




Nathan Godey
@nthngdy.bsky.social
Post-doc at Cornell Tech NYC
Working on the representations of LMs and pretraining methods
https://nathangodey.github.io
Working on the representations of LMs and pretraining methods
https://nathangodey.github.io
Reposted by Nathan Godey

Read Nathan's thread and (bsky.app/profile/nthn...) to get more details and the paper to get an even better picture: arxiv.org/abs/2510.25771.
Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social

November 12, 2025 at 11:18 PM
Read Nathan's thread and (bsky.app/profile/nthn...) to get more details and the paper to get an even better picture: arxiv.org/abs/2510.25771.
Reposted by Nathan Godey
Congratulations to @nthngdy.bsky.social, @wissamantoun.bsky.social and Rian Touchent (who worked under the supervision of @zehavoc.bsky.social, @bensagot.bsky.social, Éric de La Clergerie and me) on the training of these generative models for French, English and code.
November 12, 2025 at 11:18 PM
Congratulations to @nthngdy.bsky.social, @wissamantoun.bsky.social and Rian Touchent (who worked under the supervision of @zehavoc.bsky.social, @bensagot.bsky.social, Éric de La Clergerie and me) on the training of these generative models for French, English and code.
Reposted by Nathan Godey

I'm proud to share that at @inriaparisnlp.bsky.social we have released Gaperon — a suite of generative language models trained on French, English and code data, the largest of which has 24 billion parameters. Both the models and the code are being published under open licences. Short thread🧵
We are proud to announce that we trained 1.5B, 8B, and 24B generative language models from scratch on 2 to 4 tera-tokens of carefully curated, high-quality data covering French, English and code. We release our models and code under open-source licences. Thread👇

November 12, 2025 at 5:26 PM
I'm proud to share that at @inriaparisnlp.bsky.social we have released Gaperon — a suite of generative language models trained on French, English and code data, the largest of which has 24 billion parameters. Both the models and the code are being published under open licences. Short thread🧵
Reposted by Nathan Godey

We are proud to announce that we trained 1.5B, 8B, and 24B generative language models from scratch on 2 to 4 tera-tokens of carefully curated, high-quality data covering French, English and code. We release our models and code under open-source licences. Thread👇
November 12, 2025 at 5:05 PM
We are proud to announce that we trained 1.5B, 8B, and 24B generative language models from scratch on 2 to 4 tera-tokens of carefully curated, high-quality data covering French, English and code. We release our models and code under open-source licences. Thread👇
Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
November 7, 2025 at 9:11 PM
Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
Reposted by Nathan Godey
🏆🤩 We are excited to share the news that @nthngdy.bsky.social, supervised by @bensagot.bsky.social and Éric de la Clergerie, has received the 2025 ATALA Best PhD Dissertation Prize!
You can read his PhD online here: hal.science/tel-04994414/
You can read his PhD online here: hal.science/tel-04994414/

July 17, 2025 at 9:40 AM
🏆🤩 We are excited to share the news that @nthngdy.bsky.social, supervised by @bensagot.bsky.social and Éric de la Clergerie, has received the 2025 ATALA Best PhD Dissertation Prize!
You can read his PhD online here: hal.science/tel-04994414/
You can read his PhD online here: hal.science/tel-04994414/
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
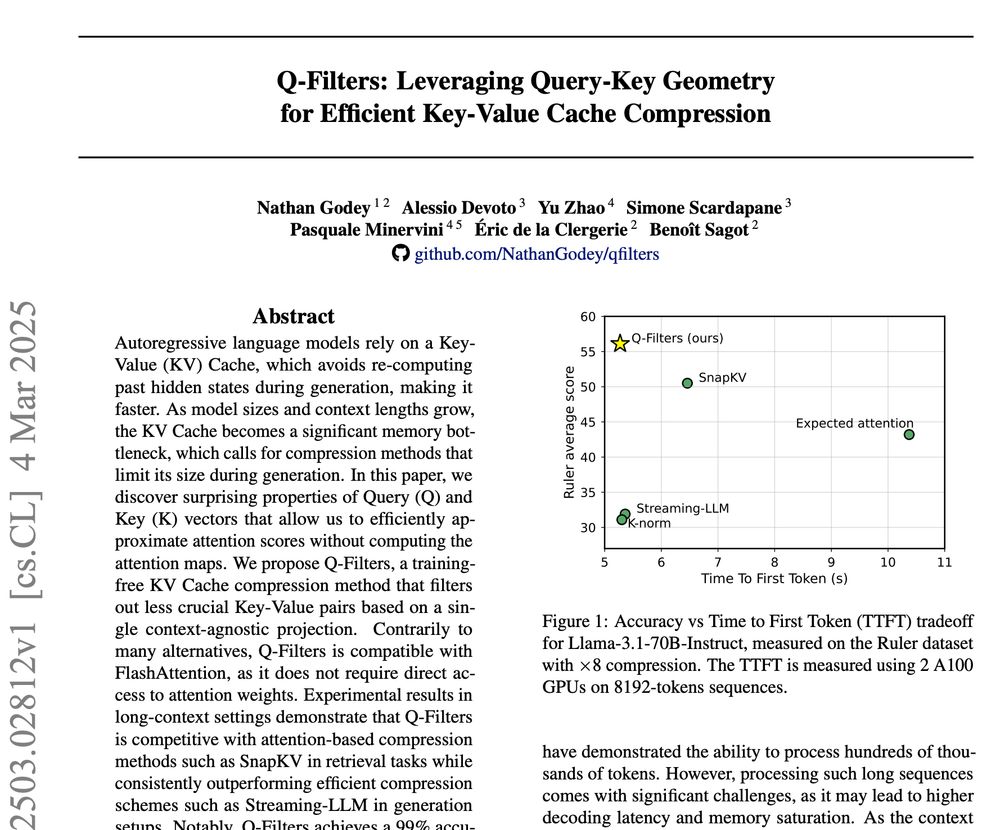
March 6, 2025 at 4:02 PM
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention