




Olivier Hénaff
@olivierhenaff.bsky.social
Working on something new, combining active, multimodal, and memory-augmented learning.
Formerly Senior Staff Scientist @GoogleDeepMind, PhD @NYU, @Polytechnique
Formerly Senior Staff Scientist @GoogleDeepMind, PhD @NYU, @Polytechnique
Pinned
Olivier Hénaff
@olivierhenaff.bsky.social
· Feb 14
After an amazing 6 years at Google DeepMind, I'm thrilled to announce that I'll be starting a new project at the intersection of multimodal foundation modeling, data curation, and human behavior.
If this is of interest to you please reach out!
If this is of interest to you please reach out!
After an amazing 6 years at Google DeepMind, I'm thrilled to announce that I'll be starting a new project at the intersection of multimodal foundation modeling, data curation, and human behavior.
If this is of interest to you please reach out!
If this is of interest to you please reach out!
February 14, 2025 at 6:45 PM
After an amazing 6 years at Google DeepMind, I'm thrilled to announce that I'll be starting a new project at the intersection of multimodal foundation modeling, data curation, and human behavior.
If this is of interest to you please reach out!
If this is of interest to you please reach out!
Active data curation keeps on giving.
This time we enabled the distillation of large multimodal models into much smaller ones, simply by choosing the data they learn from.
Sets a new state of the art in small multimodal models that are very efficient for inference!
This time we enabled the distillation of large multimodal models into much smaller ones, simply by choosing the data they learn from.
Sets a new state of the art in small multimodal models that are very efficient for inference!

🚀New Paper: Active Data Curation Effectively Distills Multimodal Models
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇
arxiv.org/abs/2411.18674
Smol models are all the rage these days & knowledge distillation (KD) is key for model compression!
We show how data curation can effectively distill to yield SoTA FLOP-efficient {C/Sig}LIPs!!
🧵👇

December 2, 2024 at 6:13 PM
Active data curation keeps on giving.
This time we enabled the distillation of large multimodal models into much smaller ones, simply by choosing the data they learn from.
Sets a new state of the art in small multimodal models that are very efficient for inference!
This time we enabled the distillation of large multimodal models into much smaller ones, simply by choosing the data they learn from.
Sets a new state of the art in small multimodal models that are very efficient for inference!
Reposted by Olivier Hénaff

This was an insightful project I worked on at Google DeepMind alongside the amazing @zeynepakata.bsky.social , @dimadamen.bsky.social , @ibalazevic.bsky.social and @olivierhenaff.bsky.social:
👉Language-image pretraining with CLIP or SigLIP is widely used due to strong zero-shot transfer, but ....
👉Language-image pretraining with CLIP or SigLIP is widely used due to strong zero-shot transfer, but ....
November 28, 2024 at 2:33 PM
This was an insightful project I worked on at Google DeepMind alongside the amazing @zeynepakata.bsky.social , @dimadamen.bsky.social , @ibalazevic.bsky.social and @olivierhenaff.bsky.social:
👉Language-image pretraining with CLIP or SigLIP is widely used due to strong zero-shot transfer, but ....
👉Language-image pretraining with CLIP or SigLIP is widely used due to strong zero-shot transfer, but ....
Reposted by Olivier Hénaff

