



Raj Movva
@rajmovva.bsky.social
NLP, ML & society, healthcare.
PhD student at Berkeley, previously CS at MIT.
https://rajivmovva.com/
PhD student at Berkeley, previously CS at MIT.
https://rajivmovva.com/
Pinned
Raj Movva
@rajmovva.bsky.social
· Mar 18
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/

Reposted by Raj Movva

New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.

October 17, 2025 at 4:29 PM
New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.
Reposted by Raj Movva
I am on the job market this year! My research advances methods for reliable machine learning from real-world data, with a focus on healthcare. Happy to chat if this is of interest to you or your department/team.
October 14, 2025 at 3:45 PM
I am on the job market this year! My research advances methods for reliable machine learning from real-world data, with a focus on healthcare. Happy to chat if this is of interest to you or your department/team.
Reposted by Raj Movva

I've been working for many months on this article on Silicon Valley's under-the-radar role in bringing AI into schools across the US. I really hope you'll read it — here's a gift link — but I'll tell you some of the highlights in this thread. (1/x)

How Chatbots and AI Are Already Transforming Kids' Classrooms
Educators across the country are bringing chatbots into their lesson plans. Will it help kids learn or is it just another doomed ed-tech fad?
www.bloomberg.com
September 2, 2025 at 4:31 PM
I've been working for many months on this article on Silicon Valley's under-the-radar role in bringing AI into schools across the US. I really hope you'll read it — here's a gift link — but I'll tell you some of the highlights in this thread. (1/x)
Reposted by Raj Movva

🚨 New postdoc position in our lab at Berkeley EECS! 🚨
(please reshare)
We seek applicants with experience in language modeling who are excited about high-impact applications in the health and social sciences!
More info in thread
1/3
(please reshare)
We seek applicants with experience in language modeling who are excited about high-impact applications in the health and social sciences!
More info in thread
1/3

August 22, 2025 at 2:11 PM
🚨 New postdoc position in our lab at Berkeley EECS! 🚨
(please reshare)
We seek applicants with experience in language modeling who are excited about high-impact applications in the health and social sciences!
More info in thread
1/3
(please reshare)
We seek applicants with experience in language modeling who are excited about high-impact applications in the health and social sciences!
More info in thread
1/3
This is great, & there's clear analogy to the burgeoning mechanism design community for AI alignment: who is providing RLHF votes? Do their preferences reflect yours? Discussions about social choice and collective constitutions are interesting, but "what and who is in the data" is just as important.
New piece, out in the Sigecom Exchanges! It's my first solo-author piece, and the closest thing I've written to being my "manifesto." #econsky #ecsky
arxiv.org/abs/2507.03600
arxiv.org/abs/2507.03600

August 18, 2025 at 7:43 PM
This is great, & there's clear analogy to the burgeoning mechanism design community for AI alignment: who is providing RLHF votes? Do their preferences reflect yours? Discussions about social choice and collective constitutions are interesting, but "what and who is in the data" is just as important.
📢New POSITION PAPER: Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵

August 5, 2025 at 4:33 PM
📢New POSITION PAPER: Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵
Reposted by Raj Movva

Are LLMs correlated when they make mistakes? In our new ICML paper, we answer this question using responses of >350 LLMs. We find substantial correlation. On one dataset, LLMs agree on the wrong answer ~2x more than they would at random. 🧵(1/7)
arxiv.org/abs/2506.07962
arxiv.org/abs/2506.07962

July 3, 2025 at 12:54 PM
Are LLMs correlated when they make mistakes? In our new ICML paper, we answer this question using responses of >350 LLMs. We find substantial correlation. On one dataset, LLMs agree on the wrong answer ~2x more than they would at random. 🧵(1/7)
arxiv.org/abs/2506.07962
arxiv.org/abs/2506.07962
Reposted by Raj Movva

@jessica.bsky.social on individual reporting as a means to build collective knowledge.

Individual experiences and collective evidence
Jessica Dai on theory for the world as it could be
www.argmin.net
June 24, 2025 at 2:46 PM
@jessica.bsky.social on individual reporting as a means to build collective knowledge.
ARR question: If I submit to a cycle, how long do those reviews "last"? e.g. if I submit to the July cycle but can't go to AACL, can I commit my July reviews to the conference associated with the next (October) cycle? @aclrollingreview.bsky.social
June 17, 2025 at 9:14 PM
ARR question: If I submit to a cycle, how long do those reviews "last"? e.g. if I submit to the July cycle but can't go to AACL, can I commit my July reviews to the conference associated with the next (October) cycle? @aclrollingreview.bsky.social
Reposted by Raj Movva
New work 🎉: conformal classifiers return sets of classes for each example, with a probabilistic guarantee the true class is included. But these sets can be too large to be useful.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.

