



Nikolai Rozanov
@ai-nikolai.bsky.social
CS. PhD Candidate in LLM Agents @ImperialCollegeLondon || ex tech-founder nikolairozanov.com
Pinned
Nikolai Rozanov
@ai-nikolai.bsky.social
· Nov 20

StateAct: State Tracking and Reasoning for Acting and Planning with Large Language Models
Planning and acting to solve `real' tasks using large language models (LLMs) in interactive environments has become a new frontier for AI methods. While recent advances allowed LLMs to interact with o...
arxiv.org
Quick intro to myself.
I am a CS PhD in LLM Agents @imperial-nlp.bsky.social with @marekrei.bsky.social.
This is our latest work on LLM Agents:
StateAct: arxiv.org/abs/2410.02810 (outperforming ReAct by ~10%).
Feel free to reach out for collaboration.
I am a CS PhD in LLM Agents @imperial-nlp.bsky.social with @marekrei.bsky.social.
This is our latest work on LLM Agents:
StateAct: arxiv.org/abs/2410.02810 (outperforming ReAct by ~10%).
Feel free to reach out for collaboration.
Reposted by Nikolai Rozanov

Do LLMs need rationales for learning from mistakes? 🤔
When LLMs learn from previous incorrect answers, they typically observe corrective feedback in the form of rationales explaining each mistake. In our new preprint, we find these rationales do not help, in fact they hurt performance!
🧵
When LLMs learn from previous incorrect answers, they typically observe corrective feedback in the form of rationales explaining each mistake. In our new preprint, we find these rationales do not help, in fact they hurt performance!
🧵

February 13, 2025 at 3:38 PM
Do LLMs need rationales for learning from mistakes? 🤔
When LLMs learn from previous incorrect answers, they typically observe corrective feedback in the form of rationales explaining each mistake. In our new preprint, we find these rationales do not help, in fact they hurt performance!
🧵
When LLMs learn from previous incorrect answers, they typically observe corrective feedback in the form of rationales explaining each mistake. In our new preprint, we find these rationales do not help, in fact they hurt performance!
🧵
Reposted by Nikolai Rozanov

Not that you need another thread on Deepseek's R1, but I really enjoy these models, and it's great to see an *open*, MIT-licensed reasoner that's ~as good as OpenAI o1.
A blog post: itcanthink.substack.com/p/deepseek-r...
It's really very good at ARC-AGI for example:
A blog post: itcanthink.substack.com/p/deepseek-r...
It's really very good at ARC-AGI for example:
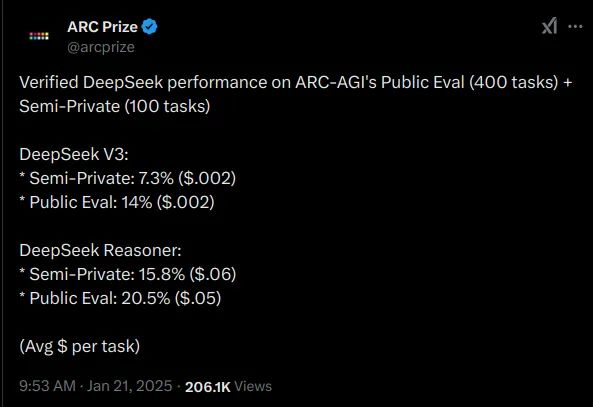
January 22, 2025 at 10:01 PM
Not that you need another thread on Deepseek's R1, but I really enjoy these models, and it's great to see an *open*, MIT-licensed reasoner that's ~as good as OpenAI o1.
A blog post: itcanthink.substack.com/p/deepseek-r...
It's really very good at ARC-AGI for example:
A blog post: itcanthink.substack.com/p/deepseek-r...
It's really very good at ARC-AGI for example:
Reposted by Nikolai Rozanov

LLM360 gets way less recognition relative to the quality of their totally open outputs in the last year+. They dropped a 60+ page technical report last week and I don't know if I saw anyone talking about it. Along with OLMo, it's the other up to date open-source LM.
Paper: https://buff.ly/40I6s4d
Paper: https://buff.ly/40I6s4d

