




Alicia Curth
@aliciacurth.bsky.social
Machine Learner by day, 🦮 Statistician at ❤️
In search of statistical intuition for modern ML & simple explanations for complex things👀
Interested in the mysteries of modern ML, causality & all of stats. Opinions my own.
https://aliciacurth.github.io
In search of statistical intuition for modern ML & simple explanations for complex things👀
Interested in the mysteries of modern ML, causality & all of stats. Opinions my own.
https://aliciacurth.github.io
Honestly hurts my feelings a little that I didn’t even make this list 🥲🥲
November 22, 2024 at 9:12 PM
Honestly hurts my feelings a little that I didn’t even make this list 🥲🥲
This is what I came to this app for 🦮
November 21, 2024 at 4:56 PM
This is what I came to this app for 🦮
Thank you for sharing!! Sounds super interesting, so will definitely check it out :)
November 21, 2024 at 3:58 PM
Thank you for sharing!! Sounds super interesting, so will definitely check it out :)
Exactly this!! thank you 🤗
November 21, 2024 at 1:47 PM
Exactly this!! thank you 🤗
Oh exciting! On which one? :)
November 21, 2024 at 10:21 AM
Oh exciting! On which one? :)
To be fair, it’s actually a really really good TLDR!! I’m honestly just a little scared this will end up on the wrong side of twitter now 😳
November 21, 2024 at 10:21 AM
To be fair, it’s actually a really really good TLDR!! I’m honestly just a little scared this will end up on the wrong side of twitter now 😳
Reposted by Alicia Curth
Now might be the worst possible point in time to admit that I don’t own a physical copy of the book myself (yet!! I’m actually building up a textbook bookshelf for myself) BUT because Hastie, Tibshirani & Friedman are the GOATs that they are, they made the pdf free: hastie.su.domains/ElemStatLearn/
Elements of Statistical Learning: data mining, inference, and prediction. 2nd Edition.
hastie.su.domains
November 21, 2024 at 9:27 AM
Now might be the worst possible point in time to admit that I don’t own a physical copy of the book myself (yet!! I’m actually building up a textbook bookshelf for myself) BUT because Hastie, Tibshirani & Friedman are the GOATs that they are, they made the pdf free: hastie.su.domains/ElemStatLearn/
Now might be the worst possible point in time to admit that I don’t own a physical copy of the book myself (yet!! I’m actually building up a textbook bookshelf for myself) BUT because Hastie, Tibshirani & Friedman are the GOATs that they are, they made the pdf free: hastie.su.domains/ElemStatLearn/
Elements of Statistical Learning: data mining, inference, and prediction. 2nd Edition.
hastie.su.domains
November 21, 2024 at 9:27 AM
Now might be the worst possible point in time to admit that I don’t own a physical copy of the book myself (yet!! I’m actually building up a textbook bookshelf for myself) BUT because Hastie, Tibshirani & Friedman are the GOATs that they are, they made the pdf free: hastie.su.domains/ElemStatLearn/
Now continued below with case study 2: understanding performance differences of neural networks and gradient boosted trees on irregular tabular data!!
Part 2: Why do boosted trees outperform deep learning on tabular data??
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n
@alanjeffares.bsky.social & I suspected that answers to this are obfuscated by the 2 being considered very different algs🤔
Instead we show they are more similar than you’d think — making their diffs smaller but predictive!🧵1/n

