Aaron Mueller
@amuuueller.bsky.social
2.3K followers
330 following
36 posts
Postdoc at Northeastern and incoming Asst. Prof. at Boston U. Working on NLP, interpretability, causality. Previously: JHU, Meta, AWS
Posts
Media
Videos
Starter Packs



Reposted by Aaron Mueller

![What do representations tell us about a system? Image of a mouse with a scope showing a vector of activity patterns, and a neural network with a vector of unit activity patterns
Common analyses of neural representations: Encoding models (relating activity to task features) drawing of an arrow from a trace saying [on_____on____] to a neuron and spike train. Comparing models via neural predictivity: comparing two neural networks by their R^2 to mouse brain activity. RSA: assessing brain-brain or model-brain correspondence using representational dissimilarity matrices](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:e6ewzleebkdi2y2bxhjxoknt/bafkreiav2io2ska33o4kizf57co5bboqyyfdpnozo2gxsicrfr5l7qzjcq@jpeg)


Reposted by Aaron Mueller
David Bau
@davidbau.bsky.social
· Jun 25

@nikhil07prakash.bsky.social
How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
bsky.app
Aaron Mueller
@amuuueller.bsky.social
· May 27
Aaron Mueller
@amuuueller.bsky.social
· May 27
Aaron Mueller
@amuuueller.bsky.social
· May 27

Reposted by Aaron Mueller

Reposted by Aaron Mueller

Aaron Mueller
@amuuueller.bsky.social
· Apr 23
Aaron Mueller
@amuuueller.bsky.social
· Apr 23
Aaron Mueller
@amuuueller.bsky.social
· Apr 23