January 23, 2025 at 2:37 AM
LLM360 gets way less recognition relative to the quality of their totally open outputs in the last year+. They dropped a 60+ page technical report last week and I don't know if I saw anyone talking about it. Along with OLMo, it's the other up to date open-source LM.
Paper: https://buff.ly/40I6s4d
Paper: https://buff.ly/40I6s4d
Reposted by Nikolai Rozanov
#NLP #LLMAgents Community, I have a question:
I have been running Webshop with older GPTs, e.g. gpt-3.5-turbo-1106 / -0125 / -instruct). On 5 different code repos (ReAct, Reflexion, ADaPT, StateAct) I am getting scores of 0%, while previously the scores where at ~15%.
Any thoughts anyone?
I have been running Webshop with older GPTs, e.g. gpt-3.5-turbo-1106 / -0125 / -instruct). On 5 different code repos (ReAct, Reflexion, ADaPT, StateAct) I am getting scores of 0%, while previously the scores where at ~15%.
Any thoughts anyone?
January 21, 2025 at 10:36 AM
#NLP #LLMAgents Community, I have a question:
I have been running Webshop with older GPTs, e.g. gpt-3.5-turbo-1106 / -0125 / -instruct). On 5 different code repos (ReAct, Reflexion, ADaPT, StateAct) I am getting scores of 0%, while previously the scores where at ~15%.
Any thoughts anyone?
I have been running Webshop with older GPTs, e.g. gpt-3.5-turbo-1106 / -0125 / -instruct). On 5 different code repos (ReAct, Reflexion, ADaPT, StateAct) I am getting scores of 0%, while previously the scores where at ~15%.
Any thoughts anyone?
#NLP #LLMAgents Community, I have a question:
I have been running Webshop with older GPTs, e.g. gpt-3.5-turbo-1106 / -0125 / -instruct). On 5 different code repos (ReAct, Reflexion, ADaPT, StateAct) I am getting scores of 0%, while previously the scores where at ~15%.
Any thoughts anyone?
I have been running Webshop with older GPTs, e.g. gpt-3.5-turbo-1106 / -0125 / -instruct). On 5 different code repos (ReAct, Reflexion, ADaPT, StateAct) I am getting scores of 0%, while previously the scores where at ~15%.
Any thoughts anyone?
January 21, 2025 at 10:36 AM
#NLP #LLMAgents Community, I have a question:
I have been running Webshop with older GPTs, e.g. gpt-3.5-turbo-1106 / -0125 / -instruct). On 5 different code repos (ReAct, Reflexion, ADaPT, StateAct) I am getting scores of 0%, while previously the scores where at ~15%.
Any thoughts anyone?
I have been running Webshop with older GPTs, e.g. gpt-3.5-turbo-1106 / -0125 / -instruct). On 5 different code repos (ReAct, Reflexion, ADaPT, StateAct) I am getting scores of 0%, while previously the scores where at ~15%.
Any thoughts anyone?
Reposted by Nikolai Rozanov

Posting a call for help: does anyone know of a good way to simultaneously treat both POTS and Ménière’s disease? Please contact me if you’re either a clinician with experience doing this or a patient who has found a good solution. Context in thread
November 24, 2024 at 4:34 PM
Posting a call for help: does anyone know of a good way to simultaneously treat both POTS and Ménière’s disease? Please contact me if you’re either a clinician with experience doing this or a patient who has found a good solution. Context in thread
Reposted by Nikolai Rozanov

Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
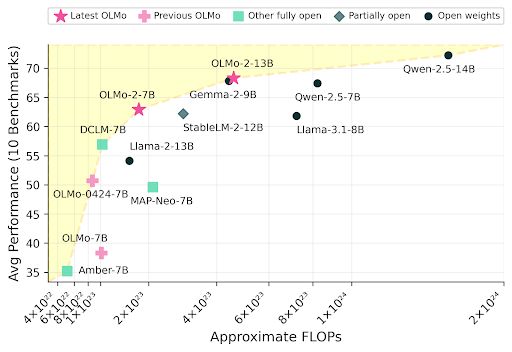
November 26, 2024 at 8:51 PM
Meet OLMo 2, the best fully open language model to date, including a family of 7B and 13B models trained up to 5T tokens. OLMo 2 outperforms other fully open models and competes with open-weight models like Llama 3.1 8B — As always, we released our data, code, recipes and more 🎁
Pretty cool people are being added to the LLM Agent & LLM Reasoning group. Thanks @lisaalaz.bsky.social for suggesting @jhamrick.bsky.social @gabepsilon.bsky.social and others.
Feel free to mention yourself and others. :)
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
Feel free to mention yourself and others. :)
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
November 23, 2024 at 7:36 PM
Pretty cool people are being added to the LLM Agent & LLM Reasoning group. Thanks @lisaalaz.bsky.social for suggesting @jhamrick.bsky.social @gabepsilon.bsky.social and others.
Feel free to mention yourself and others. :)
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
Feel free to mention yourself and others. :)
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
Reposted by Nikolai Rozanov

