Carlo Sferrazza
@carlosferrazza.bsky.social
82 followers
60 following
33 posts
Postdoc at Berkeley AI Research. PhD from ETH Zurich.
Robotics, Artificial Intelligence, Humanoids, Tactile Sensing.
https://sferrazza.cc
Posts
Media
Videos
Starter Packs
Pinned

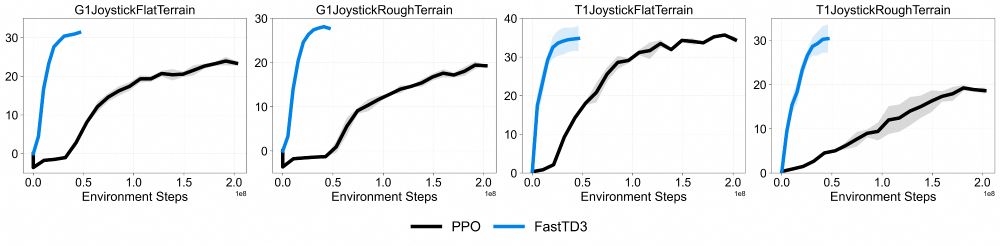






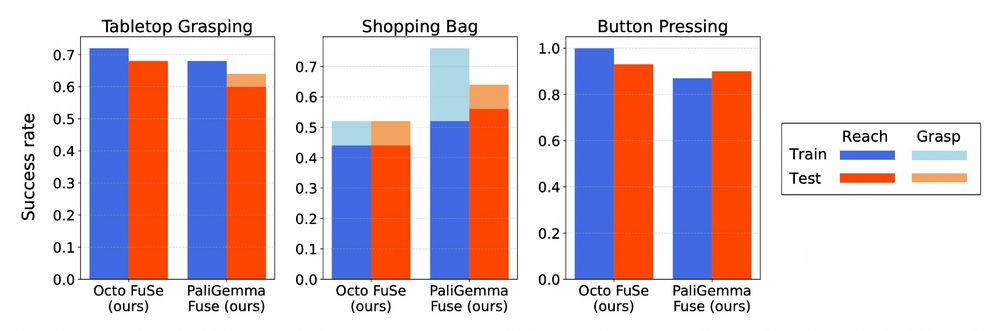
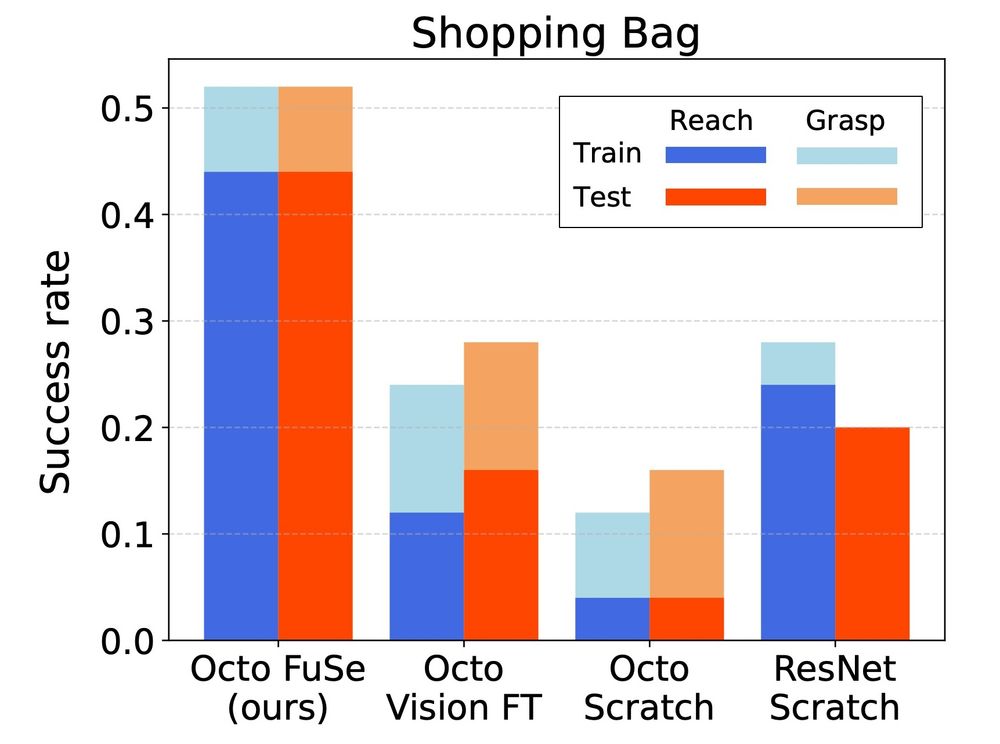
Reposted by Carlo Sferrazza

Bhavya Sukhija
@sukhijab.bsky.social
· Dec 17