



Michael Noukhovitch...🏄 NeurIPS 2025
@mnoukhov.bsky.social
PhD in AI @mila-quebec.bsky.social RLHF and language grounding, whatever that means. Whitespace aficianado. mnoukhov.github.io
Pinned
Our work on Asynchronous RLHF was accepted to #ICLR2025 ! (I was so excited to announce it, I forgot to say I was excited)
Used by @ai2.bsky.social for OLMo-2 32B 🔥
New results show ~70% speedups for LLM + RL math and reasoning 🧠
🧵below or hear my DLCT talk online on March 28!
Used by @ai2.bsky.social for OLMo-2 32B 🔥
New results show ~70% speedups for LLM + RL math and reasoning 🧠
🧵below or hear my DLCT talk online on March 28!
Check out Olmo 3 RL-Zero: a clean and scientific setup to benchmark RLVR
Everyone is finetuning with Qwen but its hard to know whether your eval is contaminated and skewing your RLVR results. Olmo 3 has a solution.
Everyone is finetuning with Qwen but its hard to know whether your eval is contaminated and skewing your RLVR results. Olmo 3 has a solution.
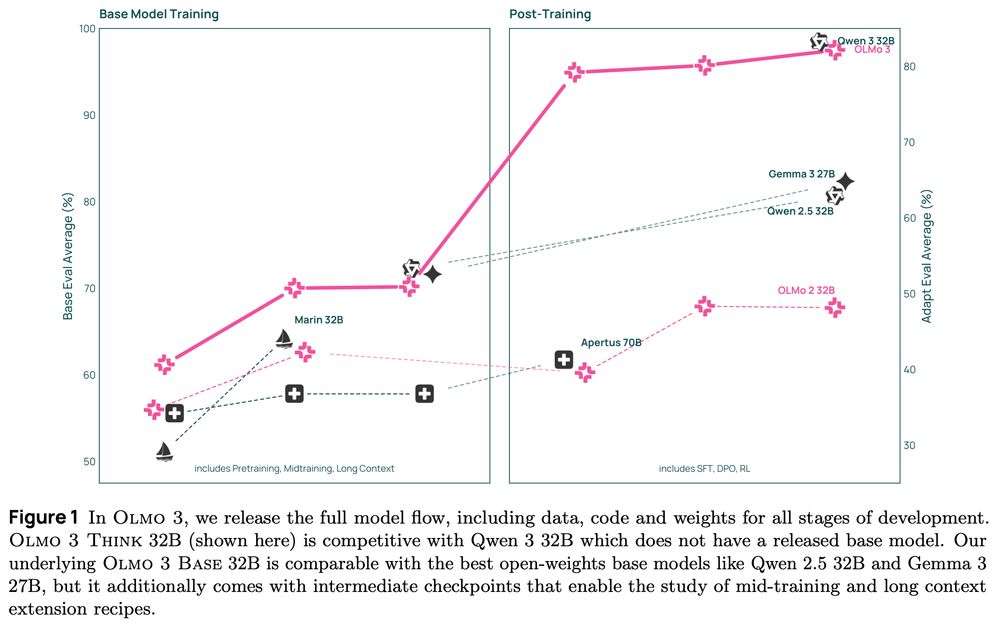
We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.


November 20, 2025 at 8:38 PM
Check out Olmo 3 RL-Zero: a clean and scientific setup to benchmark RLVR
Everyone is finetuning with Qwen but its hard to know whether your eval is contaminated and skewing your RLVR results. Olmo 3 has a solution.
Everyone is finetuning with Qwen but its hard to know whether your eval is contaminated and skewing your RLVR results. Olmo 3 has a solution.
Reposted by Michael Noukhovitch...🏄 NeurIPS 2025

We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
November 20, 2025 at 2:32 PM
We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.
Reposted by Michael Noukhovitch...🏄 NeurIPS 2025

Preprint Alert 🚀
Multi-agent reinforcement learning (MARL) often assumes that agents know when other agents cooperate with them. But for humans, this isn’t always the case. For example, plains indigenous groups used to leave resources for others to use at effigies called Manitokan.
1/8
Multi-agent reinforcement learning (MARL) often assumes that agents know when other agents cooperate with them. But for humans, this isn’t always the case. For example, plains indigenous groups used to leave resources for others to use at effigies called Manitokan.
1/8

June 5, 2025 at 3:32 PM
Preprint Alert 🚀
Multi-agent reinforcement learning (MARL) often assumes that agents know when other agents cooperate with them. But for humans, this isn’t always the case. For example, plains indigenous groups used to leave resources for others to use at effigies called Manitokan.
1/8
Multi-agent reinforcement learning (MARL) often assumes that agents know when other agents cooperate with them. But for humans, this isn’t always the case. For example, plains indigenous groups used to leave resources for others to use at effigies called Manitokan.
1/8
@dnllvy.bsky.social @oumarkaba.bsky.social presenting cool work at #ICLR2025 on generative models for crystals leveraging symmetry ❄️🪞, repping @mila-quebec.bsky.social