June 14, 2025 at 3:00 PM
New work 🎉: conformal classifiers return sets of classes for each example, with a probabilistic guarantee the true class is included. But these sets can be too large to be useful.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
In our #CVPR2025 paper, we propose a method to make them more compact without sacrificing coverage.
I would like to spend up to 5-10 hours to learn about basic macroeconomics (I know it's maybe fake, but setting that aside for a moment...). Does anyone have any recommendations?
June 5, 2025 at 11:29 PM
I would like to spend up to 5-10 hours to learn about basic macroeconomics (I know it's maybe fake, but setting that aside for a moment...). Does anyone have any recommendations?
People love to hate on the transition 3-pointer as evidence of how the 3 has ruined basketball, but I think it's usually just the right play... if you have numbers in transition, your teammate can easily get a putback off a miss, so might as well try the 3
May 10, 2025 at 8:09 PM
People love to hate on the transition 3-pointer as evidence of how the 3 has ruined basketball, but I think it's usually just the right play... if you have numbers in transition, your teammate can easily get a putback off a miss, so might as well try the 3
We'll present HypotheSAEs at ICML this summer! 🎉
Draft: arxiv.org/abs/2502.04382
We're continuing to cook up new updates for our Python package: github.com/rmovva/Hypot...
(Recently, "Matryoshka SAEs", which help extract coarse and granular concepts without as much hyperparameter fiddling.)
Draft: arxiv.org/abs/2502.04382
We're continuing to cook up new updates for our Python package: github.com/rmovva/Hypot...
(Recently, "Matryoshka SAEs", which help extract coarse and granular concepts without as much hyperparameter fiddling.)
May 5, 2025 at 9:27 PM
We'll present HypotheSAEs at ICML this summer! 🎉
Draft: arxiv.org/abs/2502.04382
We're continuing to cook up new updates for our Python package: github.com/rmovva/Hypot...
(Recently, "Matryoshka SAEs", which help extract coarse and granular concepts without as much hyperparameter fiddling.)
Draft: arxiv.org/abs/2502.04382
We're continuing to cook up new updates for our Python package: github.com/rmovva/Hypot...
(Recently, "Matryoshka SAEs", which help extract coarse and granular concepts without as much hyperparameter fiddling.)
Yesterday's Game 6 was depressing, and this article precisely delineated the reasons why. And sometimes, a precise retelling of what you're feeling is all you need to feel better. www.nytimes.com/athletic/633... @thompsonscribe.bsky.social

These Warriors are old, tired and in trouble as Game 7 looms against Rockets
They're not done yet. Maybe a legendary performance awaits on Sunday. But the Warriors look like they're out of gas and out of answers.
www.nytimes.com
May 3, 2025 at 10:50 PM
Yesterday's Game 6 was depressing, and this article precisely delineated the reasons why. And sometimes, a precise retelling of what you're feeling is all you need to feel better. www.nytimes.com/athletic/633... @thompsonscribe.bsky.social
Check out Erica's nice work. They not only develop a well-grounded model for disparities in disease progression, but also conduct experiments with real NYP cardiology data! (Anyone who works in healthcare knows how much of a feat it is to use data other than MIMIC)

I’m really excited to share the first paper of my PhD, “Learning Disease Progression Models That Capture Health Disparities” (accepted at #CHIL2025)! ✨ 1/
📄: arxiv.org/abs/2412.16406
📄: arxiv.org/abs/2412.16406
May 1, 2025 at 5:10 PM
Check out Erica's nice work. They not only develop a well-grounded model for disparities in disease progression, but also conduct experiments with real NYP cardiology data! (Anyone who works in healthcare knows how much of a feat it is to use data other than MIMIC)
Reposted by Raj Movva
The US government recently flagged my scientific grant in its "woke DEI database". Many people have asked me what I will do.
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...

