Posts
Media
Videos
Starter Packs


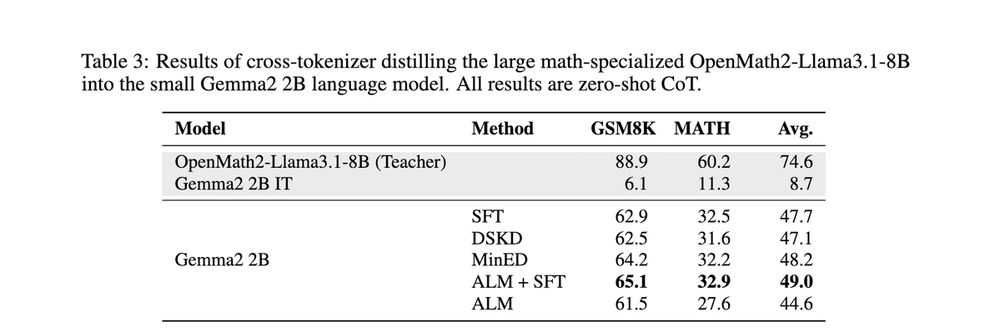
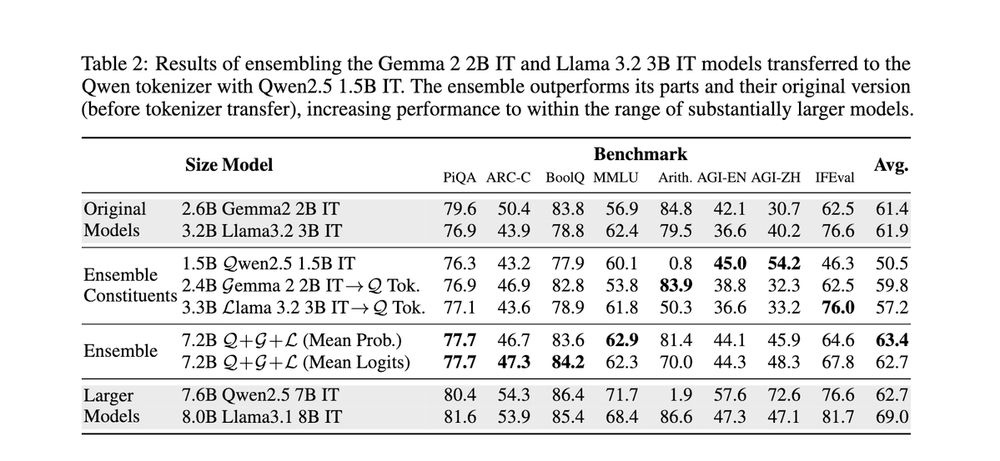

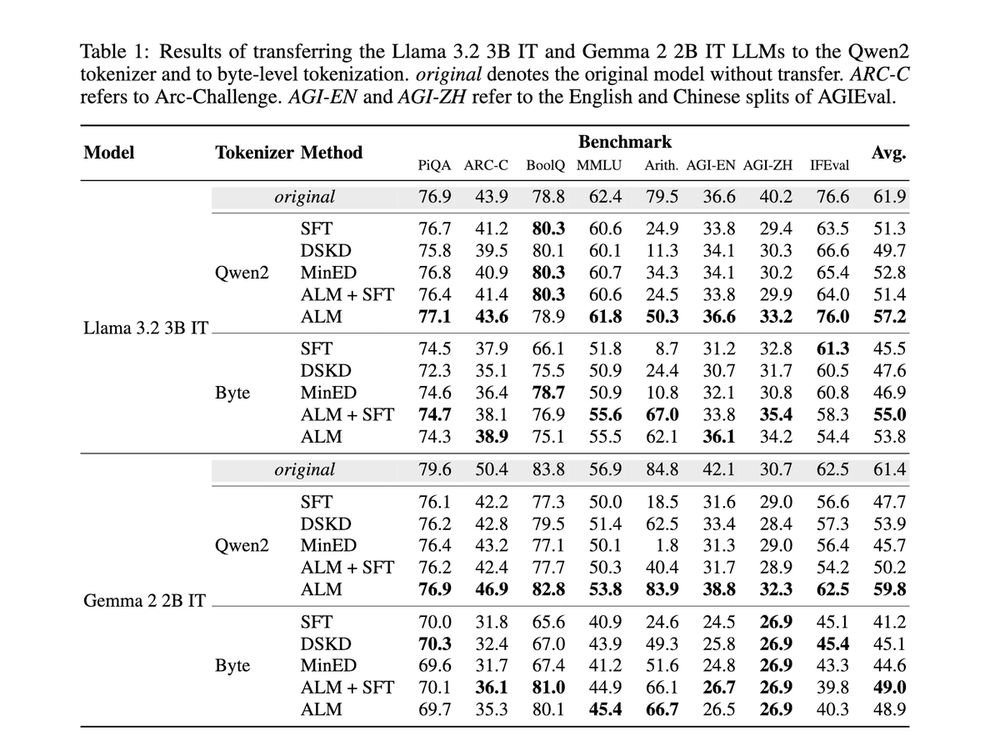
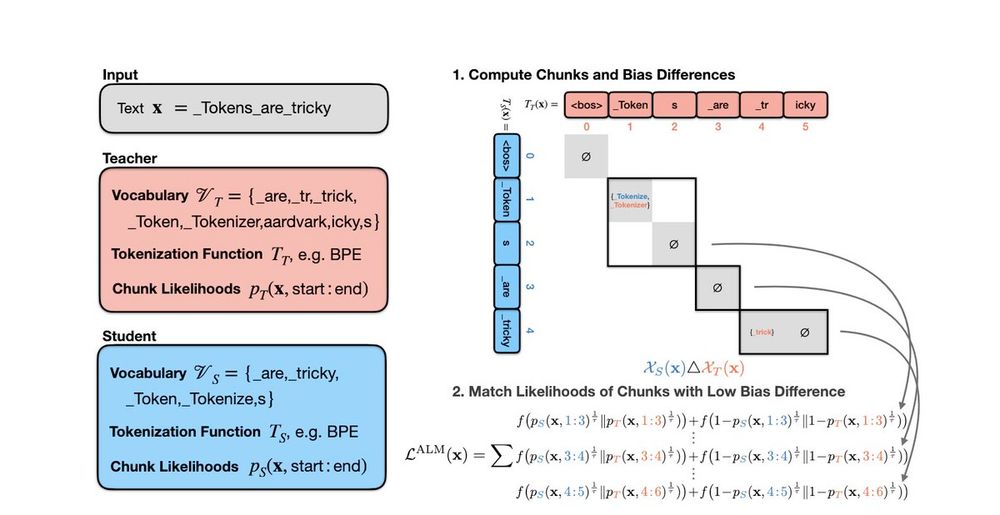

