




Andrew Lampinen
@lampinen.bsky.social
Interested in cognition and artificial intelligence. Research Scientist at Google DeepMind. Previously cognitive science at Stanford. Posts are mine.
lampinen.github.io
lampinen.github.io
Pinned
Andrew Lampinen
@lampinen.bsky.social
· Sep 22

Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences
When do machine learning systems fail to generalize, and what mechanisms could improve their generalization? Here, we draw inspiration from cognitive science to argue that one weakness of machine lear...
arxiv.org
Why does AI sometimes fail to generalize, and what might help? In a new paper (arxiv.org/abs/2509.16189), we highlight the latent learning gap — which unifies findings from language modeling to agent navigation — and suggest that episodic memory complements parametric learning to bridge it. Thread:
Very important point! We've made arguments from a computational perspective that low-variance features can be computationally relevant (bsky.app/profile/lamp...), but it's much cooler to see it demonstrated on a model of real neural dynamics

“Our findings challenge the conventional focus on low-dimensional coding subspaces as a sufficient framework for understanding neural computations, demonstrating that dimensions previously considered task-irrelevant and accounting for little variance can have a critical role in driving behavior.”

Neural dynamics outside task-coding dimensions drive decision trajectories through transient amplification
Most behaviors involve neural dynamics in high-dimensional activity spaces. A common approach is to extract dimensions that capture task-related variability, such as those separating stimuli or choice...
www.biorxiv.org
November 23, 2025 at 5:05 PM
Very important point! We've made arguments from a computational perspective that low-variance features can be computationally relevant (bsky.app/profile/lamp...), but it's much cooler to see it demonstrated on a model of real neural dynamics
Great work by Andrea & co, now out with more datasets, models, and analyses!

Our paper “The cost of thinking is similar between large reasoning models and humans” is now out in PNAS! 🤖🧠
w/ @fepdelia.bsky.social, @hopekean.bsky.social, @lampinen.bsky.social, and @evfedorenko.bsky.social
Link: www.pnas.org/doi/10.1073/... (1/6)
w/ @fepdelia.bsky.social, @hopekean.bsky.social, @lampinen.bsky.social, and @evfedorenko.bsky.social
Link: www.pnas.org/doi/10.1073/... (1/6)
PNAS
Proceedings of the National Academy of Sciences (PNAS), a peer reviewed journal of the National Academy of Sciences (NAS) - an authoritative source of high-impact, original research that broadly spans...
www.pnas.org
November 20, 2025 at 1:45 PM
Great work by Andrea & co, now out with more datasets, models, and analyses!
I was honored to speak at Princeton’s symposium on The Physics of John Hopfield: Learning & Intelligence this week. I sketched out a perspective that ties together some of our recent work on ICL vs. parametric learning, and some possible links to hippocampal replay: 1/

November 15, 2025 at 8:56 PM
I was honored to speak at Princeton’s symposium on The Physics of John Hopfield: Learning & Intelligence this week. I sketched out a perspective that ties together some of our recent work on ICL vs. parametric learning, and some possible links to hippocampal replay: 1/
Reposted by Andrew Lampinen

Can't tell you how great it is to finally be able to release and talk about this work, SIMA 2, the next step toward embodied intelligence in rich, interactive 3D worlds!
deepmind.google/sima
deepmind.google/sima

SIMA 2: A Gemini-Powered AI Agent for 3D Virtual Worlds
Introducing SIMA 2, the next milestone in our research creating general and helpful AI agents. By integrating the advanced capabilities of our Gemini models, SIMA is evolving from an instruction-foll…
deepmind.google
November 13, 2025 at 3:20 PM
Can't tell you how great it is to finally be able to release and talk about this work, SIMA 2, the next step toward embodied intelligence in rich, interactive 3D worlds!
deepmind.google/sima
deepmind.google/sima
Reposted by Andrew Lampinen

Today in Nature Machine Intelligence, Kazuki Irie & I discuss 4 classic challenges for neural nets — systematic generalization, catastrophic forgetting, few-shot learning, & reasoning. We argue there is a unifying fix: the right incentives & practice. rdcu.be/eLRmg

October 20, 2025 at 1:18 PM
Today in Nature Machine Intelligence, Kazuki Irie & I discuss 4 classic challenges for neural nets — systematic generalization, catastrophic forgetting, few-shot learning, & reasoning. We argue there is a unifying fix: the right incentives & practice. rdcu.be/eLRmg
What aspects of human knowledge do vision models like CLIP fail to capture, and how can we improve them? We suggest models miss key global organization; aligning them makes them more robust. Check out LukasMuttenthaler's work, finally out (in Nature!?) www.nature.com/articles/s41... + our blog! 1/3