My ‘woke DEI’ grant has been flagged for scrutiny. Where do I go from here?
My work in making artificial intelligence fair has been noticed by US officials intent on ending ‘class warfare propaganda’.
www.nature.com
April 25, 2025 at 5:19 PM
The US government recently flagged my scientific grant in its "woke DEI database". Many people have asked me what I will do.
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
My answer today in Nature.
We will not be cowed. We will keep using AI to build a fairer, healthier world.
www.nature.com/articles/d41...
Good reading for PhD students on why meeting scheduling might be more important than you think: paulgraham.com/makersschedu...
Maker's Schedule, Manager's Schedule
paulgraham.com
April 22, 2025 at 3:51 PM
Good reading for PhD students on why meeting scheduling might be more important than you think: paulgraham.com/makersschedu...
Reposted by Raj Movva

1st post on bsky!
What happens when a static benchmark comes to life? ✨ Introducing ChatBench, a large-scale user study where we *converted* MMLU questions into thousands of user-AI conversations. Then, we trained a user simulator on ChatBench to generate user-AI outcomes on unseen questions. 1/ 🧵
What happens when a static benchmark comes to life? ✨ Introducing ChatBench, a large-scale user study where we *converted* MMLU questions into thousands of user-AI conversations. Then, we trained a user simulator on ChatBench to generate user-AI outcomes on unseen questions. 1/ 🧵

April 11, 2025 at 5:57 PM
1st post on bsky!
What happens when a static benchmark comes to life? ✨ Introducing ChatBench, a large-scale user study where we *converted* MMLU questions into thousands of user-AI conversations. Then, we trained a user simulator on ChatBench to generate user-AI outcomes on unseen questions. 1/ 🧵
What happens when a static benchmark comes to life? ✨ Introducing ChatBench, a large-scale user study where we *converted* MMLU questions into thousands of user-AI conversations. Then, we trained a user simulator on ChatBench to generate user-AI outcomes on unseen questions. 1/ 🧵
A weird (and seemingly fixable quirk) with ChatGPT Deep Research is hallucinations even when there is a linked citation with a highlighted passage: "X et al find Y (arXiv link)" and you click on the arXiv link, which is neither written by X nor do they find Y...
April 10, 2025 at 4:36 PM
A weird (and seemingly fixable quirk) with ChatGPT Deep Research is hallucinations even when there is a linked citation with a highlighted passage: "X et al find Y (arXiv link)" and you click on the arXiv link, which is neither written by X nor do they find Y...
Reposted by Raj Movva

