffusion or flow matching? 🤔
Our answer: They’re two sides of the same coin. We wrote a blog post to show how diffusion models and Gaussian flow matching are equivalent. That’s great: It means you can use them interchangeably.
Our answer: They’re two sides of the same coin. We wrote a blog post to show how diffusion models and Gaussian flow matching are equivalent. That’s great: It means you can use them interchangeably.

December 2, 2024 at 6:48 PM
Very insightful
Reposted by Karim Farid ✈️ EURIPS 2025

So, refresher about my culture stuff. Here are examples of the four types of hand-designed "quizzes" I created. "Solving" it means to predict any of the four grids given the three others.
1/4
1/4

November 30, 2024 at 7:50 PM
So, refresher about my culture stuff. Here are examples of the four types of hand-designed "quizzes" I created. "Solving" it means to predict any of the four grids given the three others.
1/4
1/4
Reposted by Karim Farid ✈️ EURIPS 2025

🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
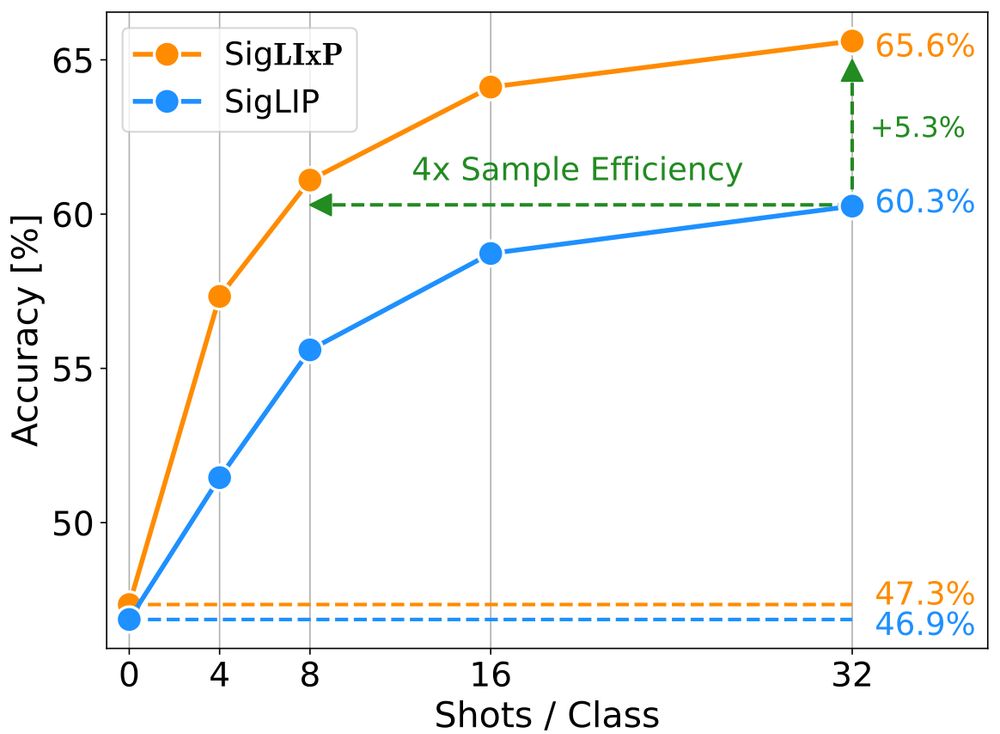
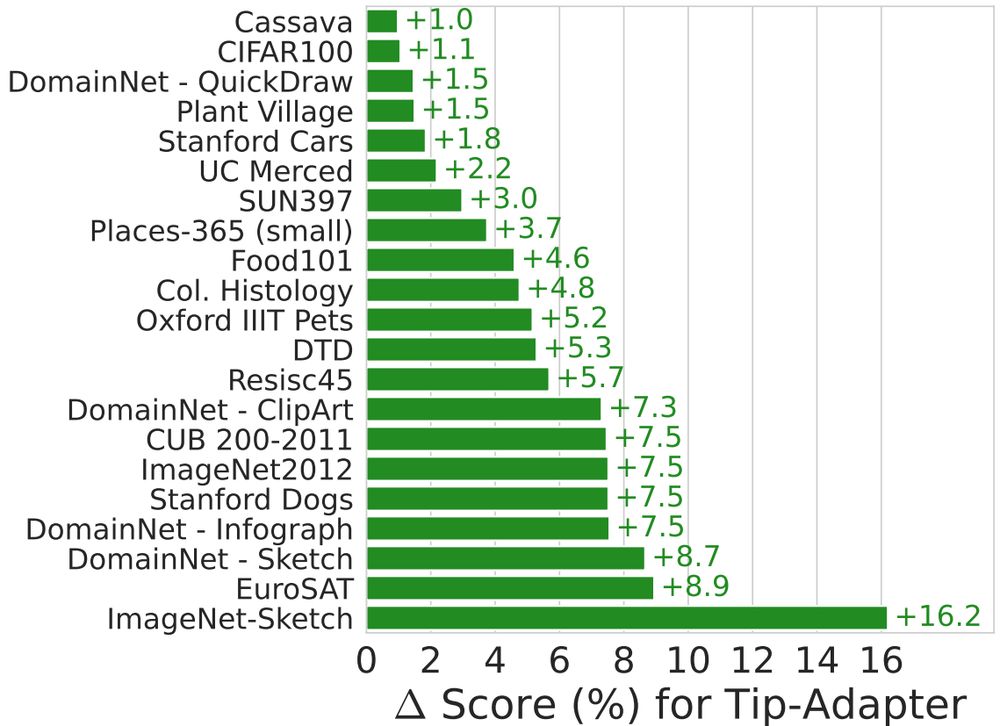

