
Arkadiy Saakyan
@asaakyan.bsky.social
400 followers
200 following
6 posts
PhD student at Columbia University working on human-AI collaboration, AI creativity and explainability. prev. intern @GoogleDeepMind, @AmazonScience
asaakyan.github.io
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Arkadiy Saakyan


Arkadiy Saakyan
@asaakyan.bsky.social
· May 1

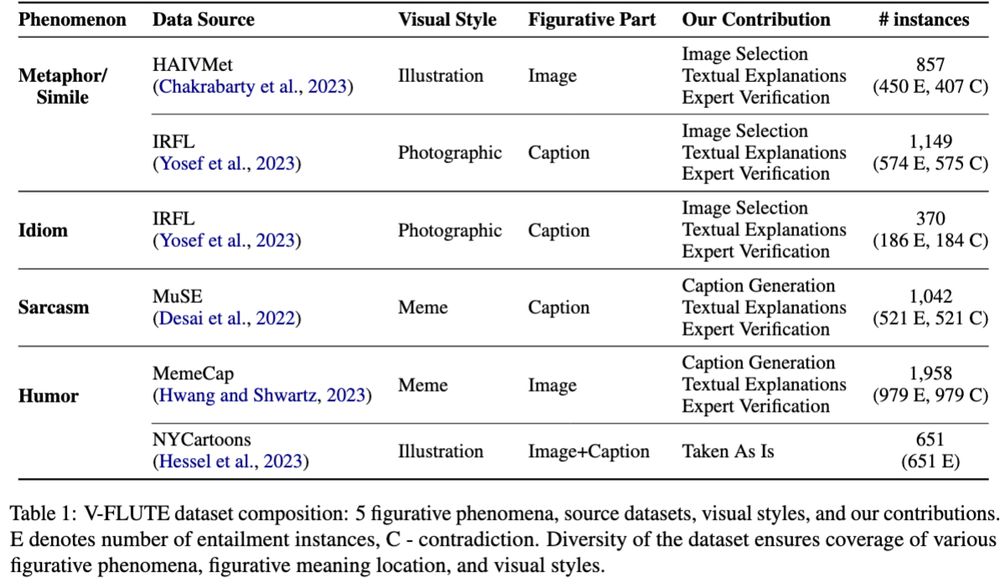
Understanding Figurative Meaning through Explainable Visual Entailment
Large Vision-Language Models (VLMs) have demonstrated strong capabilities in tasks requiring a fine-grained understanding of literal meaning in images and text, such as visual question-answering or vi...
arxiv.org



Reposted by Arkadiy Saakyan

Reposted by Arkadiy Saakyan