Stop everything you are doing and review the best Open Data chart you will see all year.
Credit: @nkgarg.bsky.social's lab
Credit: @nkgarg.bsky.social's lab
2) The dog name/baby name scatter plot: Max and Charlie are more dog name than human name. Dogs aren't called Ethan though.
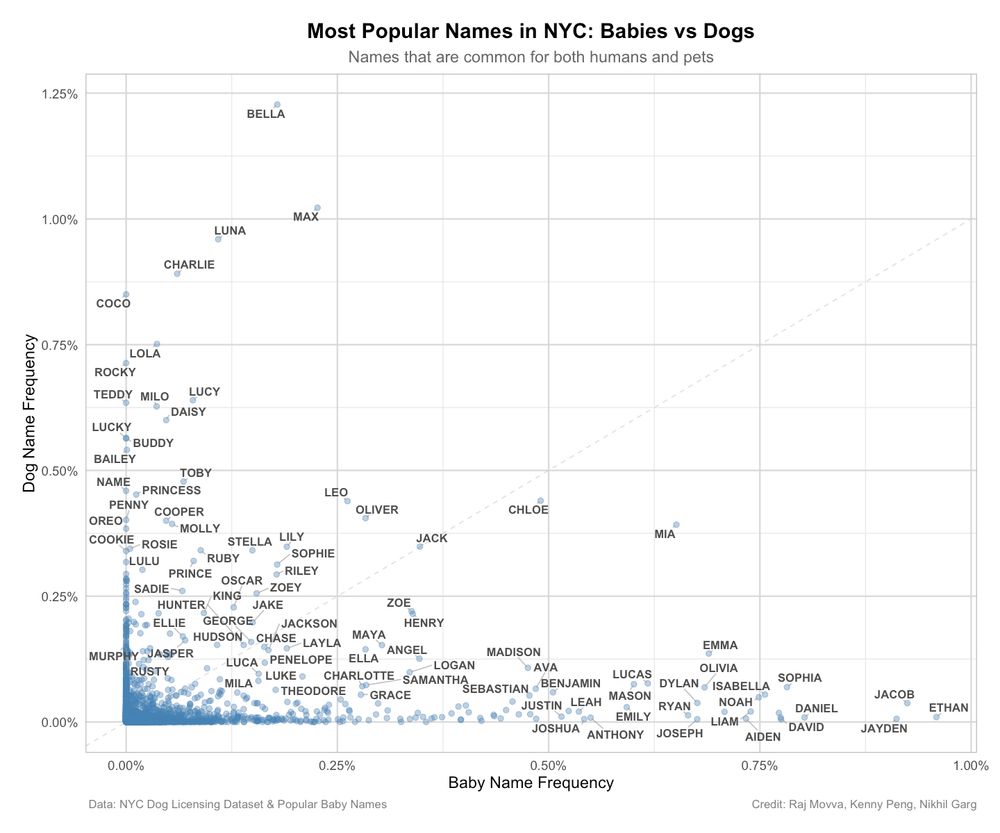
April 2, 2025 at 2:59 PM
Stop everything you are doing and review the best Open Data chart you will see all year.
Credit: @nkgarg.bsky.social's lab
Credit: @nkgarg.bsky.social's lab
My labmates really cooked with this one
Our lab had a #dogathon 🐕 yesterday where we analyzed NYC Open Data on dog licenses. We learned a lot of dog facts, which I’ll share in this thread 🧵
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
1) Geospatial trends: Cavalier King Charles Spaniels are common in Manhattan; the opposite is true for Yorkshire Terriers.
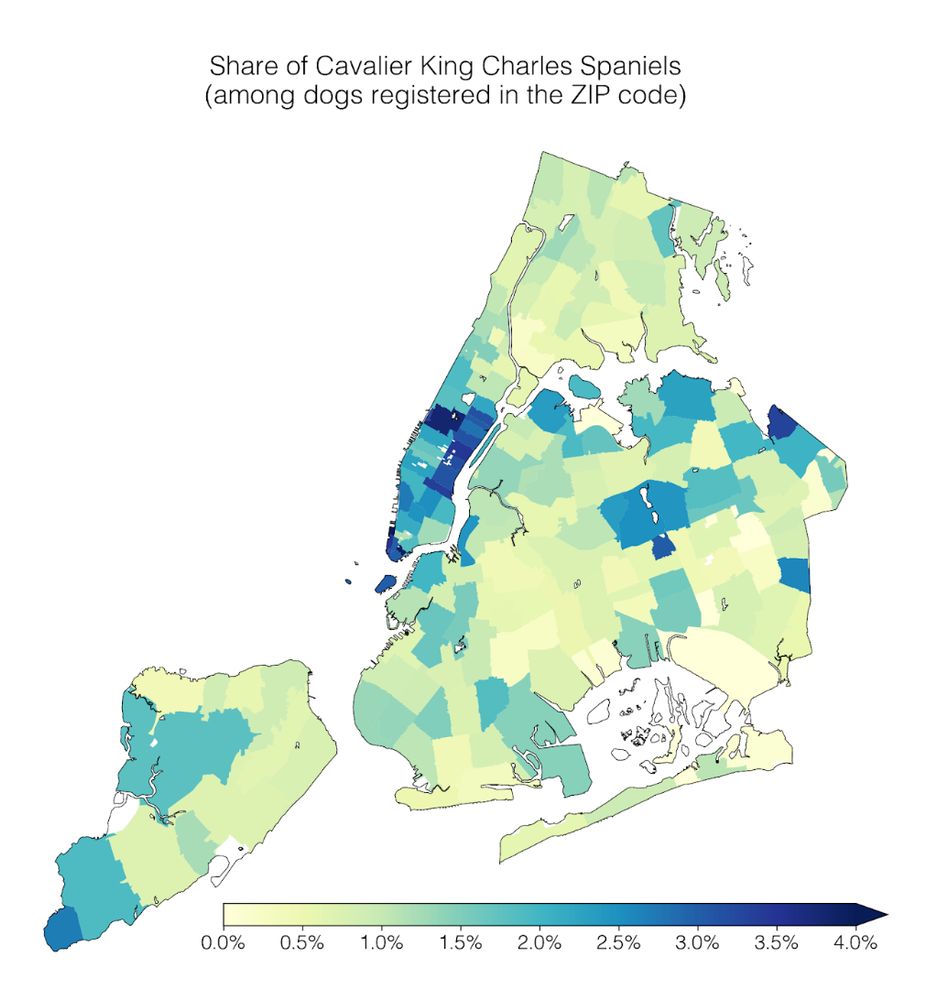
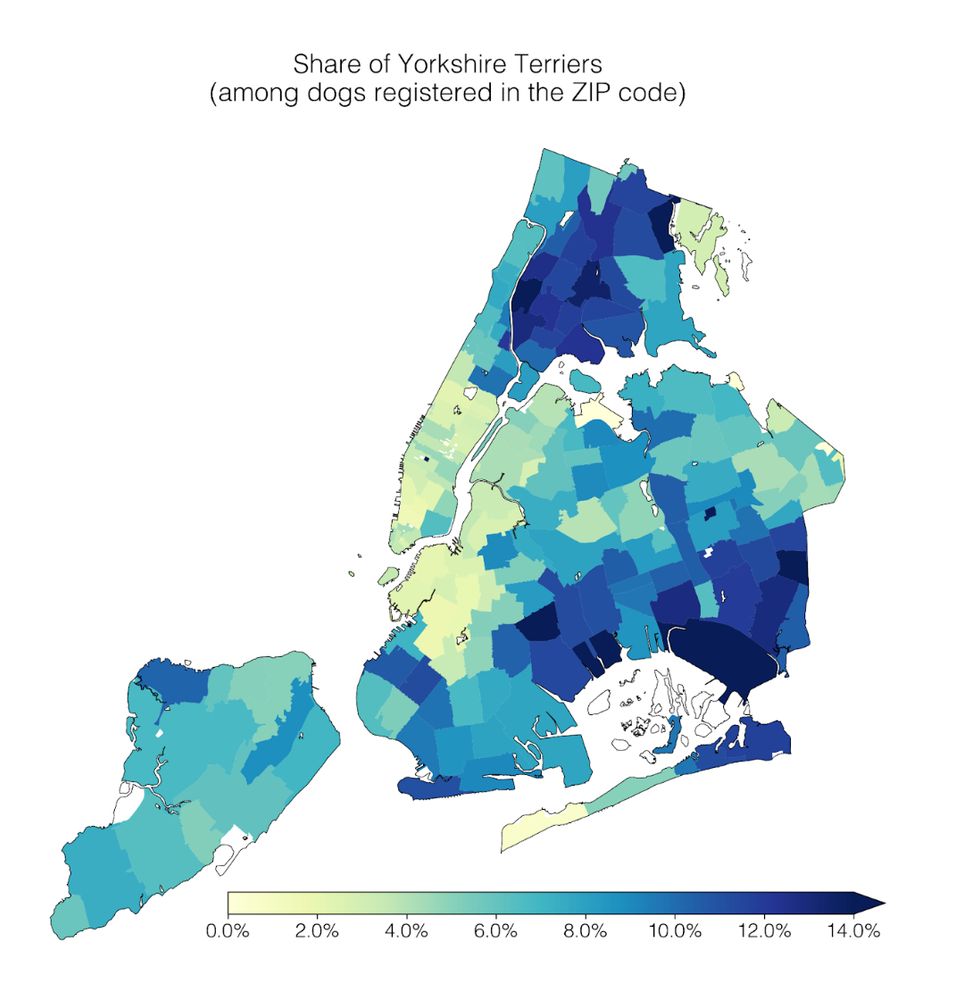
April 2, 2025 at 5:00 PM
My labmates really cooked with this one
Reposted by Raj Movva

