Ben Prystawski
@benpry.bsky.social
830 followers
360 following
5 posts
Cognitive science PhD student at Stanford, studying iterated learning and reasoning.
Posts
Media
Videos
Starter Packs
Reposted by Ben Prystawski

Reposted by Ben Prystawski


Reposted by Ben Prystawski

Reposted by Ben Prystawski

![What do representations tell us about a system? Image of a mouse with a scope showing a vector of activity patterns, and a neural network with a vector of unit activity patterns
Common analyses of neural representations: Encoding models (relating activity to task features) drawing of an arrow from a trace saying [on_____on____] to a neuron and spike train. Comparing models via neural predictivity: comparing two neural networks by their R^2 to mouse brain activity. RSA: assessing brain-brain or model-brain correspondence using representational dissimilarity matrices](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:e6ewzleebkdi2y2bxhjxoknt/bafkreiav2io2ska33o4kizf57co5bboqyyfdpnozo2gxsicrfr5l7qzjcq@jpeg)

Ben Prystawski
@benpry.bsky.social
· Aug 1

Idiosyncratic but not opaque: Linguistic conventions formed in reference games are interpretable by naïve humans and vision–language models
Author(s): Boyce, Veronica; Prystawski, Ben; Tan, Alvin Wei Ming; Frank, Michael C. | Abstract: When are in-group linguistic conventions opaque to non-group members (teen slang like "rizz") or general...
escholarship.org

Ben Prystawski
@benpry.bsky.social
· Aug 1
Thinking fast, slow, and everywhere in between in humans and language models
Author(s): Prystawski, Ben; Goodman, Noah | Abstract: How do humans adapt how they reason to varying circumstances? Prior research has argued that reasoning comes in two types: a fast, intuitive type ...
escholarship.org
Reposted by Ben Prystawski

