

Johannes Schwenke
@schwenkej.bsky.social
160 followers
220 following
84 posts
MD | PhD Student in Clinical Epidemiology @UniBasel. | Supervisor: Matthias Briel
#ClinicalTrials #RStats
Posts
Media
Videos
Starter Packs


Johannes Schwenke
@schwenkej.bsky.social
· Aug 26
Johannes Schwenke
@schwenkej.bsky.social
· Aug 26
Johannes Schwenke
@schwenkej.bsky.social
· Aug 26
Reposted by Johannes Schwenke






Johannes Schwenke
@schwenkej.bsky.social
· Aug 10


Johannes Schwenke
@schwenkej.bsky.social
· Jul 29
Reposted by Johannes Schwenke

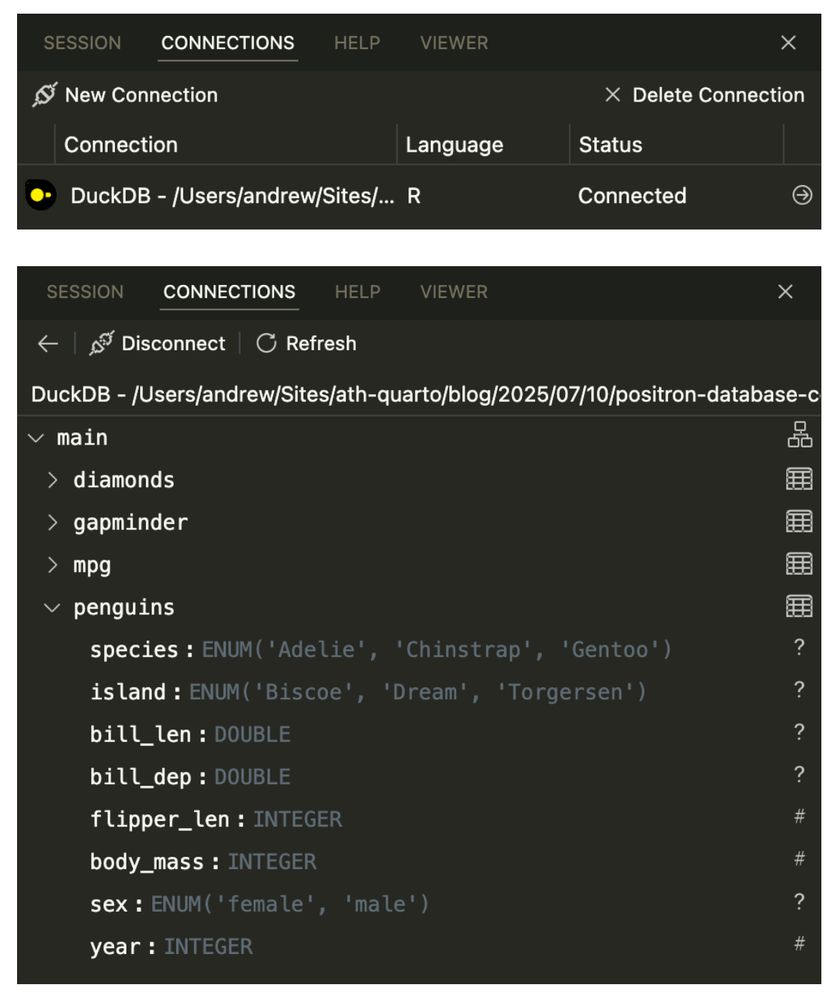

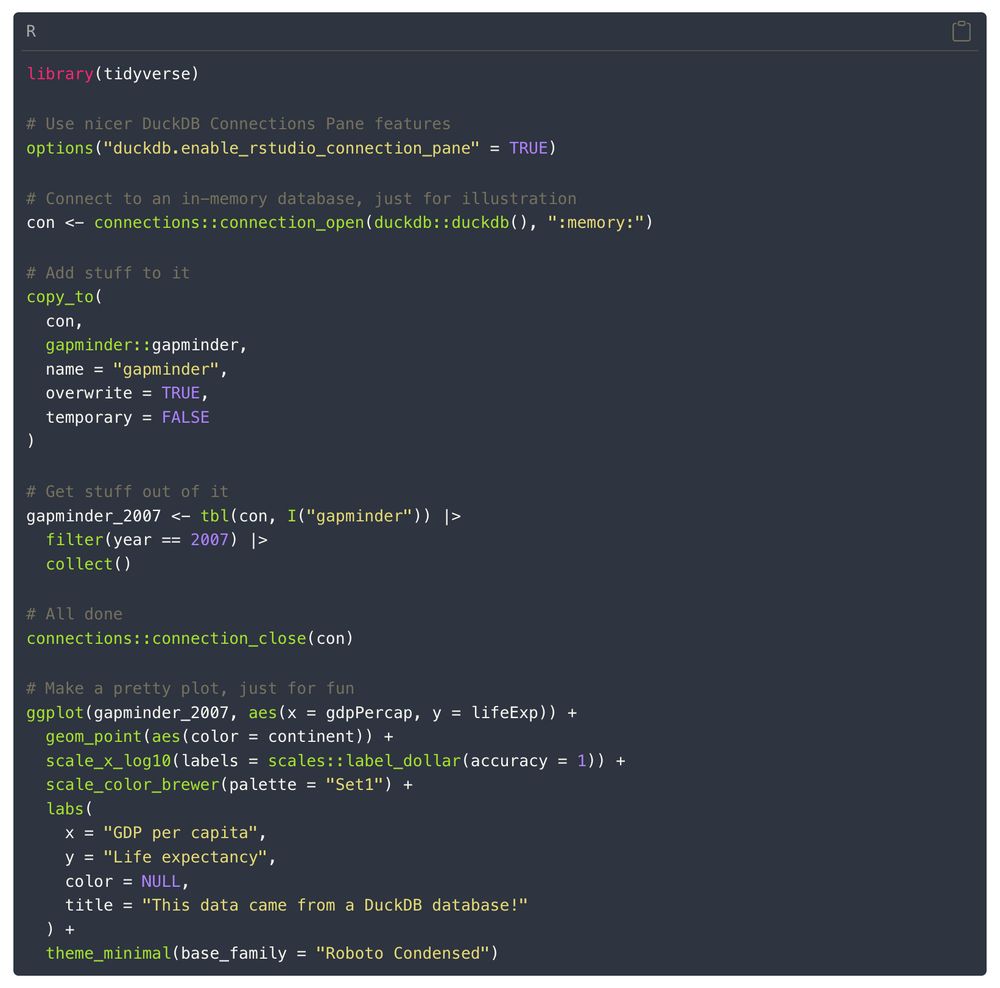
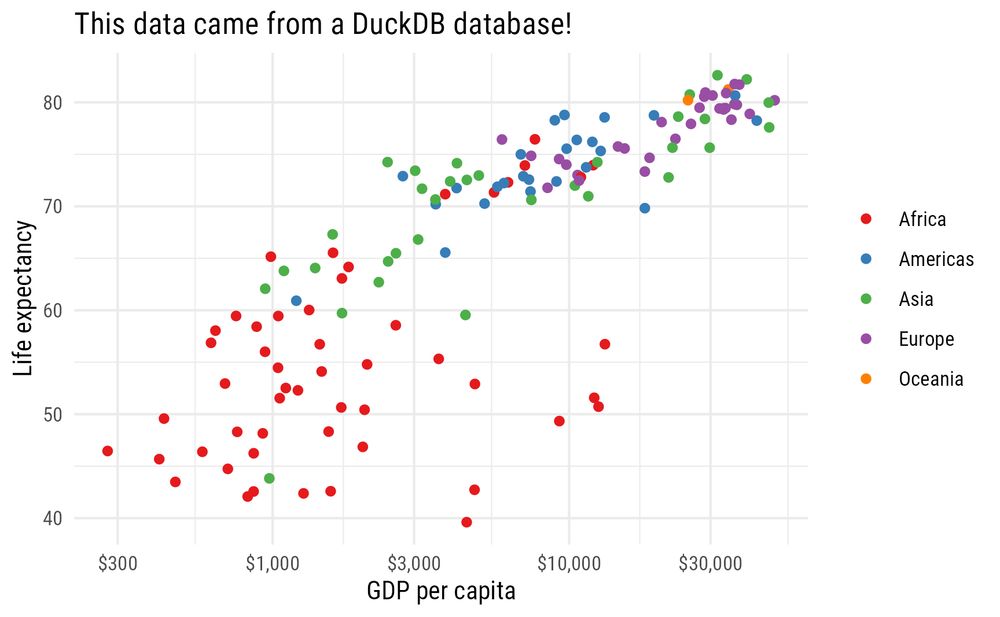
Reposted by Johannes Schwenke

Ruben C. Arslan
@ruben.the100.ci
· Jul 8