Migration data lets us study responses to environmental disasters, social change patterns, policy impacts, etc. But public data is too coarse, obscuring these important phenomena!
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
March 28, 2025 at 3:25 PM
Migration data lets us study responses to environmental disasters, social change patterns, policy impacts, etc. But public data is too coarse, obscuring these important phenomena!
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
We build MIGRATE: a dataset of yearly flows between 47 billion pairs of US Census Block Groups. 1/5
I've learned MCMC 5+ different times in the last 10 years from courses, videos, blogposts, etc, and it never clicked. 30 minutes chatting with Claude this morning, and I finally feel like I've figured it out...
March 21, 2025 at 6:02 PM
I've learned MCMC 5+ different times in the last 10 years from courses, videos, blogposts, etc, and it never clicked. 30 minutes chatting with Claude this morning, and I finally feel like I've figured it out...
Reposted by Raj Movva

Really proud of @rajmovva.bsky.social and @kennypeng.bsky.social for this work! We hope that it's useful, and are already using it for many followup projects
Preprint: arxiv.org/abs/2502.04382
Python package: github.com/rmovva/Hypot...
Demo: hypothesaes.org
Preprint: arxiv.org/abs/2502.04382
Python package: github.com/rmovva/Hypot...
Demo: hypothesaes.org
💡New preprint & Python package: We use sparse autoencoders to generate hypotheses from large text datasets.
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
Our method, HypotheSAEs, produces interpretable text features that predict a target variable, e.g. features in news headlines that predict engagement. 🧵1/
March 18, 2025 at 3:21 PM
Really proud of @rajmovva.bsky.social and @kennypeng.bsky.social for this work! We hope that it's useful, and are already using it for many followup projects
Preprint: arxiv.org/abs/2502.04382
Python package: github.com/rmovva/Hypot...
Demo: hypothesaes.org
Preprint: arxiv.org/abs/2502.04382
Python package: github.com/rmovva/Hypot...
Demo: hypothesaes.org