November 20, 2024 at 9:12 PM
Now continued below with case study 2: understanding performance differences of neural networks and gradient boosted trees on irregular tabular data!!
There’s one more case study & thoughts on the effect of design choices on function updates left— I’ll cover that in a final thread! (next week, giving us all a break😅)
Until then, find the paper here arxiv.org/abs/2411.00247
and/or recap part 1 of this thread below! 🤗 14/14
Until then, find the paper here arxiv.org/abs/2411.00247
and/or recap part 1 of this thread below! 🤗 14/14
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
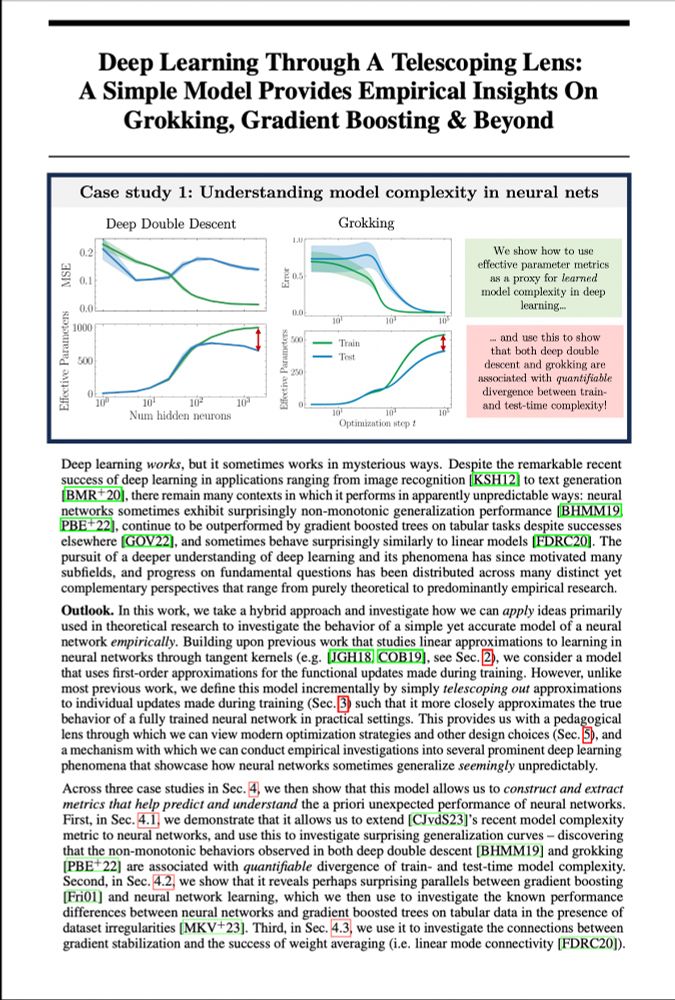
November 20, 2024 at 5:02 PM
There’s one more case study & thoughts on the effect of design choices on function updates left— I’ll cover that in a final thread! (next week, giving us all a break😅)
Until then, find the paper here arxiv.org/abs/2411.00247
and/or recap part 1 of this thread below! 🤗 14/14
Until then, find the paper here arxiv.org/abs/2411.00247
and/or recap part 1 of this thread below! 🤗 14/14
Thus in conclusion this 2nd case study showed that the telescoping approximation of a trained neural network can be a useful lens to investigate performance diffs with other methods!
Here we used it to show how some perf diffs are predicted by specific model diffs(ie diffs in implied kernels)💡13/n
Here we used it to show how some perf diffs are predicted by specific model diffs(ie diffs in implied kernels)💡13/n
November 20, 2024 at 5:02 PM
Thus in conclusion this 2nd case study showed that the telescoping approximation of a trained neural network can be a useful lens to investigate performance diffs with other methods!
Here we used it to show how some perf diffs are predicted by specific model diffs(ie diffs in implied kernels)💡13/n
Here we used it to show how some perf diffs are predicted by specific model diffs(ie diffs in implied kernels)💡13/n
Importantly, this growth in performance gap is tracked by the behaviour of the models’ kernels:
while there is no difference in kernel weights for GBTs across different input irregularity levels, the neural net’s kernel weights for the most irregular ex grow more extreme! 12/n
while there is no difference in kernel weights for GBTs across different input irregularity levels, the neural net’s kernel weights for the most irregular ex grow more extreme! 12/n

November 20, 2024 at 5:02 PM
Importantly, this growth in performance gap is tracked by the behaviour of the models’ kernels:
while there is no difference in kernel weights for GBTs across different input irregularity levels, the neural net’s kernel weights for the most irregular ex grow more extreme! 12/n
while there is no difference in kernel weights for GBTs across different input irregularity levels, the neural net’s kernel weights for the most irregular ex grow more extreme! 12/n
We test this hypothesis by varying the proportion of irregular inputs in the testset for fixed trained models.
We find that GBTs outperform NNs already in the absence of irregular ex; this speaks to diff in baseline suitability
The performance gap then indeed grows as we increase irregularity!11/n
We find that GBTs outperform NNs already in the absence of irregular ex; this speaks to diff in baseline suitability
The performance gap then indeed grows as we increase irregularity!11/n