Reposted by Ben Prystawski

Junyi Chu
@junyi.bsky.social
· Jun 6
Reposted by Ben Prystawski


Reposted by Ben Prystawski

Reposted by Ben Prystawski


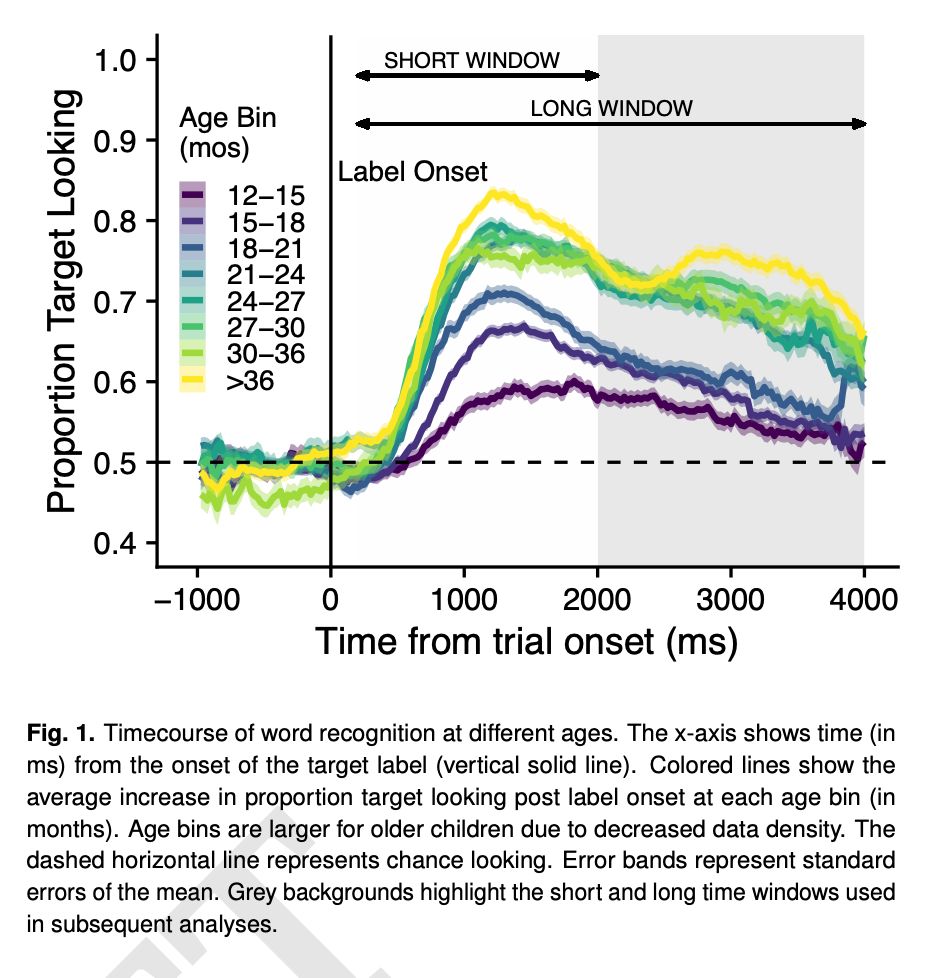
Reposted by Ben Prystawski
Reposted by Ben Prystawski
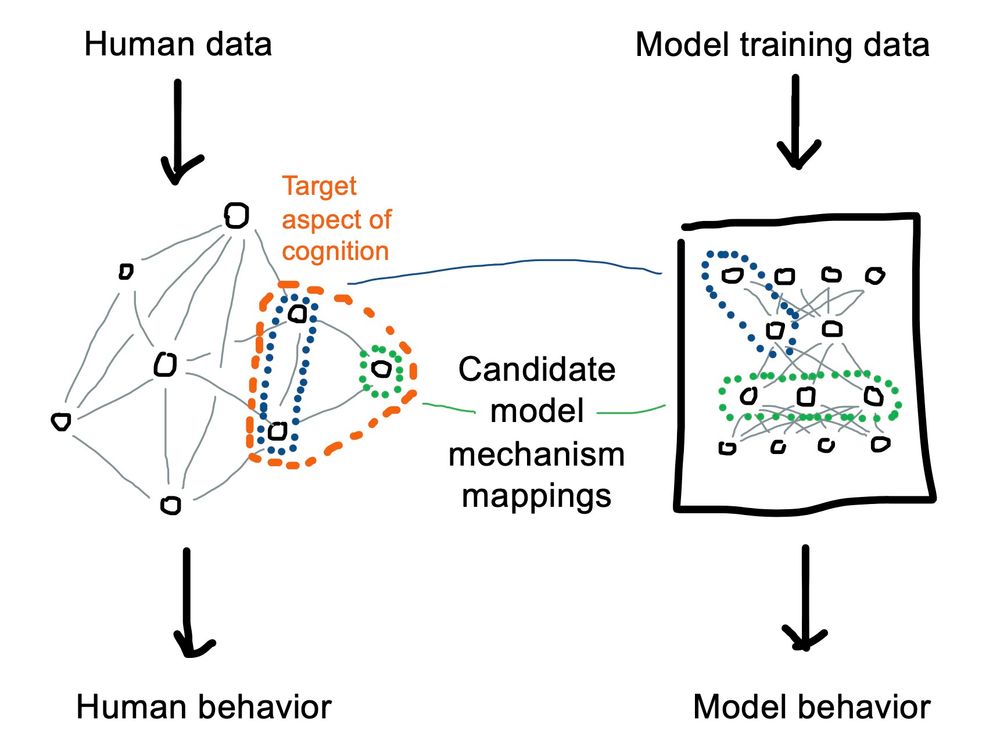
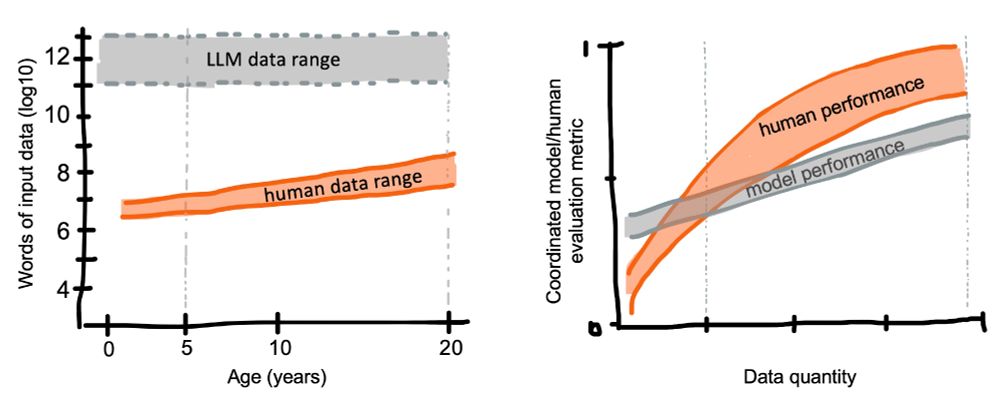

Reposted by Ben Prystawski


Reposted by Ben Prystawski


Reposted by Ben Prystawski
Andrew Lampinen
@lampinen.bsky.social
· Dec 10

The broader spectrum of in-context learning
The ability of language models to learn a task from a few examples in context has generated substantial interest. Here, we provide a perspective that situates this type of supervised few-shot learning...
arxiv.org
Ben Prystawski
@benpry.bsky.social
· Nov 23
Reposted by Ben Prystawski


Reposted by Ben Prystawski
Reposted by Ben Prystawski


Reposted by Ben Prystawski

Reposted by Ben Prystawski

