
Adeel Razi
@adeelrazi.bsky.social
2.7K followers
1.4K following
86 posts
Computational Neuroscientist, NeuroAI, Causality. Monash, UCL, CIFAR. Lab: https://comp-neuro.github.io/
Posts
Media
Videos
Starter Packs
Pinned

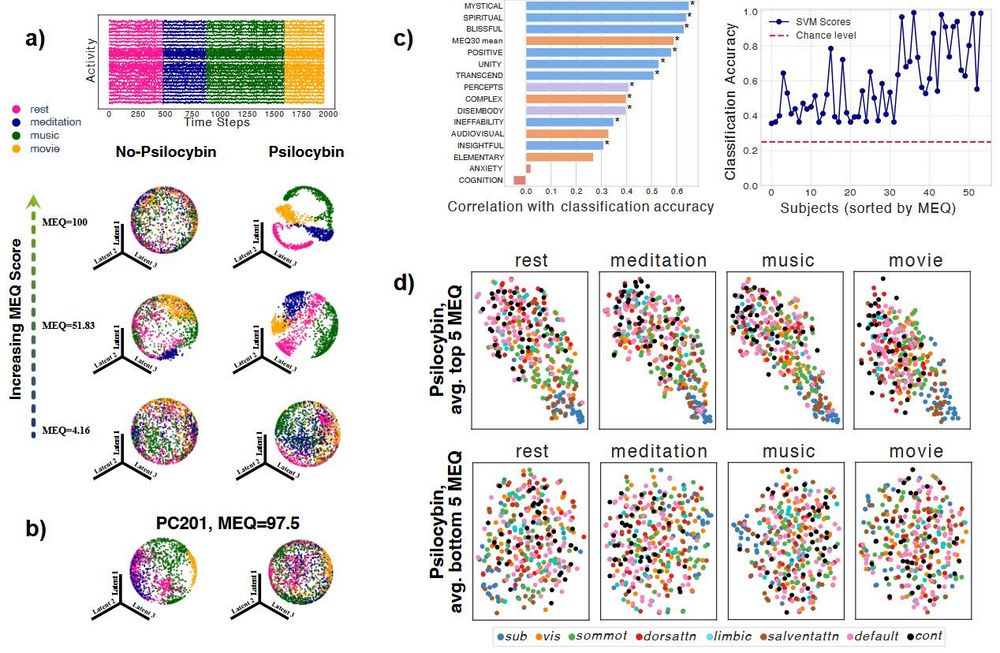




Reposted by Adeel Razi

Adeel Razi
@adeelrazi.bsky.social
· Jul 30

Untangling Addiction Program Details | Wellcome Leap: Unconventional Projects. Funded at Scale.
NEW $50M PROGRAMUntangling AddictionWe are pleased to announce the selected performers.Yasmin Hurd, Icahn School of Medicine at Mount SinaiBrett Ginsburg, University of Texas Health Science Center at ...
wellcomeleap.org
Adeel Razi
@adeelrazi.bsky.social
· Jul 30


Reposted by Adeel Razi

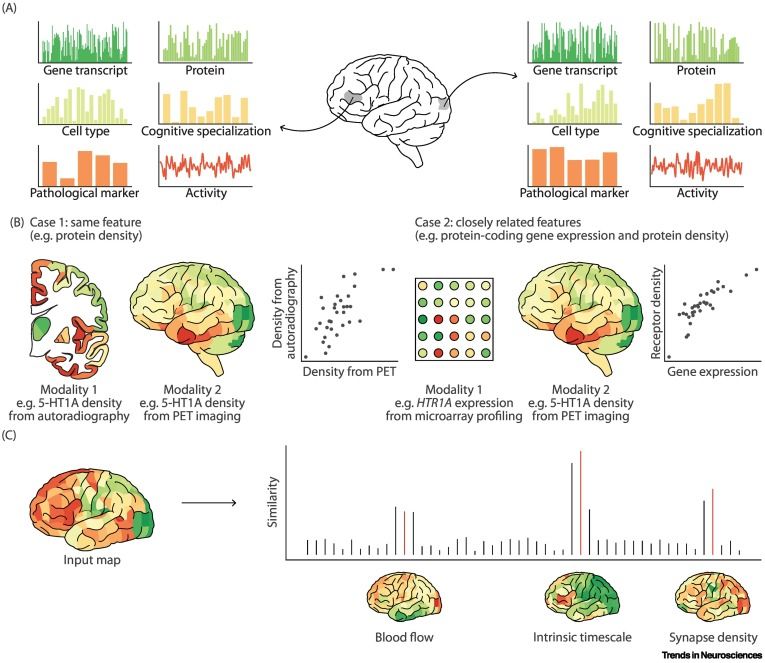
Stuart Oldham
@stuartoldham.bsky.social
· May 28
Reposted by Adeel Razi


Adeel Razi
@adeelrazi.bsky.social
· May 27

Training Binary Neural Networks using the Bayesian Learning Rule
Neural networks with binary weights are computation-efficient and hardware-friendly, but their training is challenging because it involves a discrete optimization problem. Surprisingly, ignoring the d...
arxiv.org
Adeel Razi
@adeelrazi.bsky.social
· May 27
Adeel Razi
@adeelrazi.bsky.social
· May 27
Adeel Razi
@adeelrazi.bsky.social
· May 26
Adeel Razi
@adeelrazi.bsky.social
· May 26
A Principled Bayesian Framework for Training Binary and Spiking Neural Networks
We propose a Bayesian framework for training binary and spiking neural networks that achieves state-of-the-art performance without normalisation layers. Unlike commonly used surrogate gradient methods...
arxiv.org
Adeel Razi
@adeelrazi.bsky.social
· May 26
Adeel Razi
@adeelrazi.bsky.social
· May 26
Adeel Razi
@adeelrazi.bsky.social
· May 26
Adeel Razi
@adeelrazi.bsky.social
· May 26
Adeel Razi
@adeelrazi.bsky.social
· May 26
A Principled Bayesian Framework for Training Binary and Spiking Neural Networks
We propose a Bayesian framework for training binary and spiking neural networks that achieves state-of-the-art performance without normalisation layers. Unlike commonly used surrogate gradient methods...
arxiv.org
Adeel Razi
@adeelrazi.bsky.social
· May 25
Adeel Razi
@adeelrazi.bsky.social
· May 25
Adeel Razi
@adeelrazi.bsky.social
· May 25
Adeel Razi
@adeelrazi.bsky.social
· May 15