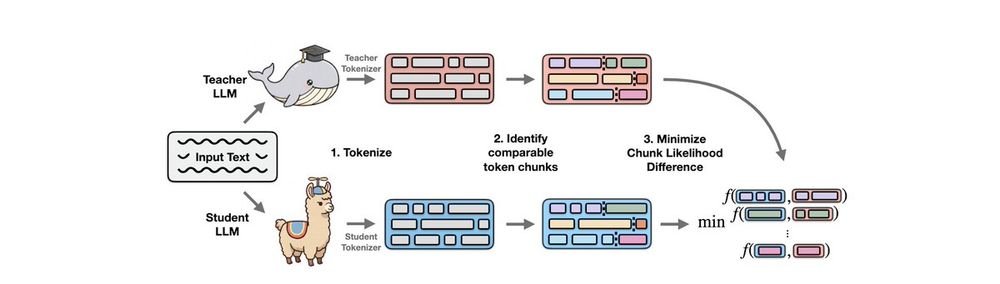
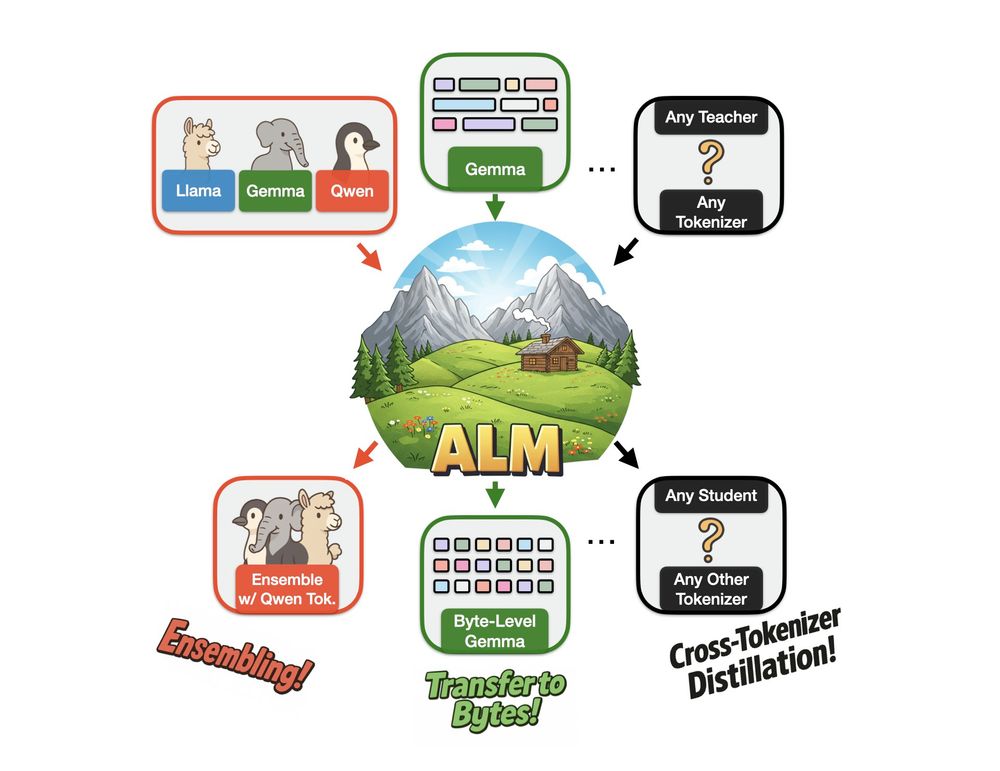
Reposted by Benjamin Minixhofer

Edoardo Ponti
@edoardo-ponti.bsky.social
· Dec 12