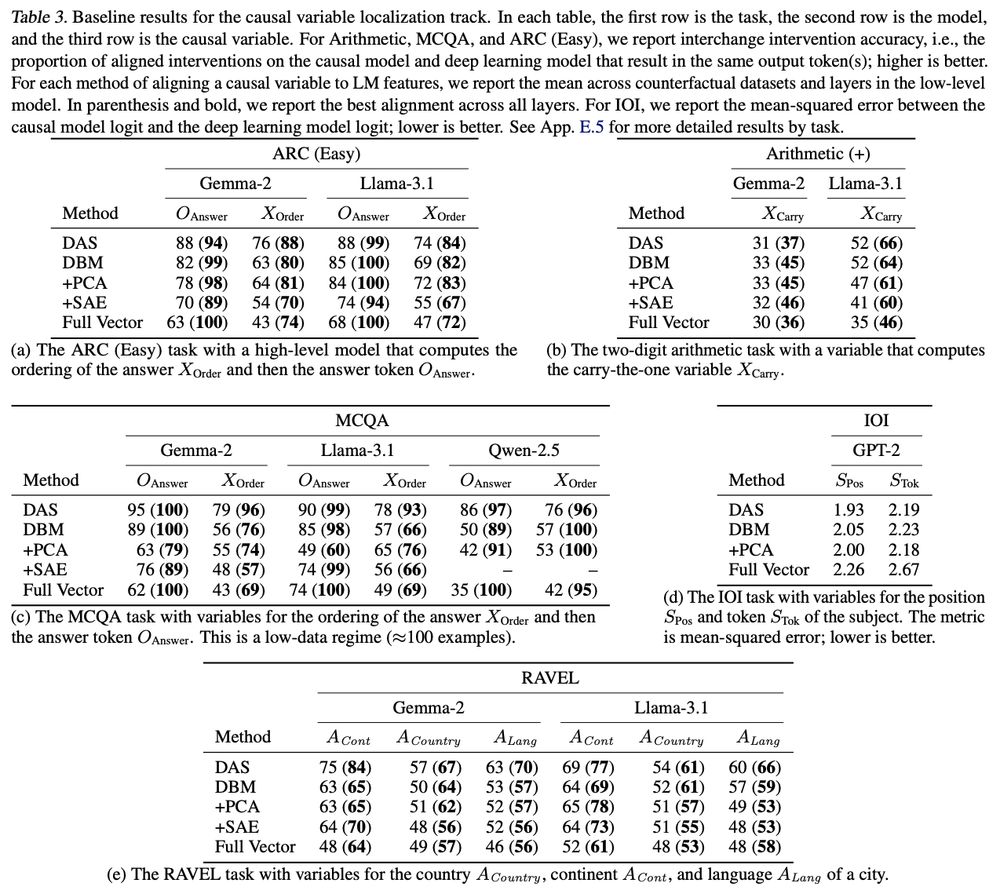
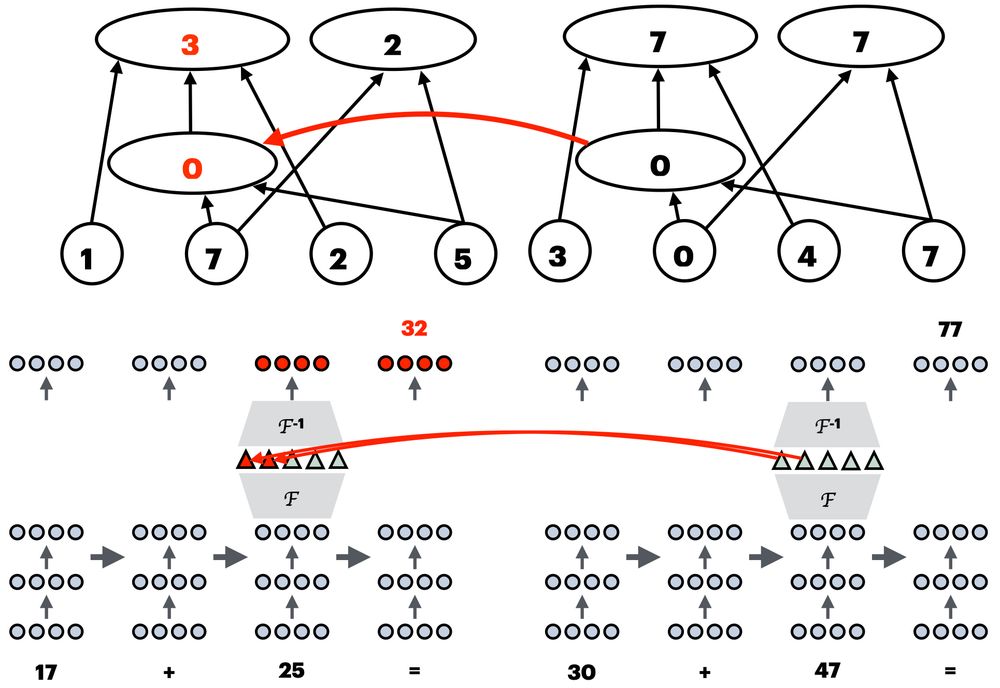
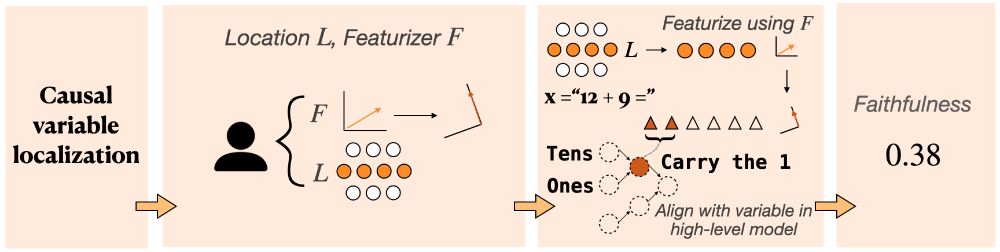
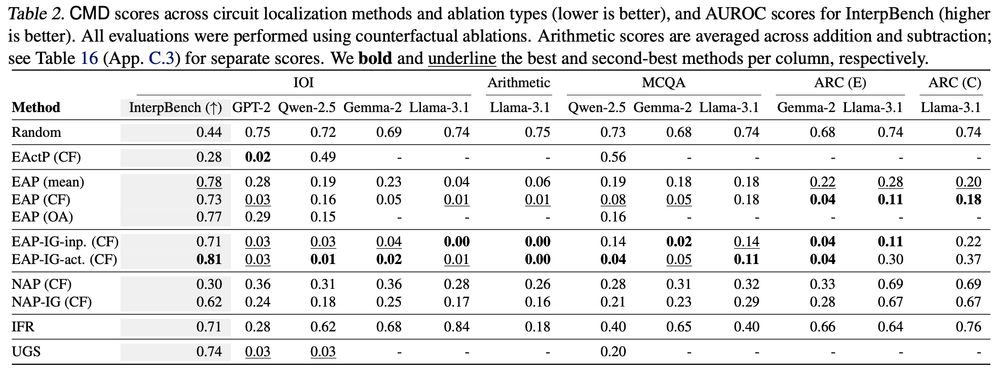
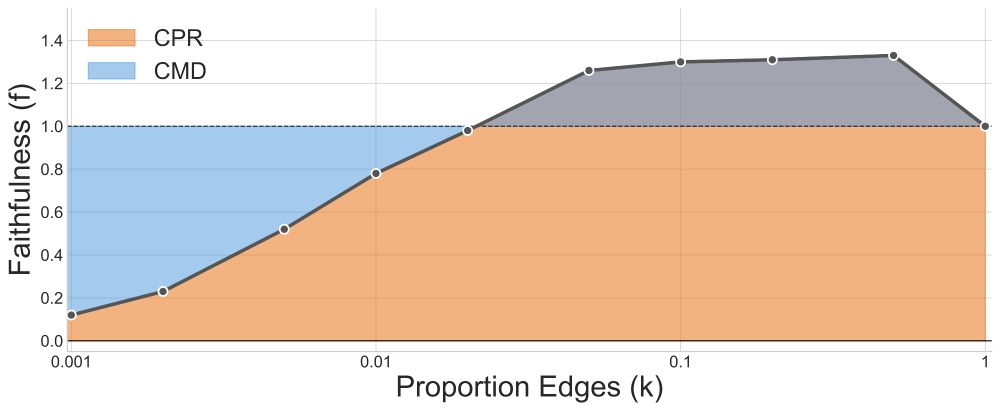
MIB: A Mechanistic Interpretability Benchmark
How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spann...
arxiv.org
Aaron Mueller
@amuuueller.bsky.social
· Apr 23