November 28, 2024 at 2:33 PM
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Reposted by Karim Farid ✈️ EURIPS 2025

I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
web.mit.edu
November 27, 2024 at 1:36 PM
I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
Reposted by Karim Farid ✈️ EURIPS 2025

Arxiv sharing reminder
pdf ❌
abs ✅
pdf ❌
abs ✅

November 26, 2024 at 8:42 AM
Arxiv sharing reminder
pdf ❌
abs ✅
pdf ❌
abs ✅
Reposted by Karim Farid ✈️ EURIPS 2025

Applications now open for 3rd Summer of Research
at Bristol in the #MachineLearning and #ComputerVision (MaVi) group.
Open for PhD students with overlapping interests to us? U can visit for 3 months this summer!
Apply before 20 Jan 2025.
uob-mavi.github.io/Summer@MaVi....
at Bristol in the #MachineLearning and #ComputerVision (MaVi) group.
Open for PhD students with overlapping interests to us? U can visit for 3 months this summer!
Apply before 20 Jan 2025.
uob-mavi.github.io/Summer@MaVi....
November 25, 2024 at 8:39 PM
Applications now open for 3rd Summer of Research
at Bristol in the #MachineLearning and #ComputerVision (MaVi) group.
Open for PhD students with overlapping interests to us? U can visit for 3 months this summer!
Apply before 20 Jan 2025.
uob-mavi.github.io/Summer@MaVi....
at Bristol in the #MachineLearning and #ComputerVision (MaVi) group.
Open for PhD students with overlapping interests to us? U can visit for 3 months this summer!
Apply before 20 Jan 2025.
uob-mavi.github.io/Summer@MaVi....
Reposted by Karim Farid ✈️ EURIPS 2025

Your worst fear in three words?
OpenReview Data Leak
OpenReview Data Leak
November 25, 2024 at 3:15 PM
Your worst fear in three words?
OpenReview Data Leak
OpenReview Data Leak
Reposted by Karim Farid ✈️ EURIPS 2025

Doing good science is 90% finding a science buddy to constantly talk to about the project.

November 9, 2024 at 10:53 PM
Doing good science is 90% finding a science buddy to constantly talk to about the project.
Reposted by Karim Farid ✈️ EURIPS 2025
Our paper "Dreaming of Many Worlds" studied zero-shot generalization in world models for Contextual RL and was later accepted by RLC and EWRL. Here's a thread summarizing the work and putting it in the context in retrospect as ideas for potential future collaborations!
arxiv.org/abs/2403.10967
arxiv.org/abs/2403.10967

Dreaming of Many Worlds: Learning Contextual World Models Aids Zero-Shot Generalization
Zero-shot generalization (ZSG) to unseen dynamics is a major challenge for creating generally capable embodied agents. To address the broader challenge, we start with the simpler setting of contextual...
arxiv.org
November 23, 2024 at 12:26 PM
Our paper "Dreaming of Many Worlds" studied zero-shot generalization in world models for Contextual RL and was later accepted by RLC and EWRL. Here's a thread summarizing the work and putting it in the context in retrospect as ideas for potential future collaborations!
arxiv.org/abs/2403.10967
arxiv.org/abs/2403.10967