
Volkan Cevher
@cevherlions.bsky.social
970 followers
100 following
12 posts
Associate Professor of Electrical Engineering, EPFL.
Amazon Scholar (AGI Foundations). IEEE Fellow. ELLIS Fellow.
Posts
Media
Videos
Starter Packs

Volkan Cevher
@cevherlions.bsky.social
· Feb 13
Reposted by Volkan Cevher


Volkan Cevher
@cevherlions.bsky.social
· Feb 13





Volkan Cevher
@cevherlions.bsky.social
· Feb 13




Reposted by Volkan Cevher


Reposted by Volkan Cevher

Wanyun Xie
@wanyunxie.bsky.social
· Dec 11
Reposted by Volkan Cevher

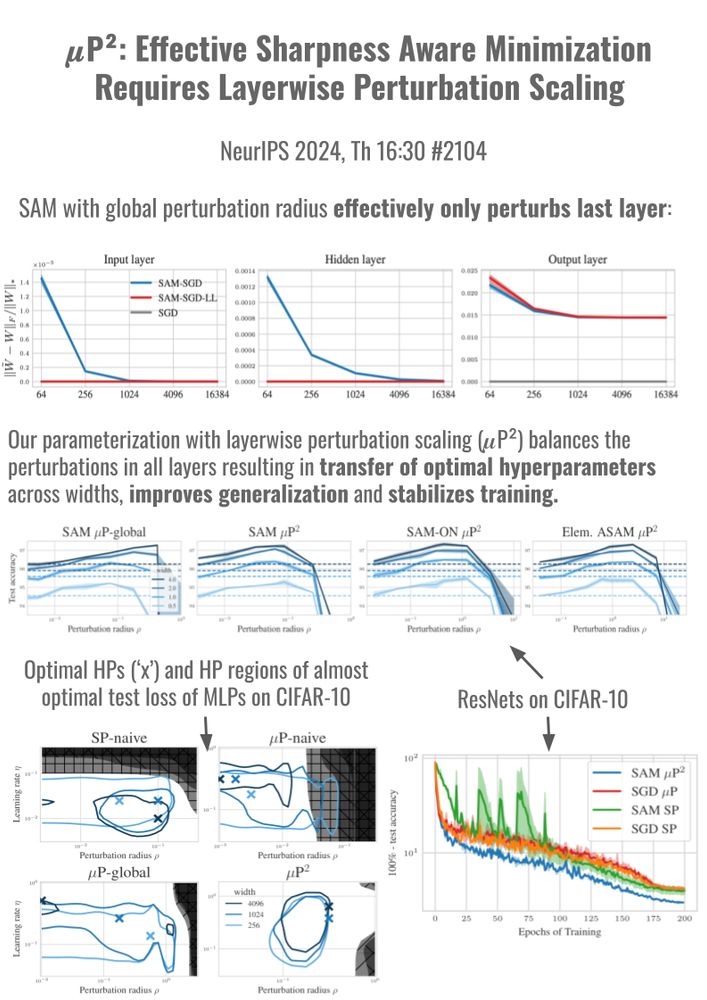
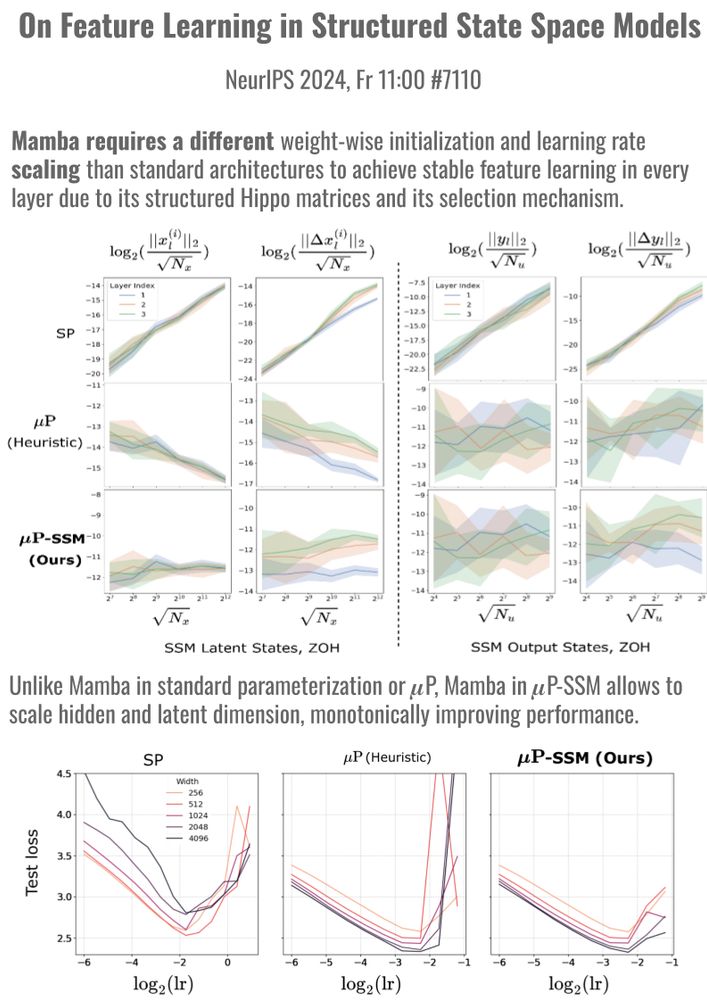
Reposted by Volkan Cevher

Reposted by Volkan Cevher