Aligning machine and human visual representations across abstraction levels - Nature
Aligning foundation models with human judgments enables them to more accurately approximate human behaviour and uncertainty across various levels of visual abstraction, while additionally improving th...
www.nature.com
November 12, 2025 at 4:50 PM
What aspects of human knowledge do vision models like CLIP fail to capture, and how can we improve them? We suggest models miss key global organization; aligning them makes them more robust. Check out LukasMuttenthaler's work, finally out (in Nature!?) www.nature.com/articles/s41... + our blog! 1/3
Reposted by Andrew Lampinen

New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇

November 10, 2025 at 10:11 PM
New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
Apologies for being quiet on here lately — been focusing on the more important things in life :)

November 9, 2025 at 11:34 PM
Apologies for being quiet on here lately — been focusing on the more important things in life :)
Pleased to share that our survey "Getting aligned on representational alignment" — on representational alignment across cognitive (neuro)science and machine learning — is now published in TMLR! openreview.net/forum?id=Hiq...
Kudos to @sucholutsky.bsky.social @lukasmut.bsky.social for leading this!
Kudos to @sucholutsky.bsky.social @lukasmut.bsky.social for leading this!
October 29, 2025 at 5:23 PM
Pleased to share that our survey "Getting aligned on representational alignment" — on representational alignment across cognitive (neuro)science and machine learning — is now published in TMLR! openreview.net/forum?id=Hiq...
Kudos to @sucholutsky.bsky.social @lukasmut.bsky.social for leading this!
Kudos to @sucholutsky.bsky.social @lukasmut.bsky.social for leading this!
Reposted by Andrew Lampinen

🚨 New preprint alert!
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3

The curriculum effect in visual learning: the role of readout dimensionality
Generalization of visual perceptual learning (VPL) to unseen conditions varies across tasks. Previous work suggests that training curriculum may be integral to generalization, yet a theoretical explan...
tinyurl.com
September 30, 2025 at 2:26 PM
🚨 New preprint alert!
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3
Why does AI sometimes fail to generalize, and what might help? In a new paper (arxiv.org/abs/2509.16189), we highlight the latent learning gap — which unifies findings from language modeling to agent navigation — and suggest that episodic memory complements parametric learning to bridge it. Thread:
Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences
When do machine learning systems fail to generalize, and what mechanisms could improve their generalization? Here, we draw inspiration from cognitive science to argue that one weakness of machine lear...
arxiv.org
September 22, 2025 at 4:21 AM
Why does AI sometimes fail to generalize, and what might help? In a new paper (arxiv.org/abs/2509.16189), we highlight the latent learning gap — which unifies findings from language modeling to agent navigation — and suggest that episodic memory complements parametric learning to bridge it. Thread:
Reposted by Andrew Lampinen

How can an imitative model like an LLM outperform the experts it is trained on? Our new COLM paper outlines three types of transcendence and shows that each one relies on a different aspect of data diversity. arxiv.org/abs/2508.17669

August 29, 2025 at 9:46 PM
How can an imitative model like an LLM outperform the experts it is trained on? Our new COLM paper outlines three types of transcendence and shows that each one relies on a different aspect of data diversity. arxiv.org/abs/2508.17669
In neuroscience, we often try to understand systems by analyzing their representations — using tools like regression or RSA. But are these analyses biased towards discovering a subset of what a system represents? If you're interested in this question, check out our new commentary! Thread:
![What do representations tell us about a system? Image of a mouse with a scope showing a vector of activity patterns, and a neural network with a vector of unit activity patterns
Common analyses of neural representations: Encoding models (relating activity to task features) drawing of an arrow from a trace saying [on_____on____] to a neuron and spike train. Comparing models via neural predictivity: comparing two neural networks by their R^2 to mouse brain activity. RSA: assessing brain-brain or model-brain correspondence using representational dissimilarity matrices](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:e6ewzleebkdi2y2bxhjxoknt/bafkreiav2io2ska33o4kizf57co5bboqyyfdpnozo2gxsicrfr5l7qzjcq@jpeg)
August 5, 2025 at 2:36 PM
In neuroscience, we often try to understand systems by analyzing their representations — using tools like regression or RSA. But are these analyses biased towards discovering a subset of what a system represents? If you're interested in this question, check out our new commentary! Thread:
Reposted by Andrew Lampinen