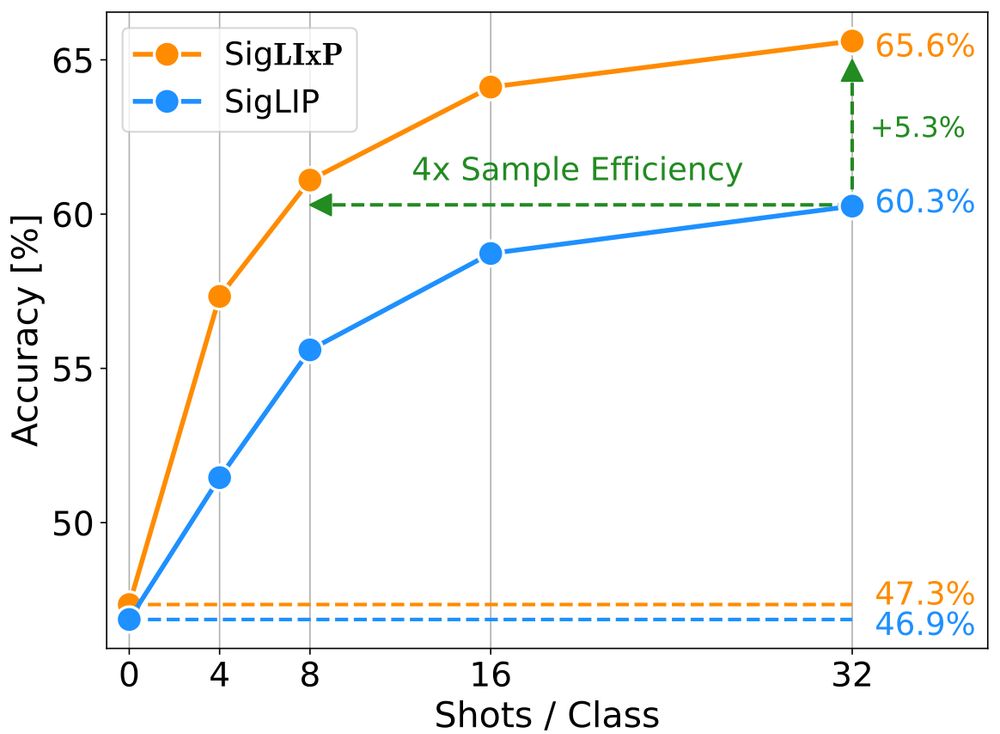
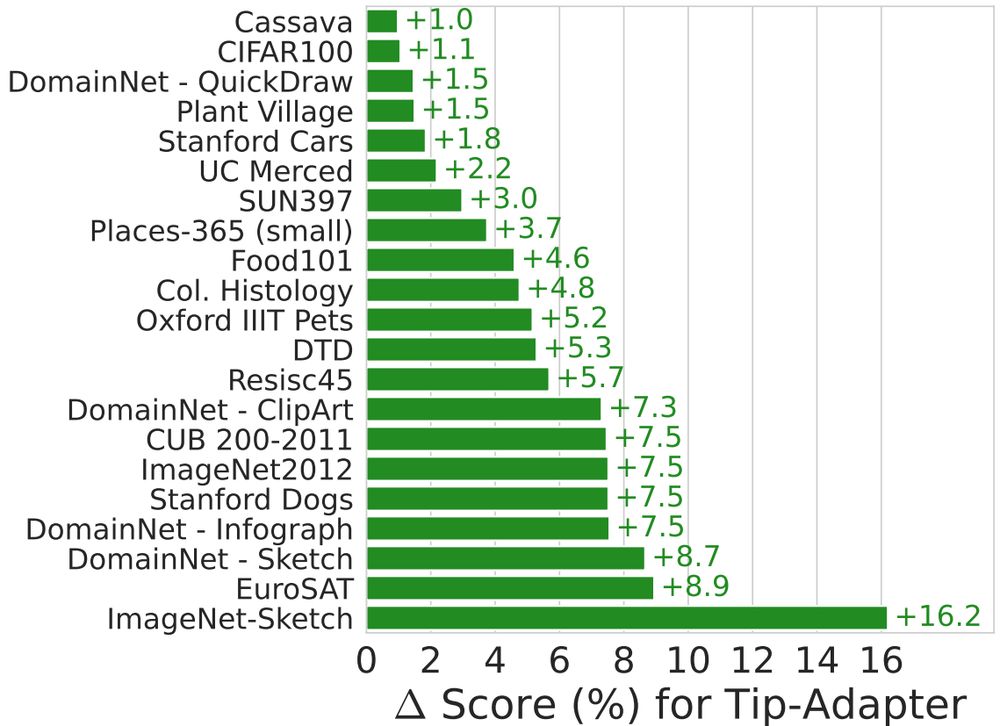
We maintain strong zero-shot transfer of CLIP / SigLIP across model size and data scale, while achieving up to 4x few-shot sample efficiency and up to +16% performance gains!
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:

November 28, 2024 at 2:43 PM
We maintain strong zero-shot transfer of CLIP / SigLIP across model size and data scale, while achieving up to 4x few-shot sample efficiency and up to +16% performance gains!
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.
Fun project with @confusezius.bsky.social, @zeynepakata.bsky.social, @dimadamen.bsky.social and
@olivierhenaff.bsky.social.
More than zero-shot generalization, few-shot *adaptation* is critical for many applications.
We find simple changes to multimodal pretraining are sufficient to yield outsized gains on a wide range of few-shot tasks.
Congratulations @confusezius.bsky.social on a very successful internship!
We find simple changes to multimodal pretraining are sufficient to yield outsized gains on a wide range of few-shot tasks.
Congratulations @confusezius.bsky.social on a very successful internship!
🤔 Can you turn your vision-language model from a great zero-shot model into a great-at-any-shot generalist?
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
Turns out you can, and here is how: arxiv.org/abs/2411.15099
Really excited to this work on multimodal pretraining for my first bluesky entry!
🧵 A short and hopefully informative thread:
November 28, 2024 at 2:47 PM
More than zero-shot generalization, few-shot *adaptation* is critical for many applications.
We find simple changes to multimodal pretraining are sufficient to yield outsized gains on a wide range of few-shot tasks.
Congratulations @confusezius.bsky.social on a very successful internship!
We find simple changes to multimodal pretraining are sufficient to yield outsized gains on a wide range of few-shot tasks.
Congratulations @confusezius.bsky.social on a very successful internship!