November 20, 2024 at 5:02 PM
We test this hypothesis by varying the proportion of irregular inputs in the testset for fixed trained models.
We find that GBTs outperform NNs already in the absence of irregular ex; this speaks to diff in baseline suitability
The performance gap then indeed grows as we increase irregularity!11/n
We find that GBTs outperform NNs already in the absence of irregular ex; this speaks to diff in baseline suitability
The performance gap then indeed grows as we increase irregularity!11/n
This highlights a potential explanation why GBTs outperform neural nets on tabular data in the presence of input irregularities:
The kernels implied by the neural network might behave much much more unpredictably for test inputs different to inputs observed at train time! 💡🤔10/n
The kernels implied by the neural network might behave much much more unpredictably for test inputs different to inputs observed at train time! 💡🤔10/n
November 20, 2024 at 5:02 PM
This highlights a potential explanation why GBTs outperform neural nets on tabular data in the presence of input irregularities:
The kernels implied by the neural network might behave much much more unpredictably for test inputs different to inputs observed at train time! 💡🤔10/n
The kernels implied by the neural network might behave much much more unpredictably for test inputs different to inputs observed at train time! 💡🤔10/n
Trees issue preds that are proper averages: all kernel weights are between 0 & 1. That is: trees never “extrapolate” from the convex hull of training observations 💡
Neural net tangent kernels OTOH are generally unbounded and could take on very different vals for unseen test inputs!😰 9/n
Neural net tangent kernels OTOH are generally unbounded and could take on very different vals for unseen test inputs!😰 9/n

November 20, 2024 at 5:02 PM
Trees issue preds that are proper averages: all kernel weights are between 0 & 1. That is: trees never “extrapolate” from the convex hull of training observations 💡
Neural net tangent kernels OTOH are generally unbounded and could take on very different vals for unseen test inputs!😰 9/n
Neural net tangent kernels OTOH are generally unbounded and could take on very different vals for unseen test inputs!😰 9/n
One diff is obvious and purely architectural: either kernel might be able to better fit a particular underlying outcome generating process!
A second diff is a lot more subtle and relates to how regular (or: predictable) the two will likely behave on new data: … 8/n
A second diff is a lot more subtle and relates to how regular (or: predictable) the two will likely behave on new data: … 8/n

November 20, 2024 at 5:02 PM
One diff is obvious and purely architectural: either kernel might be able to better fit a particular underlying outcome generating process!
A second diff is a lot more subtle and relates to how regular (or: predictable) the two will likely behave on new data: … 8/n
A second diff is a lot more subtle and relates to how regular (or: predictable) the two will likely behave on new data: … 8/n
but WAIT A MINUTE — isn’t that literally the same formula as the kernel representation of the telescoping model of a trained neural network I showed you before?? Just with a different kernel??
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n

November 20, 2024 at 5:02 PM
but WAIT A MINUTE — isn’t that literally the same formula as the kernel representation of the telescoping model of a trained neural network I showed you before?? Just with a different kernel??
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n
Surely this diff in kernel must account for at least some of the observed performance differences… 🤔7/n
Gradient boosted trees (aka OG gradient boosting) simply implement this process using trees!
From our previous work on random forests(arxiv.org/abs/2402.01502) we know we can interpret trees as adaptive kernel smoothers, so we can rewrite the GBT preds as weighted avgs over training loss grads!6/n
From our previous work on random forests(arxiv.org/abs/2402.01502) we know we can interpret trees as adaptive kernel smoothers, so we can rewrite the GBT preds as weighted avgs over training loss grads!6/n