Get ready to enter the simulation...
Genie 3 is a new frontier for world models: its environments remain largely consistent for several minutes, with visual memory extending as far back as 1min. These limitations will only decrease with time.
Welcome to the future.🙌
deepmind.google/discover/blo...
Genie 3 is a new frontier for world models: its environments remain largely consistent for several minutes, with visual memory extending as far back as 1min. These limitations will only decrease with time.
Welcome to the future.🙌
deepmind.google/discover/blo...
August 5, 2025 at 2:10 PM
Get ready to enter the simulation...
Genie 3 is a new frontier for world models: its environments remain largely consistent for several minutes, with visual memory extending as far back as 1min. These limitations will only decrease with time.
Welcome to the future.🙌
deepmind.google/discover/blo...
Genie 3 is a new frontier for world models: its environments remain largely consistent for several minutes, with visual memory extending as far back as 1min. These limitations will only decrease with time.
Welcome to the future.🙌
deepmind.google/discover/blo...
Looking forward to attending CogSci this week! I'll be giving a talk (see below) at the Reasoning Across Minds and Machines workshop on Wednesday at 10:25 AM, and will be around most of the week — feel free to reach out if you'd like to meet up!

July 28, 2025 at 6:07 PM
Looking forward to attending CogSci this week! I'll be giving a talk (see below) at the Reasoning Across Minds and Machines workshop on Wednesday at 10:25 AM, and will be around most of the week — feel free to reach out if you'd like to meet up!
Reposted by Andrew Lampinen

This summer my lab's journal club somewhat unintentionally ended up reading papers on a theme of "more naturalistic computational neuroscience". I figured I'd share the list of papers here 🧵:
July 23, 2025 at 2:59 PM
This summer my lab's journal club somewhat unintentionally ended up reading papers on a theme of "more naturalistic computational neuroscience". I figured I'd share the list of papers here 🧵:
Reposted by Andrew Lampinen

Does vision training change how language is represented and used in meaningful ways?🤔The answer is a nuanced yes! Comparing VLM-LM minimal pairs, we find that while the taxonomic organization of the lexicon is similar, VLMs are better at _deploying_ this knowledge. [1/9]

July 22, 2025 at 4:46 AM
Does vision training change how language is represented and used in meaningful ways?🤔The answer is a nuanced yes! Comparing VLM-LM minimal pairs, we find that while the taxonomic organization of the lexicon is similar, VLMs are better at _deploying_ this knowledge. [1/9]
Quick thread on the recent IMO results and the relationship between symbol manipulation, reasoning, and intelligence in machines and humans:
July 21, 2025 at 10:20 PM
Quick thread on the recent IMO results and the relationship between symbol manipulation, reasoning, and intelligence in machines and humans:
Reposted by Andrew Lampinen

Excited to share a new project spanning cognitive science and AI where we develop a novel deep reinforcement learning model---Multitask Preplay---that explains how people generalize to new tasks that were previously accessible but unpursued.

July 12, 2025 at 4:20 PM
Excited to share a new project spanning cognitive science and AI where we develop a novel deep reinforcement learning model---Multitask Preplay---that explains how people generalize to new tasks that were previously accessible but unpursued.
Reposted by Andrew Lampinen

Exciting new preprint from the lab: “Adopting a human developmental visual diet yields robust, shape-based AI vision”. A most wonderful case where brain inspiration massively improved AI solutions.
Work with @zejinlu.bsky.social @sushrutthorat.bsky.social and Radek Cichy
arxiv.org/abs/2507.03168
Work with @zejinlu.bsky.social @sushrutthorat.bsky.social and Radek Cichy
arxiv.org/abs/2507.03168
arxiv.org
July 8, 2025 at 1:04 PM
Exciting new preprint from the lab: “Adopting a human developmental visual diet yields robust, shape-based AI vision”. A most wonderful case where brain inspiration massively improved AI solutions.
Work with @zejinlu.bsky.social @sushrutthorat.bsky.social and Radek Cichy
arxiv.org/abs/2507.03168
Work with @zejinlu.bsky.social @sushrutthorat.bsky.social and Radek Cichy
arxiv.org/abs/2507.03168
Reposted by Andrew Lampinen