#EMNLP2024 was a fun time to reconnect with old friends and meet new ones! Reflecting on the conference program and in-person discussions, I believe we're seeing the "Google Moment" to #IR research play out in #NLProc.
1/n
1/n

November 21, 2024 at 1:38 PM
#EMNLP2024 was a fun time to reconnect with old friends and meet new ones! Reflecting on the conference program and in-person discussions, I believe we're seeing the "Google Moment" to #IR research play out in #NLProc.
1/n
1/n
Reposted by Nikolai Rozanov
I thought to create a Starter Pack for people working on LLM Agents. Please feel free to self-refer as well.
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
November 20, 2024 at 2:08 PM
I thought to create a Starter Pack for people working on LLM Agents. Please feel free to self-refer as well.
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
I thought to create a Starter Pack for people working on LLM Agents. Please feel free to self-refer as well.
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
November 20, 2024 at 2:08 PM
I thought to create a Starter Pack for people working on LLM Agents. Please feel free to self-refer as well.
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
Reposted by Nikolai Rozanov
Hi Bluesky, would like to introduce myself 🙂
I am PhD-ing at Imperial College under @marekrei.bsky.social’s supervision. I am broadly interested in LLM/LVLM reasoning & planning 🤖 (here’s our latest work arxiv.org/abs/2411.04535)
Do reach out if you are interested in these (or related) topics!
I am PhD-ing at Imperial College under @marekrei.bsky.social’s supervision. I am broadly interested in LLM/LVLM reasoning & planning 🤖 (here’s our latest work arxiv.org/abs/2411.04535)
Do reach out if you are interested in these (or related) topics!

Meta-Reasoning Improves Tool Use in Large Language Models
External tools help large language models (LLMs) succeed at tasks where they would otherwise typically fail. In existing frameworks, LLMs learn tool use either by in-context demonstrations or via full...
arxiv.org
November 20, 2024 at 11:26 AM
Hi Bluesky, would like to introduce myself 🙂
I am PhD-ing at Imperial College under @marekrei.bsky.social’s supervision. I am broadly interested in LLM/LVLM reasoning & planning 🤖 (here’s our latest work arxiv.org/abs/2411.04535)
Do reach out if you are interested in these (or related) topics!
I am PhD-ing at Imperial College under @marekrei.bsky.social’s supervision. I am broadly interested in LLM/LVLM reasoning & planning 🤖 (here’s our latest work arxiv.org/abs/2411.04535)
Do reach out if you are interested in these (or related) topics!
Quick intro to myself.
I am a CS PhD in LLM Agents @imperial-nlp.bsky.social with @marekrei.bsky.social.
This is our latest work on LLM Agents:
StateAct: arxiv.org/abs/2410.02810 (outperforming ReAct by ~10%).
Feel free to reach out for collaboration.
I am a CS PhD in LLM Agents @imperial-nlp.bsky.social with @marekrei.bsky.social.
This is our latest work on LLM Agents:
StateAct: arxiv.org/abs/2410.02810 (outperforming ReAct by ~10%).
Feel free to reach out for collaboration.
StateAct: State Tracking and Reasoning for Acting and Planning with Large Language Models
Planning and acting to solve `real' tasks using large language models (LLMs) in interactive environments has become a new frontier for AI methods. While recent advances allowed LLMs to interact with o...
arxiv.org
November 20, 2024 at 10:35 AM
Quick intro to myself.
I am a CS PhD in LLM Agents @imperial-nlp.bsky.social with @marekrei.bsky.social.
This is our latest work on LLM Agents:
StateAct: arxiv.org/abs/2410.02810 (outperforming ReAct by ~10%).
Feel free to reach out for collaboration.
I am a CS PhD in LLM Agents @imperial-nlp.bsky.social with @marekrei.bsky.social.
This is our latest work on LLM Agents:
StateAct: arxiv.org/abs/2410.02810 (outperforming ReAct by ~10%).
Feel free to reach out for collaboration.
Reposted by Nikolai Rozanov

Welcome to Bluesky to more of our NLP researchers at Imperial!! Looking forward to following everyone's work on here.
To follow us all click 'follow all' in the starter pack below
go.bsky.app/Bv5thAb
To follow us all click 'follow all' in the starter pack below
go.bsky.app/Bv5thAb
November 20, 2024 at 8:35 AM
Welcome to Bluesky to more of our NLP researchers at Imperial!! Looking forward to following everyone's work on here.
To follow us all click 'follow all' in the starter pack below
go.bsky.app/Bv5thAb
To follow us all click 'follow all' in the starter pack below
go.bsky.app/Bv5thAb