November 20, 2024 at 5:02 PM
Gradient boosted trees (aka OG gradient boosting) simply implement this process using trees!
From our previous work on random forests(arxiv.org/abs/2402.01502) we know we can interpret trees as adaptive kernel smoothers, so we can rewrite the GBT preds as weighted avgs over training loss grads!6/n
From our previous work on random forests(arxiv.org/abs/2402.01502) we know we can interpret trees as adaptive kernel smoothers, so we can rewrite the GBT preds as weighted avgs over training loss grads!6/n
Quick refresher: what is gradient boosting?
Not to be confused with other forms of boosting (eg Adaboost), *Gradient* boosting fits a sequence of weak learners that execute steepest descent in function space directly by learning to predict the loss gradients of training examples! 5/n
Not to be confused with other forms of boosting (eg Adaboost), *Gradient* boosting fits a sequence of weak learners that execute steepest descent in function space directly by learning to predict the loss gradients of training examples! 5/n

November 20, 2024 at 5:02 PM
Quick refresher: what is gradient boosting?
Not to be confused with other forms of boosting (eg Adaboost), *Gradient* boosting fits a sequence of weak learners that execute steepest descent in function space directly by learning to predict the loss gradients of training examples! 5/n
Not to be confused with other forms of boosting (eg Adaboost), *Gradient* boosting fits a sequence of weak learners that execute steepest descent in function space directly by learning to predict the loss gradients of training examples! 5/n
In arxiv.org/abs/2411.00247 we ask: why? What distinguishes gradient boosted trees from deep learning that would explain this?
A first reaction might be “they are SO different idk where to start 😭” — BUT we show that through the telescoping lens (see part 1 of this🧵⬇️) things become more clear..4/n
A first reaction might be “they are SO different idk where to start 😭” — BUT we show that through the telescoping lens (see part 1 of this🧵⬇️) things become more clear..4/n
We exploit that you can express preds of a trained network as a telescoping sum over all training steps💡
For a single step changes are small,so we can better linearly approximate individual steps sequentially(instead of the whole trajectory at once)
➡️ We refer to this as ✨telescoping approx✨!6/n
For a single step changes are small,so we can better linearly approximate individual steps sequentially(instead of the whole trajectory at once)
➡️ We refer to this as ✨telescoping approx✨!6/n

November 20, 2024 at 5:02 PM
In arxiv.org/abs/2411.00247 we ask: why? What distinguishes gradient boosted trees from deep learning that would explain this?
A first reaction might be “they are SO different idk where to start 😭” — BUT we show that through the telescoping lens (see part 1 of this🧵⬇️) things become more clear..4/n
A first reaction might be “they are SO different idk where to start 😭” — BUT we show that through the telescoping lens (see part 1 of this🧵⬇️) things become more clear..4/n
And you know who continues to rule the tabular benchmarks? Gradient boosted trees (GBTs)!!(or their descendants)
While the severity of the perf gap over neural nets is disputed, arxiv.org/abs/2305.02997 still found as recently as last year that GBTs esp outperform when data is irregular! 3/n
While the severity of the perf gap over neural nets is disputed, arxiv.org/abs/2305.02997 still found as recently as last year that GBTs esp outperform when data is irregular! 3/n

November 20, 2024 at 5:02 PM
And you know who continues to rule the tabular benchmarks? Gradient boosted trees (GBTs)!!(or their descendants)
While the severity of the perf gap over neural nets is disputed, arxiv.org/abs/2305.02997 still found as recently as last year that GBTs esp outperform when data is irregular! 3/n
While the severity of the perf gap over neural nets is disputed, arxiv.org/abs/2305.02997 still found as recently as last year that GBTs esp outperform when data is irregular! 3/n
First things first, why do we care about tabular?
Deep learning sometimes seems to forget we used to do data formats that weren’t text or image (😉) BUT in data science applications — from medicine to marketing and econ — tabular data still rules big parts of the world!!
2/n
Deep learning sometimes seems to forget we used to do data formats that weren’t text or image (😉) BUT in data science applications — from medicine to marketing and econ — tabular data still rules big parts of the world!!
2/n
November 20, 2024 at 5:02 PM
First things first, why do we care about tabular?
Deep learning sometimes seems to forget we used to do data formats that weren’t text or image (😉) BUT in data science applications — from medicine to marketing and econ — tabular data still rules big parts of the world!!
2/n
Deep learning sometimes seems to forget we used to do data formats that weren’t text or image (😉) BUT in data science applications — from medicine to marketing and econ — tabular data still rules big parts of the world!!
2/n