Thrilled to see our TinyRNN paper in @nature! We show how tiny RNNs predict choices of individual subjects accurately while staying fully interpretable. This approach can transform how we model cognitive processes in both healthy and disordered decisions. doi.org/10.1038/s415...
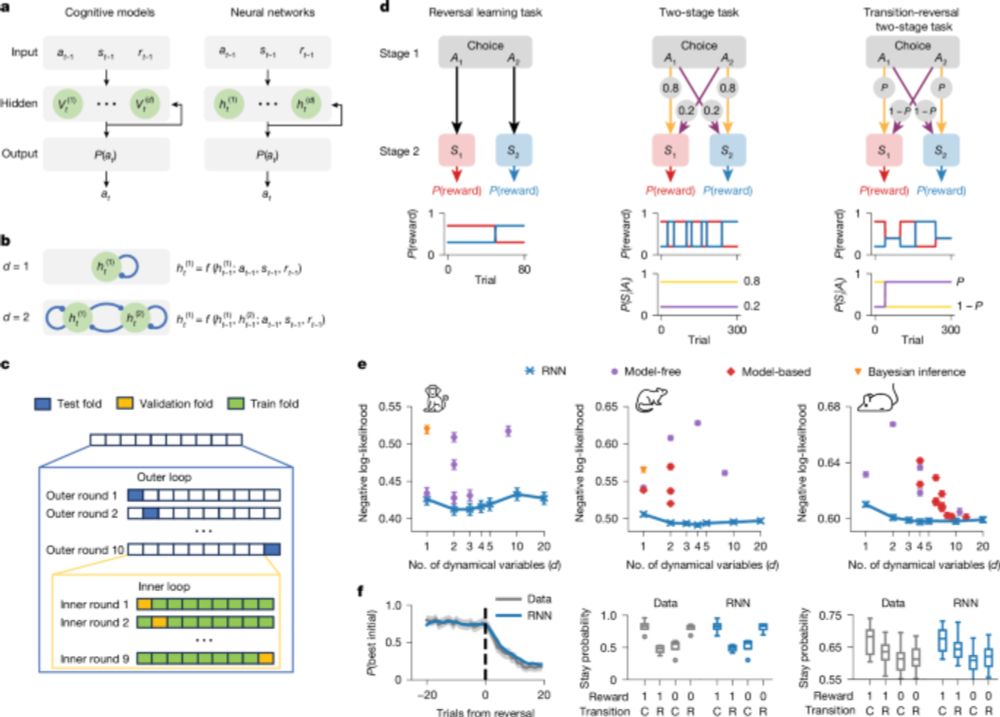
Discovering cognitive strategies with tiny recurrent neural networks - Nature
Modelling biological decision-making with tiny recurrent neural networks enables more accurate predictions of animal choices than classical cognitive models and offers insights into the underlying cog...
doi.org
July 2, 2025 at 7:03 PM
Thrilled to see our TinyRNN paper in @nature! We show how tiny RNNs predict choices of individual subjects accurately while staying fully interpretable. This approach can transform how we model cognitive processes in both healthy and disordered decisions. doi.org/10.1038/s415...
Reposted by Andrew Lampinen

Experimentology is out today!!! A group of us wrote a free online textbook for experimental methods, available at experimentology.io - the idea was to integrate open science into all aspects of the experimental workflow from planning to design, analysis, and writing.

July 1, 2025 at 6:26 PM
Experimentology is out today!!! A group of us wrote a free online textbook for experimental methods, available at experimentology.io - the idea was to integrate open science into all aspects of the experimental workflow from planning to design, analysis, and writing.
Really nice analysis!

🚨New paper! We know models learn distinct in-context learning strategies, but *why*? Why generalize instead of memorize to lower loss? And why is generalization transient?
Our work explains this & *predicts Transformer behavior throughout training* without its weights! 🧵
1/
Our work explains this & *predicts Transformer behavior throughout training* without its weights! 🧵
1/
June 28, 2025 at 8:03 AM
Really nice analysis!
Reposted by Andrew Lampinen

Humans and animals can rapidly learn in new environments. What computations support this? We study the mechanisms of in-context reinforcement learning in transformers, and propose how episodic memory can support rapid learning. Work w/ @kanakarajanphd.bsky.social : arxiv.org/abs/2506.19686

From memories to maps: Mechanisms of in context reinforcement learning in transformers
Humans and animals show remarkable learning efficiency, adapting to new environments with minimal experience. This capability is not well captured by standard reinforcement learning algorithms that re...
arxiv.org
June 26, 2025 at 7:01 PM
Humans and animals can rapidly learn in new environments. What computations support this? We study the mechanisms of in-context reinforcement learning in transformers, and propose how episodic memory can support rapid learning. Work w/ @kanakarajanphd.bsky.social : arxiv.org/abs/2506.19686
Reposted by Andrew Lampinen

I'm excited about this TICS Opinion with @yngwienielsen.bsky.social, challenging the view that structural priming—the tendency to reuse a recent syntactic structure—provides evidence for the psychological reality of grammar-based constituent structure.
authors.elsevier.com/a/1lIFK4sIRv...
🧵1/4
authors.elsevier.com/a/1lIFK4sIRv...
🧵1/4

June 25, 2025 at 5:46 PM
I'm excited about this TICS Opinion with @yngwienielsen.bsky.social, challenging the view that structural priming—the tendency to reuse a recent syntactic structure—provides evidence for the psychological reality of grammar-based constituent structure.
authors.elsevier.com/a/1lIFK4sIRv...
🧵1/4
authors.elsevier.com/a/1lIFK4sIRv...
🧵1/4