April 24, 2025 at 7:07 AM
@dnllvy.bsky.social @oumarkaba.bsky.social presenting cool work at #ICLR2025 on generative models for crystals leveraging symmetry ❄️🪞, repping @mila-quebec.bsky.social
Reposted by Michael Noukhovitch...🏄 NeurIPS 2025

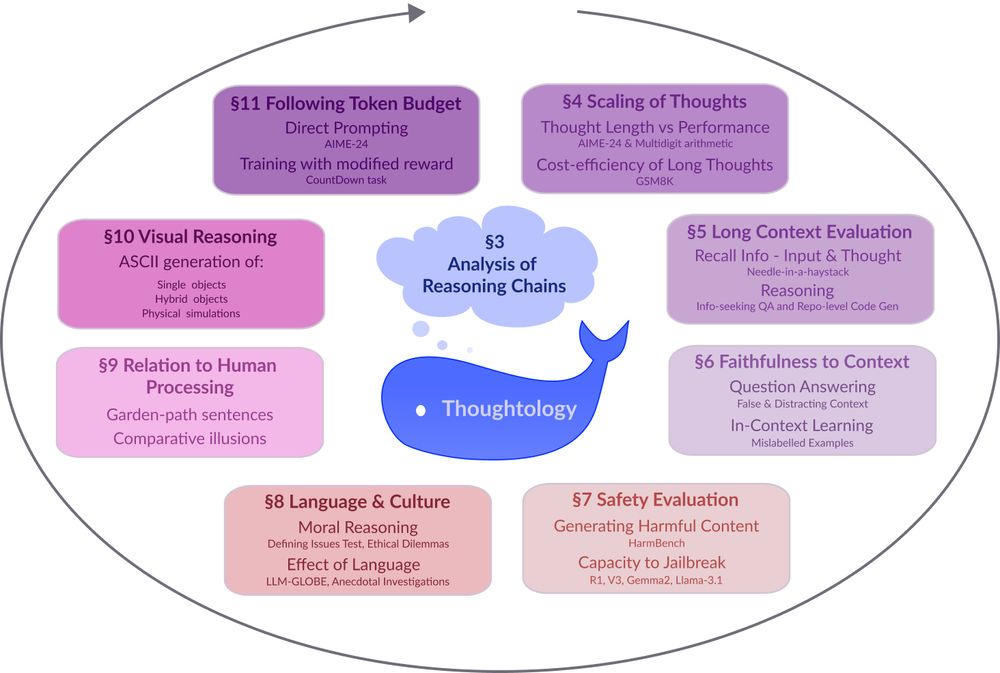
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/
🔗: mcgill-nlp.github.io/thoughtology/
April 1, 2025 at 8:07 PM
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/
🔗: mcgill-nlp.github.io/thoughtology/
Llama 4 uses async RLHF and I would just like to announce that I called it t.co/w9qJxr944C

April 7, 2025 at 7:39 PM
Llama 4 uses async RLHF and I would just like to announce that I called it t.co/w9qJxr944C
Our work on Asynchronous RLHF was accepted to #ICLR2025 ! (I was so excited to announce it, I forgot to say I was excited)
Used by @ai2.bsky.social for OLMo-2 32B 🔥
New results show ~70% speedups for LLM + RL math and reasoning 🧠
🧵below or hear my DLCT talk online on March 28!
Used by @ai2.bsky.social for OLMo-2 32B 🔥
New results show ~70% speedups for LLM + RL math and reasoning 🧠
🧵below or hear my DLCT talk online on March 28!
March 18, 2025 at 8:45 PM
Our work on Asynchronous RLHF was accepted to #ICLR2025 ! (I was so excited to announce it, I forgot to say I was excited)
Used by @ai2.bsky.social for OLMo-2 32B 🔥
New results show ~70% speedups for LLM + RL math and reasoning 🧠
🧵below or hear my DLCT talk online on March 28!
Used by @ai2.bsky.social for OLMo-2 32B 🔥
New results show ~70% speedups for LLM + RL math and reasoning 🧠
🧵below or hear my DLCT talk online on March 28!
Programming using an AI assistant in order to improve AI assistants is giving me strong sci-fi vibes. Specifically Isaac Asimov, who clearly invented vibe coding in 1956 users.ece.cmu.edu/~gamvrosi/th...

February 11, 2025 at 12:17 AM
Programming using an AI assistant in order to improve AI assistants is giving me strong sci-fi vibes. Specifically Isaac Asimov, who clearly invented vibe coding in 1956 users.ece.cmu.edu/~gamvrosi/th...
I'm at #NeurIPS2024 this week if anyone wants to talk about RLHF while drinking an overpriced (but excellent) pourover coffee or tea!
December 11, 2024 at 2:19 AM
I'm at #NeurIPS2024 this week if anyone wants to talk about RLHF while drinking an overpriced (but excellent) pourover coffee or tea!